内存泄漏
虽然解决了core dump,但是另外一个问题又浮出了水面,就是高并发测试时,会出现内存泄漏,大概一个小时500M的样子。
valgrind的缺点
出现内存泄漏或者内存问题,大家第一时间都会想到valgrind。valgrind是一款非常优秀的软件,不需要重新编译程序就能够直接测试。功能也非常强大,能够检测常见的内存错误包括内存初始化、越界访问、内存溢出、free错误等都能够检测出来。推荐大家使用。
valgrind 运行的基本原理是:待测程序运行在valgrind提供的模拟CPU上,valgrind会纪录内存访问及计算值,最后进行比较和错误输出。我通过valgrind测试nginx也发现了一些内存方面的错误,简单分享下valgrind测试nginx的经验:
1.nginx通常都是使用master fork子进程的方式运行,使用–trace-children=yes来追踪子进程的信息。
2.测试nginx + openssl时,在使用rand函数的地方会提示很多内存错误。比如Conditional jump or move depends on uninitialised value,Uninitialised value was created by a heap allocation等。这是由于rand数据需要一些熵,未初始化是正常的。如果需要去掉valgrind提示错误,编译时需要加一个选项:-DPURIFY。
3.如果nginx进程较多,比如超过4个时,会导致valgrind的错误日志打印混乱,尽量减小nginx工作进程,保持为1个。因为一般的内存错误其实和进程数目都是没有关系的。
上面说了valgrind的功能和使用经验,但是valgrind也有一个非常大的缺点,就是它会显著降低程序的性能,官方文档说使用memcheck工具时,降低10-50倍。也就是说,如果nginx完全握手性能是20000 qps,那么使用valgrind测试,性能就只有400 qps左右。对于一般的内存问题,降低性能没啥影响,但是我这次的内存泄漏是在大压力测试时才可能遇到的,如果性能降低这么明显,内存泄漏的错误根本检测不出来。只能再考虑其他办法了。
AddressSanitizer的优点
address sanitizer(简称asan)是一个用来检测c/c++程序的快速内存检测工具。相比valgrind的优点就是速度快,官方文档介绍对程序性能的降低只有2倍。对Asan原理有兴趣的同学可以参考asan的算法这篇文章,它的实现原理就是在程序代码中插入一些自定义代码,如下:
编译前:
*address = ...; // or: ... = *address; f
编译后:
if (IsPoisoned(address)) {
ReportError(address, kAccessSize, kIsWrite);
}
*address = ...; // or: ... = *address;
和valgrind明显不同的是,asan需要添加编译开关重新编译程序,好在不需要自己修改代码。而valgrind不需要编程程序就能直接运行。address sanitizer集成在了clang编译器中,GCC 4.8版本以上才支持。我们线上程序使用的gcc版本较低,于是我测试时直接使用clang重新编译nginx:
—with-cc=”clang” \
—with-cc-opt=”-g -fPIC -fsanitize=address -fno-omit-frame-pointer”
其中with-cc是指定编译器,with-cc-opt指定编译选项, -fsanitize=address就是开启AddressSanitizer功能。
由于AddressSanitizer对nginx的影响较小,所以大压力测试时也能达到上万的并发,内存泄漏的问题很容易就定位了。这里就不详细介绍内存泄漏的原因了,因为跟openssl的错误处理逻辑有关,是我自己实现的,没有普遍的参考意义。最重要的是,知道valgrind和asan的使用场景和方法,遇到内存方面的问题能够快速修复。
性能热点分析
到此,经过改造的nginx程序没有core dump和内存泄漏方面的风险了。但这显然不是我们最关心的结果(因为代码本该如此),我们最关心的问题是:
1.代码优化前,程序的瓶颈在哪里?能够优化到什么程度?
2.代码优化后,优化是否彻底?会出现哪些新的性能热点和瓶颈?
这个时候我们就需要一些工具来检测程序的性能热点。
性能分析工具
linux世界有许多非常好用的性能分析工具,我挑选几款最常用的简单介绍下:
1.perf应该是最全面最方便的一个性能检测工具。由linux内核携带并且同步更新,基本能满足日常使用。推荐大家使用。
2.oprofile,我觉得是一个较过时的性能检测工具了,基本被perf取代,命令使用起来也不太方便。比如opcontrol —no-vmlinux , opcontrol —init等命令启动,然后是opcontrol —start, opcontrol —dump, opcontrol -h停止,opreport查看结果等,一大串命令和参数。有时候使用还容易忘记初始化,数据就是空的。
3.gprof主要是针对应用层程序的性能分析工具,缺点是需要重新编译程序,而且对程序性能有一些影响。不支持内核层面的一些统计,优点就是应用层的函数性能统计比较精细,接近我们对日常性能的理解,比如各个函数时间的运行时间,,函数的调用次数等,很人性易读。
4.systemtap 其实是一个运行时程序或者系统信息采集框架,主要用于动态追踪,当然也能用做性能分析,功能最强大,同时使用也相对复杂。不是一个简单的工具,可以说是一门动态追踪语言。如果程序出现非常麻烦的性能问题时,推荐使用 systemtap。
这里再多介绍一下perf命令,tlinux系统上默认都有安装,比如通过perf top就能列举出当前系统或者进程的热点事件,函数的排序。perf record能够纪录和保存系统或者进程的性能事件,用于后面的分析,比如接下去要介绍的火焰图。
火焰图 flame graph
perf有一个缺点就是不直观。火焰图就是为了解决这个问题。它能够以矢量图形化的方式显示事件热点及函数调用关系。比如我通过如下几条命令就能绘制出原生nginx在ecdhe_rsa cipher suite下的性能热点:
1.perf record -F 99 -p PID -g — sleep 10
2.perf script | ./stackcollapse-perf.pl > out.perf-folded
3../flamegraph.pl out.perf-folded>ou.svg

直接通过火焰图就能看到各个函数占用的百分比,比如上图就能清楚地知道rsaz_1024_mul_avx2和rsaz_1024_sqr_avx2函数占用了75%的采样比例。那我们要优化的对象也就非常清楚了,能不能避免这两个函数的计算?或者使用非本地CPU方案实现它们的计算?
当然是可以的,我们的异步代理计算方案正是为了解决这个问题。
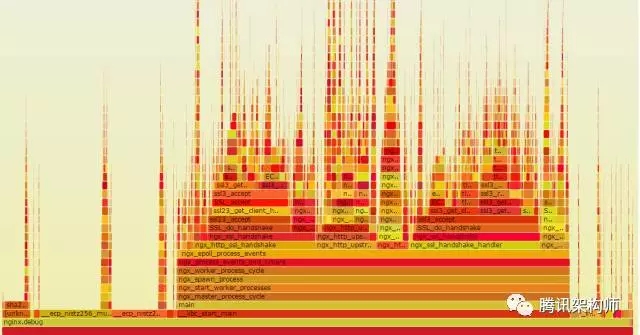
从上图可以看出,热点事件里已经没有RSA相关的计算了。至于是如何做到的,后面有时间再写专门的文章来分享。
心态
为了解决上面提到的core dump和内存泄漏问题,花了大概三周左右时间。基本上4月份对我来说就是黑色的,压力很大,精神高度紧张,感觉有些狼狈,看似几个很简单的问题,搞了几周时间。心里当然不是很爽,会有些着急,特别是项目的关键上线期。但即使这样,整个过程我还是非常自信并且斗志昂扬。我一直在告诉自己:
1.调试BUG是一次非常难得的学习机会,不要把它看成是负担。不管是线上还是线下,能够主动地,高效地追查BUG特别是有难度的BUG,对自己来说一次非常宝贵的学习机会。面对这么好的学习机会,自然要充满热情,要如饥似渴,回首一看,如果不是因为这个BUG,我也不会对一些工具有更深入地了解和使用,也就不会有这篇文档的产生。
2.不管什么样的BUG,随着时间的推移,肯定是能够解决的。这样想想,其实会轻松很多,特别是接手新项目,改造复杂工程时,由于对代码,对业务一开始并不是很熟悉,需要一个过渡期。但关键是,你要把这些问题放在心上。白天上班有很多事情干扰,上下班路上,晚上睡觉前,大脑反而会更加清醒,思路也会更加清晰。特别是白天上班时容易思维定势,陷入一个长时间的误区,在那里调试了半天,结果大脑一片混沌。睡觉前或者上下班路上一个人时,反而能想出一些新的思路和办法。
3.开放地讨论。遇到问题不要不好意思,不管多简单,多低级,只要这个问题不是你google一下就能得到的结论,大胆地,认真地和组内同事讨论。

