一、性能测试监控思路
(1)首先是判断是否出现性能瓶颈,结合部署架构猜测瓶颈出现哪一段。
(2)查看日志、使用监控工具或者其他方式来印证你的猜测。
(3)查看操作系统的参数,通过多方数据确认,证明现象的合理性。
(4)系统调优,再次测试确定调优效果。
二、说了那么多,找个实例来看。
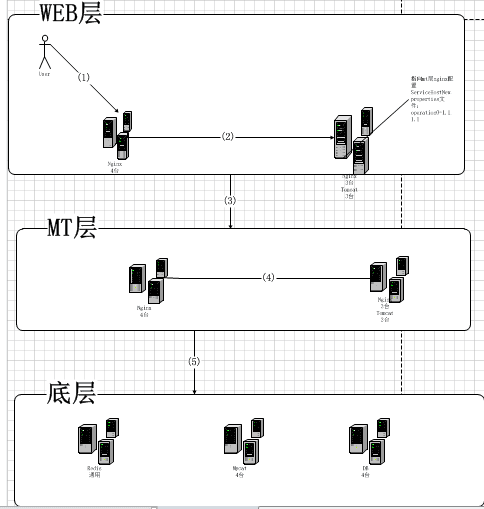
先部署环境画个部署架构
典型的三层结构:web层是nginx+tomcat(放的是api的包);mt层的nginx+tomcat(就是rpc或者服务治理的包,dao方法都在mt层的tomcat里)
省去中间的程序直接压测,发现并发量20的时候响应时间是100ms,并发量30的时候响应时间是150ms。
tps不变了,出现了系统瓶颈。
(2)查看系统参数,缩小范围。
<1>系统瓶颈一般就是网络、操作系统、中间件、技术架构、应用、io等。首先看下sar -A过一下基本参数,看看有什么异常。
------ 结果发现是没有什么异常,所以怀疑到前端的网络和中间件,比如mycat。
<2>看代码了解到我的方法是web层一个api的service调用了2个mt层的service(mt层用到了2个dao的4个sql),所以我倾向于mycat+mysql这段存在瓶颈。但是操作系统没有io瓶颈,这就尴尬了,那我把3个服务都打个消耗时间的日志看看。
------打印结果发现请求的消耗时间确实在web层的api和mt层的一个dao里面。这样就能排除掉网络、nginx的问题(或者说从发请求到tomcat的这个过程是没有问题的)
<3>既然已经快速的缩小范围了,问题就比较好排查了,理应怀疑sql执行效率,但是别忘了系统io执行效率并不高,那我就认为dao的代码写的有问题。
(3)分析问题,证明操作系统的数据合理性
其实定位到这个范围基本已经能猜到一些可能性了:数据库连接数、tomcat连接数、dao层是否有一些等待逻辑、锁等待、包括容器的内存是不是溢出了,我们现在先不扩展。
我把dao的问题叫开发定位了一下,反馈给我说有2个sql在业务上就不需要,另外发现多次调用dao的逻辑,那么就定位到数据库的连接数了。
----------印证了系统的监控现象,io利用率低。
(4)在下一个版本再次回归。
补充点知识:一个请求的消耗时间是多个节点(网络、系统、nginx、tomcat...)的消耗时间之和,所以我们的定位思路就要分段拆分、判断缩小瓶颈的发生范围。
打印日志也是有技巧的,我会在报文里传入一个id作为整个会话的标识,并且把这个id传入到他的子服务中去,这样就能精确算出每个方法的消耗时间。
总结:性能测试主要目标就是快速定位到工程级的问题并解决回归的过程。用什么方法、工具 都不重要。
说个题外话随着各种技术和框架的发展,以及各种监控工具的完善,性能测试这个行为变得越来越简单和容易,假设我使用pinpoint监控可以实时看到每个方法的消耗时间,可能上述的1~3步可以秒定位到,那么借助工具提升工作效率,同时印证自己的思路是好事。
(我们经常开玩笑说性能测试可以申遗了,境遇很像传统手工业)
但是基础薄弱的同学,我建议还是少依赖工具,不要迷失于工具的使用者这个层面了,而且由于不了解原理你会遇到很多问题没办法解决。所以我们的定位是问题的终结者,而不是发现者。

