首先,我们有必要了解测试结果需要用于回答哪些问题。以下是部分常见示例:
- 压力测试:系统能够承受且提供可接受用户体验的最大并发用户数量是多少?拐点在哪里?
- 负载测试:在当前系统负载场景下,应用程序表现如何?是否能够实现进一步改善?
- 持久性测试:在运行一段时间后,系统工作效果如何?(有时我们需要每晚重启服务器,直到找出解决性能逐步下降的根本原因。)
- 峰值测试:如果正常运行的系统被突如其来的峰值压垮,我们需要多长时间才能完成系统恢复?
另外,在性能测试规划当中,我们还应当对自身能力进行考量:
团队是否准备好应对此类突发状况?或者还需要进行额外培训?
我们能够以怎样的速度找到性能问题的解决办法?
我们已经具备哪些物理资源?不具备的部分存在怎样的获取难度?
带着这些问题,我们即可有针对性地对系统进行审查,并思考如何加以改进。
为了控制篇幅,今天我们只专注于其中一项议题:在明确了预期负载后,我们该如何运行准确的对应负载场景?
性能测试规划:并发用户数量
这里需要再次强调:我们无法在测试起步时即模拟全部并发用户。在这种情况下,一定会同时出现多种问题,而我们很难弄清其真正根源。因此大家应当以迭代方式不断提升负载强度,并在过程中观察所出现的问题。
- 示例:负载测试
现在,我们假定需要测试当前系统能否支持1000名并发用户。
1.首测:1用户,无并发。我们将此作为基准,当然大家也可以选择5用户或者10用户,但请确保具体数字远低于预期水平。
2.二测:200并发用户(或者预期负载的20%)。现在我们将能够得到大量信息,其将最终决定测试过程是否顺利。
在初始测试时,我们首先解决重要问题与默认配置(连接池数或者Java堆大小等),借此了解如何将响应时间与基准水平进行比较。在分析与故障排查完成后,我们再次重复这一测试,直到得出可接受的时间。
根据实际结果,我们考虑在第三次测试中使用40%负载强度(以20%作为基础增量)还是50%(接下来为75%和100%)进行实验。无论如何选择,我们都能在过程中了解到系统的响应时间变化,并掌握其随负载提升所产生的变化。
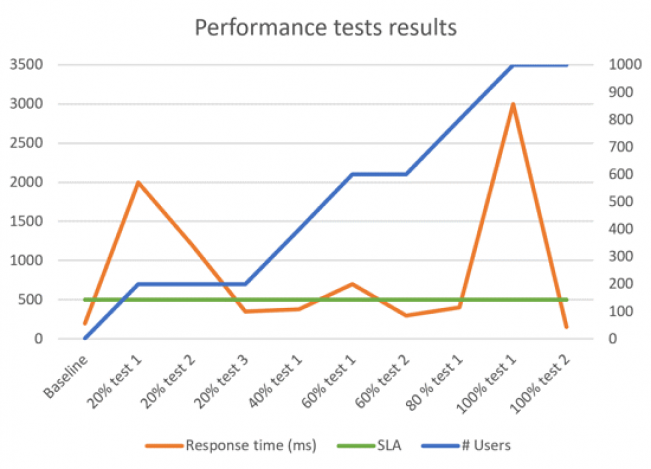
在本示例中,我们将20%作为增量。另外,我们会重复测试直到在各种负载强度下达到符合预期的SLA,之后再进行新一轮增量。
- 示例:压力测试
在第二项示例中,我们希望利用压力测试找到系统的性能拐点。这意味着我们要增加用户数量并分析其是否会同步带来通量增加。一旦并发量增加但通量不变,则意味着我们到达了拐点,这时系统已经达到饱和状态。
这里我们最好采取所谓探索性能测试,即假设拐点一定存在于1000并发用户以内的区间。
目前各类负载模拟工具皆可随时间推移进行负载量提升,例如在开始测试时为0并发用户,到1小时时则为1000并发用户。如此一来,我们即可观察系统通量何时发生下降。假设拐点出现在约650并发用户,则我们可以进一步细化以确定准确的拐点位置。
- 示例:持久性测试
在持久性测试中,我们在可接受条件下运行一项恒定负载,例如在最大容量的50%到70%之间。当然,具体情况视您的实际系统场景而定。
一般来讲,此类测试应在压力或负载测试之后进行,用以发现其它类型的问题(例如内存泄漏与挂起连接等)。如果有时间,大家可以延长测试周期以发现更多问题。
- 示例:峰值测试
正如之前提到,峰值测试的意义在于了解系统能够以怎样的速度实现恢复。在这里,我们可以尝试设置1分钟的流量峰值,而后降低负载,观察系统能否正确响应或者将请求暂时挂起。
当然,大家也可以先尝试建立小型峰值,而后再逐步加大强度以研究系统的实际反应。需要强调的是,相关模拟请尽可能与用户行为的分析结论相对应,特别是基于相关日志信息。
总结
性能测试规划的具体设计取决于您希望从中回答的实际问题,但其共同点在于,我们需要尽可能减少测试次数、优化测试成本并提升收益。因此,迭代式增量(用于负载、持久性与峰值测试)以及细粒度(用于压力测试)方法无疑值得大家加以尝试。
原文标题:How to Make a Performance Test Plan
原文作者:Federico Toledo

