
一、为什么要测试左移?
众所周知,软件工程原则:问题发现得越早,修复问题的代价越低。在《代码大全》一书中,从软件工程实践角度说明一个Bug的成本在产品需求分析阶段、开发阶段、测试阶段、生产阶段有着天壤之别,在修复难度、引入新问题的可能性、沟通成本等方面计算,集成测试阶段修复一个Bug的成本是编码阶段的40倍。
什么是测试左移?即测试向左扩展,让测试介入代码提测之前。比如,扩展到开发阶段,在架构设计时考虑产品的可测试性,进行开发自测。测试左移是一个理念,代码门禁 [1] 是测试左移的典型实践,即提交代码自动触发编译和测试,构建失败则阻塞代码提交。
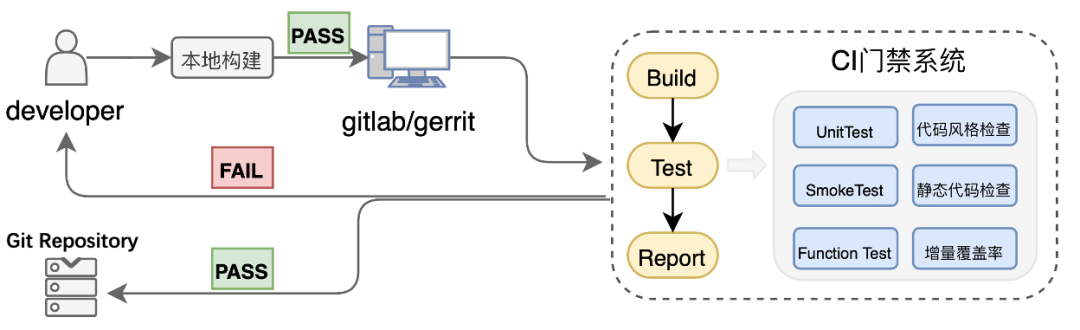
图1 代码门禁
代码门禁通过缩短测试反馈弧尽早发现缺陷,阿里云块存储团队代码门禁单日有效拦截百余次Case,拦截多个业务逻辑缺陷、百余次进程Crash、数据安全性缺陷、CPU/Mem资源使用缺陷等。如若没有代码门禁,将导致问题被掩盖,不断积累。
二、何时进行测试左移?
在系统最初阶段建立严格的代码准入标准和CICD系统是否是最好的时机呢?从质量保证的单一维度考虑,答案是肯定的。但从业务整体效益来看并非全局最优。理性看待技术债,技术债像贷款,有好也有坏,可以超前消费变现贷款买房,但相应的,有利息,利滚利,开发难度越来越大。
RethinkDB与MongoDB在竞争中失利。技术上,RethinkDB比MongoDB更追求完美,但是比MongoDB发布稳定版本晚了三年,错过了NoSQL的黄金时机,详细内容可以阅读《RethinkDB:why we failed》[2] 。如下图所示,ABC三家公司关于技术债和业务先行的时间之间的平衡:
- A公司:只关注业务,不关注技术债;
- B公司:持续关注技术债,但对业务时机不敏感;
- C公司:持续关注业务和技术债。对业务机会很敏感,最初放手借贷,控制技术债并在合适的时候偿还。
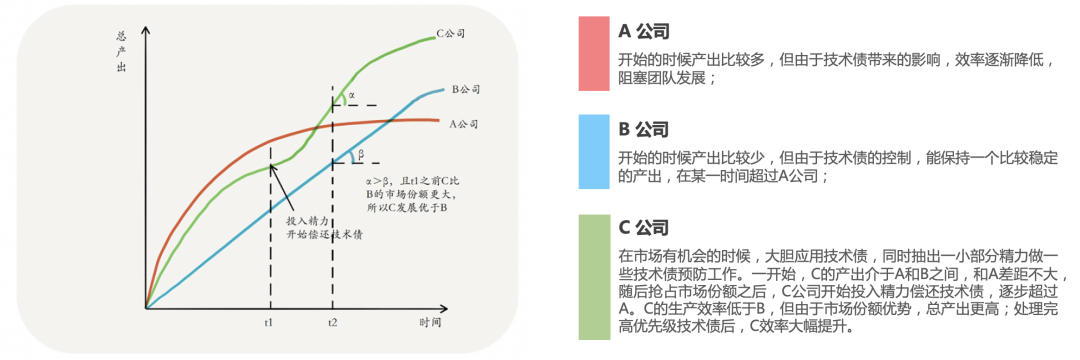
图2 技术债 (来源:《质量与速度的均衡:让“唯快不破”快得更持久》葛俊)
阿里云块存储在2018年初发布ESSD [3] 邀测,业界首个百万IOPS的云盘服务,性能上有50倍的飞跃,在真实业务场景中,PostgreSQL数据库的写入速度快了26倍。透支了大量的技术债抢先了市场之后,团队内部集中偿还技术债,进行质量建设,一年后ESSD达到规模铺量的质量标准并进行了商业化。
三、测试左移的原则和实践
提前透支大量技术债后,团队养成了“糙快猛”的研发习惯,对于改变习惯和测试左移将面临落地的挑战,需要从上至下调整预期,测试左移的前期必然带来项目交付周期的放缓,长远来看,整体效率更高。
测试左移原则不等同于测试原则,实践总结了三条测试左移的原则如下:
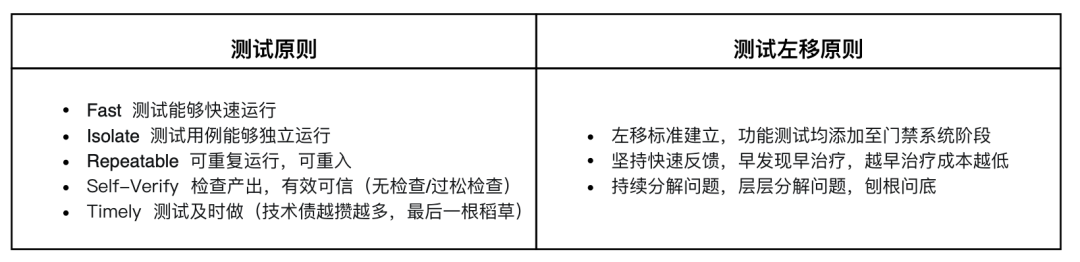
表1 测试左移原则
✪ 原则一:左移标准共识
建立左移标准并在团队内达成共识是测试左移最基础的原则,在代码门禁系统中要求代码覆盖率卡点、静态代码质量扫描,业务覆盖率 [4] 要求是所有功能测试均需在代码门禁阶段添加相应的测试Case覆盖。
例如,块存储的云盘是一个分布式存储系统,通过建立了Cluster in Docker的一键秒级构建集群环境实现Function Test测试脚手架,使得全链路E2E测试在代码门禁阶段有了落地的土壤。新Feature评审时功能测试不接受手工测试报告,只接受Function Test List的Code Review,以避免手工测试无自动化沉淀,相同问题重复出现。
✪ 原则二:坚持快速反馈
早发现早治疗,越早治疗修复成本越低。对于架构设计、编码实现和测试不足遗漏到生产环境的缺陷,不断反问,该问题是否可以在更早的测试阶段拦截?
例如,分布式系统下的级联雪崩故障,RPC Timeout不合理 + 无限重试 + 无并发Queue Depth限流造成错误的循环持续运转,负反馈机制压崩了分布式系统。全链路的极限压测是必须的,同时对于单一功能测试验证也必须在代码门禁环节添加自动化Case,让自动化验证限流、重试和超时机制符合设计实现预期。
✪ 原则三:持续分解问题
持续分解问题是测试左移最核心的原则,把一个系统拆解为多个子系统,用抽象和分层的方法,让每个同学开发时只面对有限的信息,并且能够有条理的深入到每一个子系统中查看细节。
例如,将复杂问题拆分成具体到每个模块松耦合的功能语义,各模块补充各自的契约测试覆盖。对于分布式系统Server热升级(热升级,即不影响服务的升级),需在升级前,中心管控节点Master将Server进程服务调度走,Server进程之间负责服务迁移(老进程Unload,新进程Load),Client需从Master/Server感知到服务已被调度走,需更换Location进行访问,拆解成Client/Master/Server的多个模块内Case覆盖。
在测试左移的实践过程中,总结了如下三个阶段:
✪ 阶段一:建立测试脚手架
简单可依赖的CICD的测试框架是基建保障。业界有很多开源的CI测试框架,例如Jenkins、GitlabCI、Travis-CI、Tekton等,阿里的Aone和蚂蚁的LinkIn等。
对于IaaS的底层块存储分布式系统,单个单元测试即达到4 Core Cpu和6GB Mem的资源需求,单机无法满足近万个门禁Case测试的及时性。业界和公司内的系统无法满足分布式编译构建和分布式测试的需求,块存储基于Kubernetes+Jenkins自研实现了门禁系统。
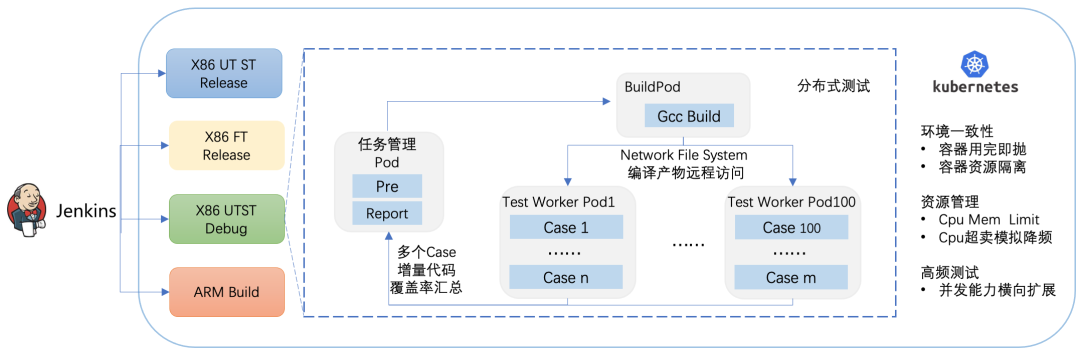
图3 EBS CI门禁系统
通过Kubernetes实现Case资源隔离,每个Case独占容器,容器运行过程中CPU/Mem资源设置Limit,避免Case之间打架(例如:某个Case内存泄漏导致内存不足,发生争抢,CGroup可能误杀了其他Case),Case运行环境用完即抛确保环境一致性,提交代码即自动触发测试(Test as a Service),确保有了土壤可以落地后,门禁系统负责测试运行,开发者负责Case编写和不稳定Case的问题解决。
✪ 阶段二:高频测试,快速测试
"If it hurts, do it more often",高频测试是治理不稳定Case的法宝,越低频复现的问题越难调查,尽量多的暴露不稳定的失败,降低问题调查的门槛。通过分布式并发运行、提高构建速度(增量编译/分布式编译)、分层测试提升测试运行速度。
块存储门禁系统基于Kubernetes实现,即具备测试并发度横向扩展能力,白天CI系统进行代码门禁卡点和自助构建任务,夜间高频百轮回归门禁Case和E2E回归。高频测试大大增加了低概率时序Bug的暴露频次,在门禁系统中通过CPU资源超卖,相当于模拟CPU主频降频,多次发现低概率的数据安全性、进程Crash等缺陷问题。
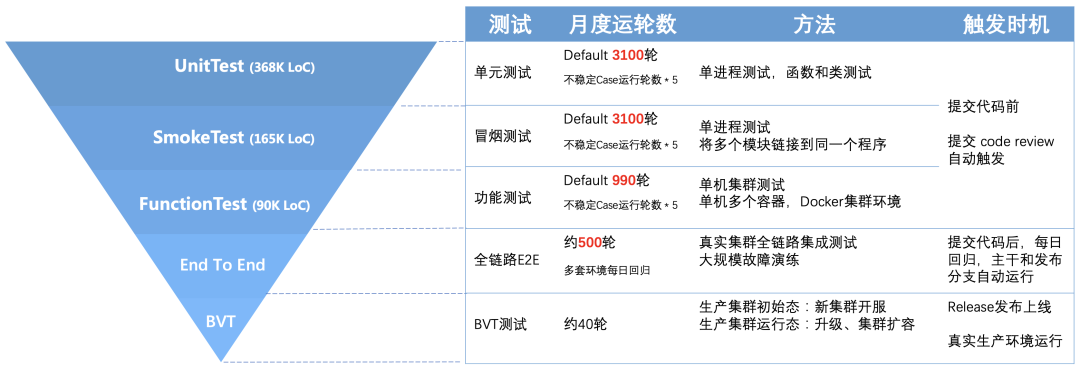
图4 EBS 各级测试运行轮数
✪ 阶段三:不稳定Case治理
不稳定Case治理可能是门禁系统中挑战最大的部分,若不治理将导致破窗效应,测试左移则前功尽弃。不稳定Case治理的慢性病更适合小步快跑高频反馈,在具体实践中,首先,通过组织会议脑爆,共同吐槽门禁的不稳定,建立自发的共识、原则和标准进行公示,发动群众的主观能动性;其次,找到推动变革的关键人物,Team Leader和核心成员高度配合,建立红黑榜,每月树立效能之星,做的差的同时也有相应的惩罚;最后,找到推动变革的行动抓手,不稳定Case发现的数据安全性、Crash的严重缺陷团队内强调Case质量和该同学切身利益手头项目的强相关性,建立硬性标准:5%以上概率的失败commmit一天内revert等。关于不稳定Case的治理Google和微软在2016年和2017年相继发表了论文,Google论文 [5],微软论文 [6] 。
块存储治理不稳定Case主要通过高频测试和文化布道。块存储门禁系统是全量卡点,即任一Case失败则阻塞代码提交,随着Case的增加,对Case的稳定性要求与日俱增。门禁系统上万个Case中如若有3个Case通过率为90%,则整体通过率为72%;一周内不稳定的Case的每日运行轮数是稳定Case的权重5倍,未修复Case更高频的暴露复现,对于已修复的Case以验证修复效果。团队内从上至下达成一致共识:生产问题优先级 > 不稳定Case优先级 > 新Feature项目研发优先级。下图是块存储近半年不稳定Case Top15的回归失败轮数,分子是失败轮数,分母是单日运行轮数,失败比例越高颜色越深。

图5 EBS 门禁Top15不稳定Case通过率
在测试左移的实践落地过程中会遇到很多挑战,知行合一很难,整个团队遵守相同的标准规范落地更难。块存储系统有百万行代码,在近一年中生产代码行数增加约20%,测试代码行增加约100%,近万个门禁Case,持续治理不稳定Case,门禁通过率从4.7%提升至70%,后续计划通过精准测试来进一步提升门禁通过率。
仰望天空,并脚踏实地。在测试左移的编码实践方面推荐学习TDD(Test-Driven Development),在《软件测试》《Google :Building Secure & Reliable Systems》《重构》 《重构与模式》《敏捷软件开发》《程序员的职业素养》……国外泰斗级程序员大叔的书里,全部都推荐了TDD(测试驱动开发)。TDD不是万能药,主要思维模式是,先想清楚系统的行为表现,再下手编码,测试想清楚了,开发的API/系统表现就清晰了,API/函数/方法语义就明确了。如何衡量测试的好坏?好的测试是What,包含Given When Then;差的测试是How,若每次方法/函数修改之后如果必须完全重写测试,或许需要重新考虑测试实现和系统本身的设计结构了。
扩展阅读
[1] 代码门禁
https://devblogs.microsoft.com/bharry/pre-checkin-validation-for-tfs/
[2] RethinkDB:why we failed
https://www.defmacro.org/2017/01/18/why-rethinkdb-failed.html
[3] 阿里云首个百万IOPS云盘的背后
[4] 业务覆盖率
https://www.continuousdelivery20.com/blog/ch-code-coverage-best-practices/
[5] Google论文
https://research.google/pubs/pub45794/
[6] 微软论文
http://uploads.pnsqc.org/2016/papers/12.WinningWithFlakyTestAutomation.pdf

