在任何现代化软件组织的日常工作中,性能工程(Performance engineering)和压力测试(load testing)都是非常关键的组成部分。实际上,许多公司都会在此类团队的建设上日益增加投入。而那些缺乏此类流程的公司,也正在朝着该方向迅速改进中。
从理论上说:在关键性能指标(KPI,请参见:https://kpi.org/KPI-Basics)的驱动下,软件应用领域的性能工程和压力测试具有如下三个主要目标:
1. 验证应用程序的当前负载容量。
2. 识别应用代码、软件配置、以及硬件资源上的瓶颈限制。
3. 提高应用程序的可伸缩性,以满足目标负载能力。
具体来说,典型的压力测试会涉及如下六个方面:
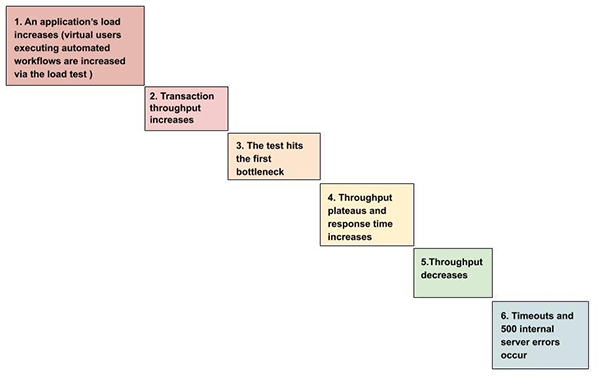
目前,虽然业界有着大量的相关测试工具,它们可以通过生成并非用户的访问负载,来进行性能测试,但是New Relic平台,特别是New Relic APM(https://newrelic.com/products/application-monitoring)、New Relic Infrastructure(https://newrelic.com/products/infrastructure)和New Relic Browser(https://newrelic.com/products/browser-monitoring)都提供了较为深入的监控与服务,以及各种关键性的洞见。New Relic能够分析浏览器的响应时间、用户的会话数、应用程序的运行速度、以及后端资源的利用率。根据New Relic所创建的压力测试环境,测试团队能够获悉有关应用性能的端到端“全景视图”。
本文将分为3部分、12个步骤,向您介绍在性能工程中,如何使用New Relic开展有序的压力测试,并进行规范性的根本原因分析。
第1部分:设置基线并确定当前容量?
我们的首要任务就是先构造压力测试,然后缓慢增加负载,直至应用程序出现瓶颈。
1.我们从最小用户数的负载开始(例如:5个用户的并发量),执行至少持续一小时的压力测试。我们将这种低负载测试的结果作为一个基线。
如果针对基线压力测试的结果,已经能够出现并发的事务超出了服务级别协议(SLA),那么我们就没有理由再进行下一步的可伸缩性测试了。而如果一切正常,我们则继续下一步。
2.通过基线压力测试的结果,您可以为应用设置可接受的Apdex分数(https://docs.newrelic.com/docs/apm/new-relic-apm/apdex/apdex-measure-user-satisfaction)。该Apdex是目标应用程序平均响应时间的标准。您需要为那些在执行时间上超过整体SLA的特定事务,创建关键事务(https://docs.newrelic.com/docs/apm/transactions/key-transactions/introduction-key-transactions)。例如,对于典型的Web应用而言,其Browser Apdex值应当为0.3秒。而Java应用程序的APM Apdex值则可能为0.5秒。如果您的应用程序有一个微服务集合,并通过API来处理事务,那么每个服务的Apdex则可能是0.2秒。因此,我们的宗旨是为每个执行事务的服务,设置适当的Adex值。
3.设计并执行压力测试,然后有条不紊地增加用户数量。请为每一个应用程序设计不同的吞吐量和用户负载目标。例如,您可以使用5个并发用户数来触发压力测试,接着每隔15秒钟再添加5个用户。随着用户数量的增加,压力测试将慢慢接近性能的临界点,这将使您能够了解到目标应用程序所能够处理负载的极限。
记住:压力测试应当被设计为有序进行,而不要一股脑地将目标工作负载抛给应用程序,否则得到的结果不但混乱、且难以解释。例如:如果您的目标是达到5,000个并发用户,那么您设计的压力测试应当先锚定该目标的一半。如果此应用能够成功地扩展到目标负载的一半,那么您才可以继续设计下一轮测试,以使负载加倍。同样,如果您测试的是负载吞吐量,而不是用户数与活动会话,那么您仍然可以使用相同的方法稳健地达到目标所设定的每秒事务数。例如,如果您的API吞吐量目标为每秒200个事务的话,那么您可以逐步将测试的压力扩展到每秒100个事务。
4.在应用程序的APM概览页面中,您可以通过更改视图,来查看“Web事务分位数(Web transactions percentiles)”。由于其中95%的记录都会比中位或平均值更加敏锐与精细,因此您可以将主要精力集中在这95%的记录行上。
通过观察,您可以找到目标应用在压力测试下开始出现服务质量下降的时间点,然后突出显示并放大该时间范围与跨度,以便您能够执行更为深入的分析。例如,您可以深入挖掘各种事务性、分布式的轨迹、以及相关的错误,或是从APM模式切换到Browser模式,以便从前端转为后端分析。New Relic能够持续地自动聚焦该时间范围内的各类信息。
记住:该测试部分的主要目标是首次识别瓶颈,因此您不需担心在首次拐点之后的图表走势。任何跨过该点的状态,都只是某个根本原因的后续症状而已。
第2部分:隔离首个瓶颈
针对上述发现的性能下降情况,您可以根据应用的实际情况,执行如下步骤5到9(可以不一定按照该顺序)以进行问题排查。例如,您可以从使用New Relic Browser去分析响应的时间开始,顺藤摸瓜,直到发现APM中的代码缺陷(也就是所谓的自上而下的方法)。当然,您也可以从New Relic Infrastructure开始,以识别那些导致浏览器响应耗时的资源限制(也就是所谓的自下而上的方法)。
5.利用在步骤4中所收集的信息,采用服务映射(service maps,https://docs.newrelic.com/docs/understand-dependencies/understand-system-dependencies/service-maps/introduction-service-maps)来识别到底是哪个应用事务的哪些内、外部服务水平出现了下降,并导致了总体响应时间的增加。
如果您发现有多个事务存在着服务水平的下降趋势,那么这通常表明有某些资源已经接近到了它们的饱和点。
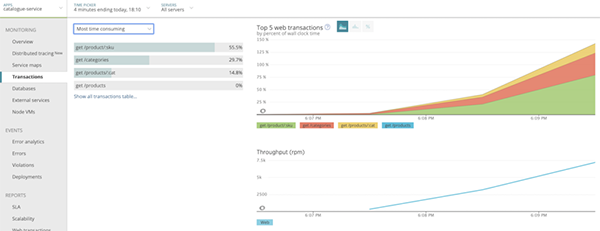
事务分析
6.使用New Relic APM来逐步隔离各种代码的缺陷、或是错误的条件。使用事务跟踪(transaction traces,https://docs.newrelic.com/docs/apm/transactions/transaction-traces/introduction-transaction-traces)的方法,来隔离服务降级、或是抛出错误的确切代码。
7.使用Infrastructure的主机集成(on-host integrations,https://docs.newrelic.com/docs/integrations/host-integrations/getting-started/introduction-host-integrations),来识别基础架构中诸如Web服务器、JVM或数据库等方面的限制。
8.使用Infrastructure来检查应用部署所涉及到的每一台主机和服务器,以查看是否有硬件资源(CPU、内存、以及网络等)被滥用的情况。
硬件资源不一定是在完全饱和时,才能导致响应时间的延长。有时候,达到70%的饱和度时,其性能就会受到影响。如果您在压力测试中发现瓶颈并非源自硬件资源,那么就请检查服务器的软件资源,其中包括:连接池、数据源连接数、及其TCP堆栈等方面。因为当软件资源饱和时,它们同样会在基础架构中出现“排队”的状况。
9.使用Browser来确定响应时间的增加是否来自应用的前端。例如,当您的站点需要呈现某些HTML类资产时,那些向第三方远程服务器发送的Ajax请求数,就有可能会导致整体速度的下降。
第3部分:优化以缓解瓶颈问题
在确定了瓶颈的原因之后,您需要通过实施变更,来应对新的压力测试。
10.对于应用程序的任何变更,您都需要设置New Relic的部署标记(deployment marker,https://docs.newrelic.com/docs/apm/new-relic-apm/maintenance/record-deployments)来予以记录。您可以使用诸如:“向VM增加了2颗CPU”之类详细信息,来标记针对某次变更的部署。
记住:一次仅修改一个变量。如果您一次性地修改了两个、或更多的内容(例如,增加了多个硬件资源、并让JVM堆栈的大小翻倍了),那么您将无从知晓到底是哪个变量,如何影响了应用程序的总体负载性能。
11.重新运行压力测试并分析新的结果,以判断性能是否有所改观。如果没有任何差异的话,那就意味着您并未找到真正的瓶颈。请保留或还原先前的变更,并按需重复前面的测试步骤。
12.持续进行压力测试,直至真正消除了瓶颈,并满足了既定的各项负载需求。
使性能工程成为一个迭代的过程
客观地说,压力测试和性能工程是“永无止境”的。由于从应用程序的工作负载、到功能服务、再到体系架构中的几乎每个组件,我们都需要对它们进行持续的开发与部署,因此就算是某个新增的简单变更,也可能会对前期的性能测试结果带来干扰。所以说,性能测试应当随着应用程序的迭代而继续。
其他的压力测试和性能分析资源
下面是一些您可能在压力测试和性能分析中用得上的,其他类型的New Relic工具:
- 服务映射(https://docs.newrelic.com/docs/understand-dependencies/understand-system-dependencies/service-maps/introduction-service-maps):在应用程序的部署过程中,可用于识别服务之间的连接、以及上/下游的依赖关系。
- 分布式跟踪(https://docs.newrelic.com/docs/apm/distributed-tracing/getting-started/introduction-distributed-tracing):方便用户清楚地获悉应用程序中不同事务的横向服务。
- 仪表板(https://docs.newrelic.com/docs/dashboards/new-relic-one-dashboards/get-started/introduction-new-relic-one-dashboards):在压力测试期间,通过灵活的交互方式,可视化地跟踪那些用户感兴趣的KPI。
原文标题:How to Use New Relic for Performance Engineering and Load Testing ,作者:Rebecca Clinard

