一、 性能测试术语解释
1. 响应时间
响应时间即从应用系统发出请求开始,到客户端接收到最后一个字节数据为止所消耗的时间。响应时间按软件的特点再可以细分,如对于一个 C/S 软件的响应时间可以细分为网络传输时间、应用服务器处理时间、数据库服务器处理时间。另外客户端自身也存在着解析时间、界面绘制呈现时间等。
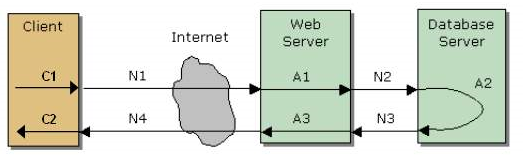
响应时间主要站在客户端角度来看的一个性能指标,它是用户最关心、并且容易感知到的一个性能指标。
2. 吞吐率
吞吐率指单位时间内系统处理用户的请求数,从业务角度看,吞吐率可以用每秒请求数、每秒事务数、每秒页面数、每秒查询数等单位来衡量。从网络角度看,吞吐率也可以用每秒字节数来衡量。
吞吐率主要站在服务端的角度来看的一个性能指标,它可以衡量整个系统的处理能力。对于集群或者云平台来说,吞吐率指标反映的是服务器集群对外整体能够承受的压力,该指标比用户数更容易对比。
备注:吞吐量 = 吞吐率 * 单位时间
3. 用户数
对于服务器集群或者云平台,几乎都是多用户系统,系统能提供给多少用户正常使用,也是一个非常重要的度量指标。我们把这些用户按照使用系统的时机不同,做如下区分。
系统用户数(System Users):指系统能够存储的用户量。
在线用户数(Online Users):指用户通过身份确认后,处于能正常使用状态的用户个数。
并发用户数(Concurrent users):指在某个时间范围内,同时正在使用系统的用户个数。
严格并发用户数(Strictly the number of concurrent users):指同一时刻都操作某个业务的用户数。
在性能测试过程中,我们要去模拟实际用户来发请求。但是为了吐服务器产生更大的压力,我们模拟的用户操作和实际的用户操作存在一定的差异(比如模拟的用户请求比实际用户的请求更频繁),而且返种模拟的用户数和实际的用户数也难以相互换算。所以在度量服务器集群能力时,吞吐率指标比用户数指标更实用。
二、 性能测试方法及目标
1. 性能测试方法
1.1 基准测试(Benchmark Testing)
基准测试是基于一定规模的数据量上进行单业务或按实际用户操作同比例组合业务的测试,目的在于量化响应时间、吞吐率的指标,便于后续比对。
方法是做多组不同场景的测试,观察结果,抽取出几个关键数据做好记彔,用于以后进行性能对比和评价。
1.2 性能测试(Performance Testing)
通过模拟生产运行的业务压力量和使用场景组合,测试系统的性能是否满足生产性能要求。
特点:
(1) 主要目的是验证系统是否具有系统宣称的能力。
(2) 需要事先了解被测系统的典型场景,并具有确定的性能目标。
(3) 要求在已确定的环境下运行。
1.3 负载测试(Load Testing)
通过在被测系统上不断增加压力,直到性能指标,例如“响应时间”超过预定指标或者某种资源使用已经达到饱和状态。
特点:
(1) 主要目的是找到系统处理能力的极限。
(2) 需要在给定的测试环境下进行,通常也需要考虑被测系统的业务压力量和典型场景,使得测试结果具有业务上的意义。
(3) 一般用来了解系统的性能容量,或是配合性能调优使用。
1.4 压力测试(Stress Testing)
测试系统在一定饱和状态下,例如CPU、内存等在饱和使用情况下,系统能够处理的会话能力,以及系统是否会出现错误。
特点:
(1) 主要目的是检查系统处于压力情况下是应用的表现。
(2) 一般通过模拟负载等方法,使得系统的资源使用达到较高水平。
(3) 一般用于测试系统的稳定性。
1.5 配置测试(Configuration Testing)
通过对被测系统的软/硬件环境的调整,了解各种不同环境对系统性能影响的程度,从而找到系统各项资源的最优分配原则。
特点:
(1) 主要目的是了解各种不同因素对系统性能影响的程度,从而判断出最值得进行得调优操作。
(2) 一般在对系统性能状况有初步了解后进行。
(3) 一般用于性能调优和规划能力。
1.6 并发测试(Concurrency Testing)
通过模拟用户的并发访问,测试多用户并发访问同一个应用、同一个模块或者数据记录时是否存在死锁或者其他性能问题。
特点:
(1) 主要目的是发现系统中可能隐藏的并发访问时的问题。
(2) 主要关注系统可能存在的并发问题,例如系统中的内存泄露、线程锁和资源争用方面的问题。
(3) 可在在开发的各个阶段使用,需要相关的测试工具的配合和支持。
1.7 可靠性测试(Reliability Testing)
通过给系统加载一定的业务压力(例如资源在70%~90%的使用率)的情况下,让应用持续运行一段时间,测试系统在这种条件下是否能稳定运行。
特点:
(1) 主要目的是验证系统是否支持长期稳定的运行。
(2) 需要在压力下持续一段时间的运行。
(3) 需要关注系统的运行状况。
1.8 失效恢复测试(Failover Testing)
针对有冗余备份和负载均衡的系统设计的,可以用来检验如果系统局部发生故障,用户是否能够继续使用系统;以及如果这种情况发生,用户将受到多大程度的影响。
特点:
(1) 主要目的是验证在局部故障情况下,系统能否继续使用。
(2) 还需要指出,当问题发生时“能支持多少用户访问”的结论和“采取何种应急措施”的方案。
(3) 一般来说,只有对系统持续运行指标有明确要求的系统才需要进行这种类型的测试。
2. 性能测试目标
概况来说,可分为4个方面:
2.1 能力验证
在系统测试或验收测试时,我们需要评估系统的能力,衡量系统的性能指标。系统的能力可以是容纳的并发用户数,也可能是系统的吞吐率;系统的性能指标可以是响应时间,也可以选择 CPU、内存、磁盘、网络的使用情况。
特点:
(1) 要求在已确定的环境下进行。
(2) 需要根据典型场景设计测试方案和用例。
一般采用的方法是:性能测试、压力测试、可靠性测试、失效恢复测试。
2.2 能力规划
评估某系统能否支持未来一段时间内的用户增长或是应该如何调整系统配置,使得系统能够满足增长的用户数的需要。
特点:
(1) 属于一种探索性的测试
(2) 可被用来了解系统的性能以及获得扩展性能的方法,例如系统扩容规划。系统容量可以是用户容量,也可能是数据容量,或者是系统的吞吐量(系统的处理能力)。对于集群服务我们更多的是用吞吐率作为容量。
方法是①先对各子系统、组件进行性能测试,找出它们之间的最优配比;②然后再通过各环节的水平扩展,计算出整体的扩容机器配比。
一般采用的方法是:负载测试、压力测试、配置测试。
2.3 性能调优
为了更好的发挥系统的潜能,定位系统的瓶颈,有针对性的进行系统优化。
方法是在进行系统调优时,我们需要做好基准测试,用以对比性能数据的变化,并反复调整系统软硬件的设置,以使系统发挥最优性能。当然在进行系统优化时,我们会选取关键的指标进行优化,返时可能要牺牲其他的性能指标。如目标是优化响应时间,我们可能选取的策略是以空间换时间,以牺牲内存或扩大缓存为代价,还需要我们在各个性能指标中找到平衡点。
一般对系统的调整包括以下3个方面:
(1) 硬件环境的调整
(2) 系统设置的调整
(3) 应用级别的调整
一般采用的方法是:基准测试、负载测试、压力测试、配置测试和失效恢复测试。
2.4 发现缺陷
和其他测试一样,性能测试也可以发现缺陷。特别是严格并发访问时是否存在资源争夺导致的响应时间过慢,或大量用户访问时是否导致程序崩溃。
方法是设置集合点,实现严格并发用户访问;或者设置超大规模用户突发访问等这样的性能测试用例进行测试。
一般采用的方法是:并发测试。
三、 性能需求分析
1. 性能需求获取
1.1 功能规格说明书
1.2 系统设计文档
1.3 运营计划
1.4 用户行为分析记录
2. 性能关键点选取
主要从以下4个维度进行选取:
2.1 业务分析
确定被测接口是否属于关键业务接口或先分析出关键业务以间接获取该业务所访问的接口。
2.2 统计分析
若接口系统访问行为存在日志分析记录,则直接获取日访问量高的接口;否则根据接口发布类型,选择第3方日志分析工具间接获取。
(1) IIS日志分析工具:Log Parser 2.2 + Log Parser Lizard GUI
下载地址:http://www.lizard-labs.com/log_parser_lizard.aspx
(2) Tomcat日志分析工具:AWStats v7.3
下载地址:http://www.awstats.org
(3) Nginx日志分析工具:GoAccess v0.9
若IIS或Tomcat等接口应用服务器使用Nginx进行负载,则日志访问量要以负载为准,因避免接口在Nginx设置缓存(即未进行透传)而导致统计不正确。
下载地址:http://www.goaccess.io
2.3 技术分析
(1) 逻辑实现复杂度高的接口(如判断分支过多或涉及CPU/IO密集型运算等)
(2) 对系统(内存、CPU、磁盘IO)及网络IO等硬件资源耗用高的接口
备注:若接口因逻辑修改而重构,则需重新分析。
2.4 运营分析
由于运营推广活动导致日访问突增高的接口。
备注:若运营计划调整,则需重新分析。
3. 性能指标描述
3.1 响应时间
在一般情况下,弱交互类接口平均响应时间不超过1秒,强交互类接口平均响应时间不超过200毫秒。
3.2 成功率
在一般情况下,接口响应成功率需达到99.99%以上。
3.3 系统资源
若为最佳负载,则系统CPU及内存使用率建议区间[50%,80%],否则建议不超过50%。
3.4 处理能力
立项申请书明确要求:在XX压力下(并发数)TPS需达到XX或 接口系统可支撑XX万实时在线访问。
3.5 稳定性
在实际系统运行压力情况下,可稳定运行N*24(一般 N >= 7 )小时。 在高于实际系统运行压力1倍的情况下,可稳定运行12小时。
3.6 特性指标
例:Java类应用 FullGC 次数 <= 1次/天
四、 性能测试范围
1. 业务范围
关键业务功能点描述。
2. 设计范围
网络接入层、接口层、中间件、存储层等被测组件及拓扑结构描述。
五、 并发数计算方法
做过一些性能测试的童鞋刚开始比较纠结某个或某一类接口的并发数如何计算,其实并发数可以从用户业务和服务器的2个角度来看。
1. 80/X原则
适用范围:无限制
以一项目为案例,母亲节当天接口服务器访问量分布如下所示,如何计算当天平均并发数和高峰并发数?
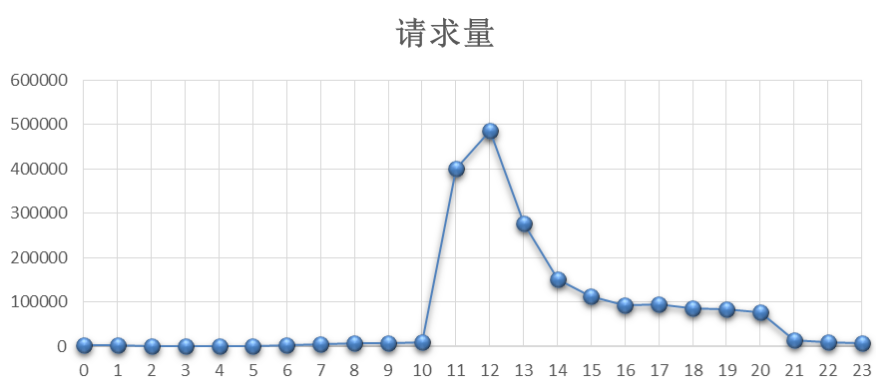
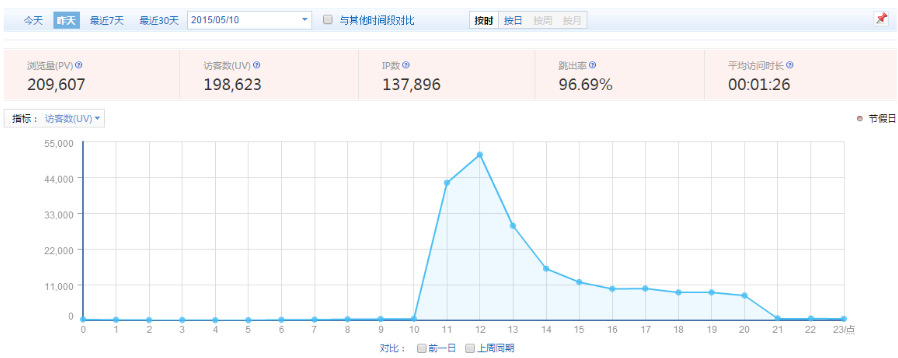
查看母亲节当天UV曲线分布 与 请求量呈线性关系,如下所示:
采用微积分的思想,将每个时间点视为一个矩形,可以通过求和的方式求出整个分布图的面积,如下所示:
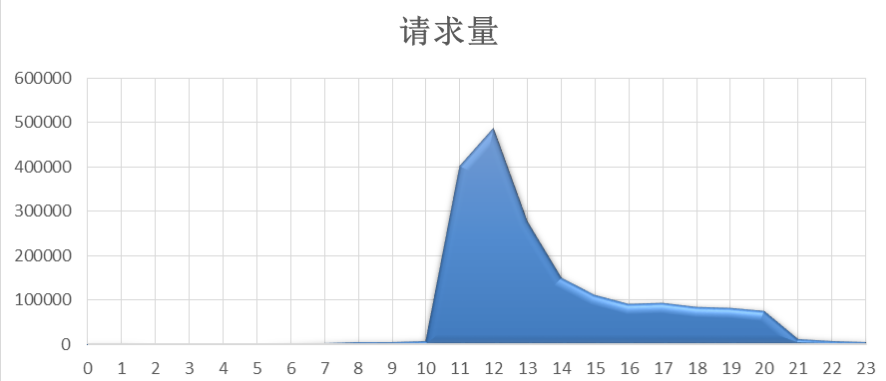
其实每个矩形的长度均为1(1小时),故求面积时只需考虑宽度,即考虑每小时请求量即可。
根据80/X原则,找出占据总体面积80%的时间,选择尽可能大的点计算出占据总体面积80%的时间,发现点的个数是7,意味着此时间长度占总时间长度30%,则80/X原则转换成80/30原则,如下所示:
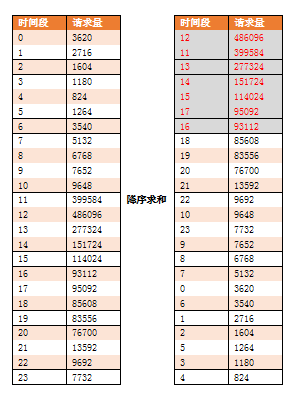
故,平均并发数(每秒平均请求数)= 80% * 日请求量 / 1天 * 30%
进而计算出最高峰值与平均并发数的倍数 = 2.25
故,高峰并发数(每秒高峰请求数)= 2.25 * 平均并发数 =
2.25 * 80% * 日请求量 / 1天 * 30% = 6 * 日请求量 / 1天
因UV与请求量曲线分布呈线性关系,日请求量 = 9.25 * 日UV
故,高峰并发数 = 6 * 9.25 * 日UV / 1天 = 55.5 * 日UV / 1天
2. 公式法
适用范围:Web类访问
公式(1)计算平均并发用户数:C = n * L / T
C是平均的并发用户数;n是login session的数量;L是login session的平均长度;T指考察的时间段长度。
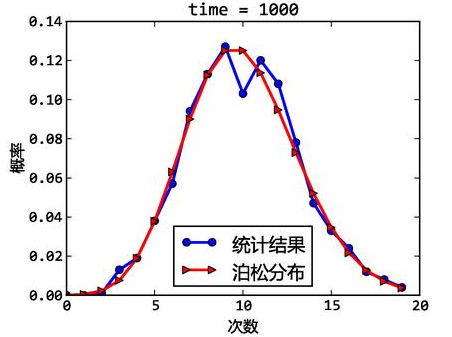
公式(2)计算并发用户数峰值: C’≈ C+3根号C
C’指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。该公式的得出是假设用户的login session产生符合泊松分布而估算得到的。
例1:
假设有一个OA系统,该系统有3000个用户,平均每天大约有400个用户要访问该系统,对一个典型用户来说,一天之内用户从登录到退出该系统的平均时间为4小时,在一天的时间内,用户只在8小时内使用该系统。
C = 400 * 4 / 8 = 200
C’≈ 200 + 3 * 根号200 = 242
为了更好地理解上述公式,将其转换为如下公式:
公式(3)并发用户数 = 吞吐率 * 场景业务时间 / 单位时间段
例2:
一个OA系统,1小时内有8000用户登录系统。用户每次登录系统,需启动登录页面,然后输入用户名和密码,进入首页。一般情况下,用户在上述操作过程中需耗时5秒,且要求从点击登录按钮到首页完全展现,需控制在5秒内。
分析:
吞吐率 = 8000 * 2(整个业务操作需加载2次页面才能完成)
场景业务时间 = 5 + 5 = 10 秒
单位时间段 = 1小时 = 3600 秒
并发用户数(登录场景) = (8000 * 2)* 10 / 3600 = 45
通过以上方法得到业务并发数后,我们可以进一步分析业务访问了哪些接口,我们只要模拟这些接口调用方式和调用时序就行了。
有时我们需要计算某一个或某一类接口的并发数,我们可以按如下步骤进行分析计算:
(1) 梳理出被测接口被访问的业务场景和每个业务场景访问的次数
(2) 通过上述方法计算出业务场景的并发用户数
接口并发数 = 场景1 并发用户数 * 业务场景接口调用次数1 + 场景2并发用户数 * 接口调用次数2 + …
假如一个系统需支撑10万在线用户数访问,如何通过性能需求分析来计算并发用户数?大家可以通过以上内容学习,独立思考下?
六、 性能测试用例与场景
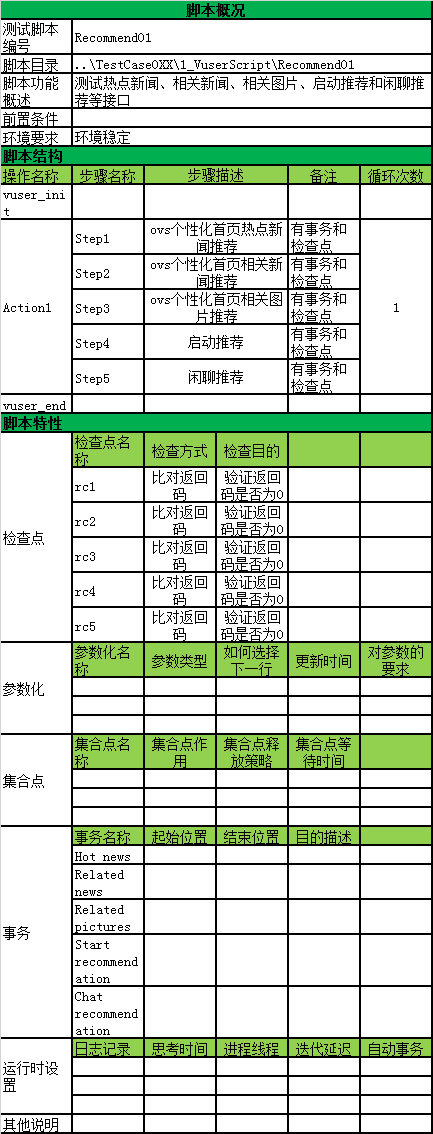
脚本模板
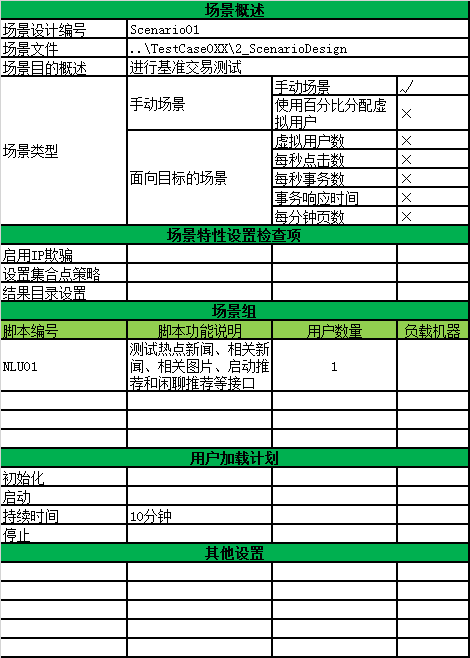
场景模板
七、 性能测试工具选择
1. 数据建模工具
DataFactory是一种强大的数据产生器,它允许开发人员和QA很容易产生百万行有意义的正确的测试数据库,该工具支持DB2、Oracle、 Sybase、SQL Server数据库,支持ODBC连接方式,无法直接使用MySQL数据库,可间接支持。
2. 脚本开发工具
(1) 若考虑脚本运行效率,则可考虑底层开发语言C或支持异步通信的语言JS,我们可以分别选择:Loadrunner 或 Node.js 的IDE环境进行开发。
(2) 若考虑脚本开发效率,则可考虑代码复用性,可以选择面向对象语言C#或Java,为此我们可以分别选择:VS2008及以上版本 + 对应LR.NET控件 或者 Eclipse4.0及以上版本 + JDK1.7及以上版本。
HTTP、Socket等协议接口性能测试脚本开发过程,请详见附件:
HTTP接口性能测试之脚本开发与性能问题分析.pdf
利用LR.Net控件完成性能测试脚本编写方法.pdf
Node.js学习入门手册.pdf
3. 压力模拟工具
(1) 若为Java类接口且单机并发数控制在500内,则可选择Jmeter或者 Loadrunner。
(2) 若为WebService类接口且单机并发数控制在500内,则可选择SoapUI或者Loadrunner。
(3) 若单机并发数超过500且控制在5000内,则可选择Loadrunner。
(4) 若单机并发数超过5000,则建议采用负载集群,即采用“中控(Control Center)+ 多机部署(Load Generator)”方案。
4. 性能监控工具
4.1 监控工具
无论Windows或Linux平台,一般存在的是一个或一组进程实例,我们可以选择Loadrunner 或 Nmon 来监控。有时为了获取被测应用的一些特性指标,可以选择被测组件自带的性能工具集或监控系统。常见应用服务器监控工具推荐如下:

4.2 监控平台
监控机器主要对被测集群服务器的服务或资源使用情况进行监控,比如各种开源的监控工具,MRTG:流量监控;CACTI:流量预警,性能报告Smokeping:IDC 质量监控;综合监控:Nagios、Zenoss、Ganglia 、Zabbix、Sitescope、Hyperic HQ 等,如下所示:
4.3 第三方监控云服务(APM)
APM提供端到端应用性能管理软件及应用性能监控软件解决方案,包含移动,浏览器,应用,基础设施,网络,数据库性能管理等,支持Java、.NET、PHP、Ruby、Python、Node.js、iOS、Android、HTML5等应用性能监控管理,主流云服务包括听云、OneAPM等,如下所示:
八、 性能测试结果分析
1. 指标分析
性能测试的指标可分为产品指标和资源指标两类。对测试人员而言,性能测试的需求来自于用户、开发、运维的三方面。用户和开发关注的是与业务需求相关的产品指标,运维人员关注的是与硬件消耗相关的资源指标。

(1) 从用户角度关注的指标
用户关注的是单次业务相关的体验效果,譬如一次操作的响应快慢、一次请求是否成功、一次连接是否失败等,反映单次业务相关的指标包括:
a.成功率b.失败率c.响应时间
(2) 从开发角度关注的指标
开发人员更关注的是系统层面的指标。
a.容量:系统能够承载的最大用户访问量是多少?系统最大的业务处理量是多少?
b.稳定性:系统是否支持7*24小时(一周)的业务访问。
(3) 从运维角度关注的指标
运维人员更关注的是硬件资源的消耗情况。

以上说明了测试人员在选择指标时需站在用户角度去思考,另外为了后续能够更好地分析问题,更需掌握与被测组件特性或运行原理相关的性能指标。
举例来说,通常接口系统均会直接或间接地访问数据库层介质(如Mysql、Oracle、SQLServer等),此时我们需考虑由接口系统产生压力下存储介质的性能情况,通常我们会选择分析指标如下:
(1) 连接数(Connections)
(2) 每秒查询数/每秒事务数(QPS/TPS)
(3) 每秒磁盘IO数(IOPS)
(4) 缓存命中率(Buffer Hits)
(5) 每秒发生的死锁数(Dead Locks/sec)
(6) 每秒读/写字节数(Read/Write Bytes/sec)
对于Windows或Linux平台具体指标监控及分析方法,请详见附件:
《Windows操作系统性能监控工具和指标分析V1.0》.pdf
《Linux操作系统性能监控分析手册V1.0》.docx
2. 建模分析
2.1 理发店模型
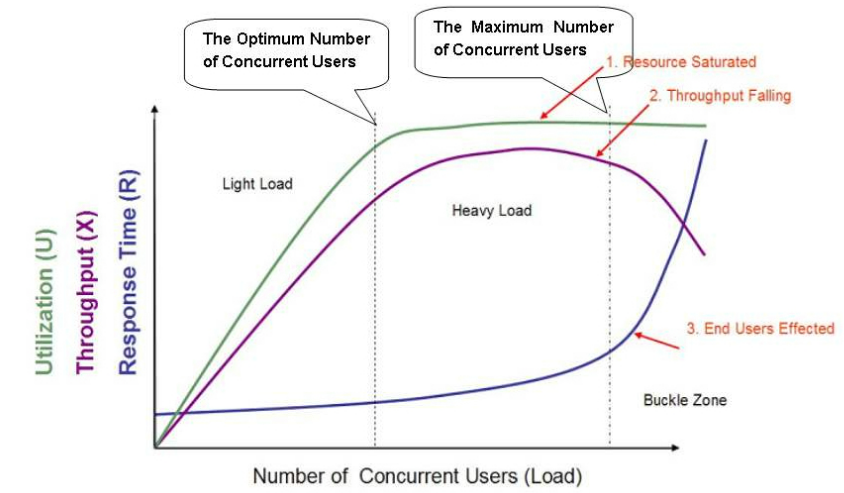
图中展示的是1个标准的软件性能模型。在图中有三条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在这张图中我们可以看到,最开始,随着并发用户数的增长,资源占用率和吞吐量会相应的增长,但是响应时间的变化不大;不过当并发用户数增长到一定程度后,资源占用达到饱和,吞吐量增长明显放缓甚至停止增长,而响应时间却进一步延长。如果并发用户数继续增长,你会发现软硬件资源占用继续维持在饱和状态,但是吞吐量开始下降,响应时间明显的超出了用户可接受的范围,并且最终导致用户放弃了这次请求甚至离开。
根据这种性能表现,图中划分了三个区域,分别是Light Load(较轻的压力)、Heavy Load(较重的压力)和Buckle Zone(用户无法忍受并放弃请求)。在Light Load和Heavy Load 两个区域交界处的并发用户数,我们称为“最佳并发用户数(The Optimum Number of Concurrent Users)”,而Heavy Load和Buckle Zone两个区域交界处的并发用户数则称为“最大并发用户数(The Maximum Number of Concurrent Users)”。
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。所以我们应该保证最佳并发用户数要大于系统的平均负载。
2.2 压力变化模型
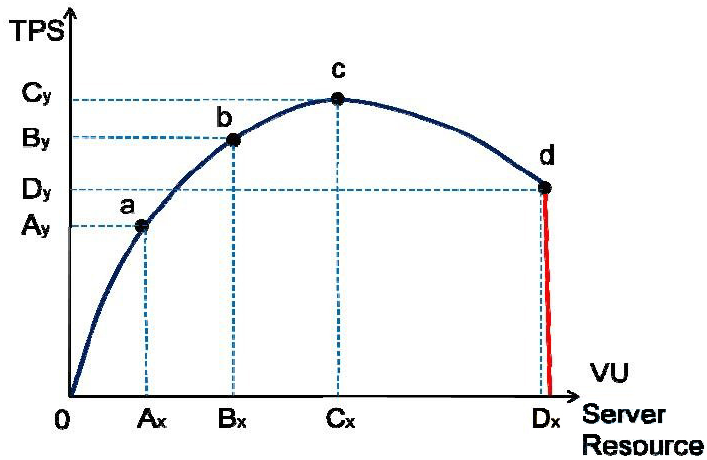
随着单位时间流量的不断增长,被测系统的压力不断增大,服务器资源会不断被消耗,TPS 值会因为这些因素而发生变化,而且符合一定的规律。
图中:
a 点:性能期望值
b 点:高于期望,系统资源处于临界点
c 点:高于期望,拐点
d 点:超过负载,系统崩溃
2.3 容量计算模型
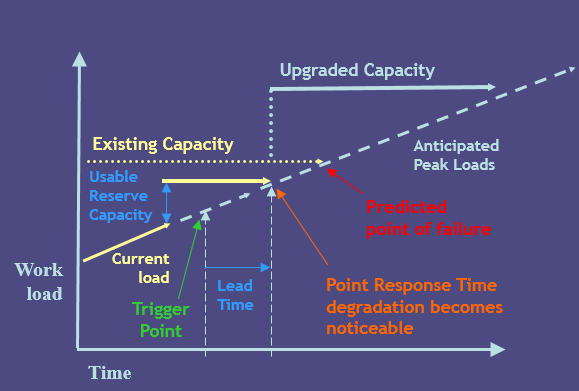
以一网站性能测试为案例:
1. 通过分析运营数据,可以知道当前系统每小时处理的PV数
2. 通过负载测试,可以知道系统每小时最大处理的PV数
即整理得
系统每小时PV处理剩余量 = 系统每小时最大处理的PV数 — 系统每小时处理的PV数
假设该网站用户负载基本呈线性增长,现有系统用户数为70万,根据运营推广计划,1年内该网站发展用户将达到1000万,即增长了14倍。即整理得:
系统每小时PV处理增加量 = 当前系统每小时处理的PV数 * 14 — 当前系统每小时处理的PV数
每天系统负载增加率 = 100% / 365 = 2.74 % (备注:此处将未来系统用户数达到1000万的负载定义为 100% )
系统每天PV处理增加量 = 系统每小时PV处理增加量 * 每天系统负载增加率 * 24
所以,我们可以知道在正常负载条件下:
系统可支持正常运行天数 = 系统每小时PV处理剩余量 * 24 / 系统每天PV处理增加量
假设该网站后续部署升级天数已知,这样我们可以知道提前升级的天数:
系统可支持正常运行天数 — 部署升级天数。
九、 性能测试通过标准
1. 所有计划的测试已经完成。
2. 所有计划收集的性能数据已经获得。
3. 所有性能瓶颈得到改善并达到设计要求。

