以下总结以web测试为例,其他类型测试可参考。
步入正题之前,我提两个问题:
·在工作中,你们发现“bug”是立马给开发提bug单还是先自己尝试排查一下bug产生的原因呢?
·提bug单的时候,是怎么描述bug呢?
相信有不少人测试在发现bug之后,立马给开发提了bug,很少去排查bug产生的原因。
在开发准备修复bug的时候,发现测试提的“bug”描述不清,不知道如何复现,只能自己琢磨或者叫QA来演示一遍,最尴尬的是,可能在测试演示完之后,才发现这个并非bug,而是由于QA的不规范导致的。这样就会引起开发的不满,觉得测试在浪费他们的时间。
所以在我们发现问题的时候,首先要做的第一件事就是需要确认一下是否是我们本身测试的不规范导致的。若不确定,可再尝试进行复现。bug描述一定要写具体,否则不仅浪费开发的时间,也会浪费自己的时间。
开发为测试列出的几大症状:
问题描述不清
说明bug要么开局一张图,要么一句话,开发复现bug全靠蒙。
正确姿势: 问题应该有详情的描述,图文并茂,场景说明,以及bug出现的流程,对应账号密码等。
对bug定位不准
bug瞎指派。前端的bug指给后端,后端的bug指给前端。
正确姿势: 分析错误产生的原因,分析是前端还是后端产生的bug,123砸过去。
不理解需求
总是测一些生产环境中根本不可能存在的情况。甚至有些需求就是如此设计,不管三七二十一直接提bug。
正确姿势: 先把需求理清楚,设计用例的时候,把一些实际不可能发生的事情剔除掉。
如何高效地排查问题呢?
步入今天的正题,来,跟着我,从我的世界走一走。
产生问题的原因
·不理解需求
·配置不对
·造数不对:包含不可能存在的逻辑
·服务有bug
排查问题
新上一个功能时,发现前端页面展示还是旧的,发起请求还报错?
如果部署没问题的话,那么大概率是前端存在缓存,可清除缓存试试。这里就有个问题:如果功能发到live,但是由于前端存在缓存,用户没没有清除缓存,那们从前端向后端服务器请求时,一直报错,一旦被投诉,那这个锅就是你来背了。
分辨是前端的锅还是后端的锅。
前端的锅不仅仅只有UI的问题,需要发起请求,处理请求,并渲染到前端。
出现问题时,可先判断接口是否有错误,返回的结果是否符合预期。若接口无错误且接口返回符合预期,但前端展示不符合预期,应该由前端负责修复。
若接口有报错,可优先确认,前端有没有按照约定的格式向后端发起请求,如果没有,那么前端需要负责修复。
若接口报错,前端也按照约定的格式发起请求,那么锅就在后端了,接着可继续往下走,继续排查问题出现的原因。
可通过接口返回的错误信息去猜测错误的来源
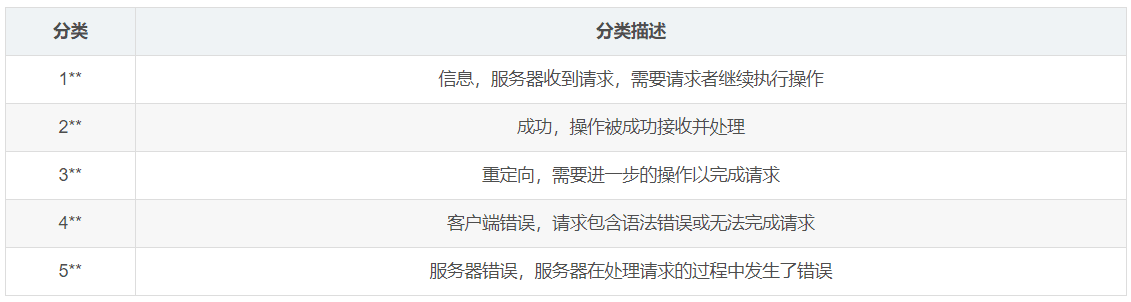
响应码。可根据返回的响应码去定位问题。需要大家熟悉这些响应码。
响应头。一般后端返回的错误信息会放在响应头中,如果你们不会将错误信息放在响应头的话,可忽略这个。
响应体。如果请求报错的话,接口一般会返回错误信息以及错误码,可通过这些去定位问题。在源代码中输入错误信息定位报错的具体位置(全局搜索),再根据前后调用去分析具体原因。
从日志入手,查看具体的日志信息
从日志入手的话,那么就需要学会在哗啦哗啦的日志中寻找具体且有用的关键信息,相信大部分同学都用过grep这个命令,相比awk,sed而言,这个命令使用起来更简单,足够满足我们的需求了。推荐grep的几个常用参数:

找到报错信息之后,在源代码中使用全局搜索,找到报错的具体位置,分析报错的具体原因。
再不济,可自己本地调试(当然,这个是在时间相对充分的情况下,如果前面两步还无法找到具体原因的话,可直接交由开发处理)
可以先把bug提给开发,然后自己在本地调试查找具体的问题。如果你仅仅是功能测试,想转测开,这个步骤对自己能力提升也很有帮助。但是如果你只想点点点的话,那这步骤就免了。

