AB测试的原理很简单,只用到了最简单的统计假设检验,但表面的简单通常都隐藏着陷阱,这一点没有经过实践的摸爬滚打是不容易看到的,今天我就把前人已经踩过的坑,一共15个,给大家分享一下。在分享之前,大家脑中一定要有个概念,AB测试虽然简单且强大,但是其成立是有前提的:
A组和B组的用户一定是要“随机”分配。随机这个事很有学问,绝对的随机甚至根本不可能,实际中只能做到尽量接近真随机。换句话说,随机性并不总是成立,你要仔细小心它失效的场景。
在以你测试的时间点为中心的一定时间范围内,用户的行为是不变的。
只要牢记并时刻检查这两点假设,那么很多下面的陷阱你自然就能避免了。

1.不做AB测试
很显然,我们不能不做AB测试。不要企图用一些其他方法替代AB测试,比如:通过比较产品上线之前N天和之后N天的情况,对比分析去得出结论。这不也是AB对比吗?看起来没毛病,这种方法也不是完全没有用,但是很不稳定,所以不要用。
2.乱作AB测试
既然AB大法这么好用,那么我们全靠它不就行了吗?以后有任何功能任何改动都先搞个AB测试吧!AB测试并不是做的越多越好,我们可以通过下面简单的公式来看一下:
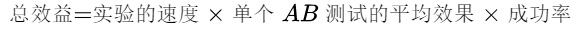
我们追求的是总的效果,除了注重数量更要注重质量。
3.采样污染
举个例子,如果你在节假日对你的产品做AB测试,那么测试阶段的用户群(样本)和平时的用户群自然会有很大的差异(回顾开头讲的第二条前提条件),这样很难得出你想要的测试结果。AB测试无法在全体样本上进行实验,所以必须采样,采样要保证随机性且能代表总体样本的分布,做实验的时候就要特别注意避免一些可能导致采样污染的特殊因素。
4.时间范围不够
除了要避免在一些特殊时间进行测试,测试的时间还要足够长,理由如下:
时间长有助于收集更多的数据,保证统计显著性
如果新的特征改变比较明显,老用户可能会不适应,那么你需要给老用户一定的时间去适应你的改变,然后收集的数据才更有统计意义。(参考开头提到的第二条准则)
5.只关注平均值
如果测试结果显示新版本比旧版本平均多吸引了30%的用户,那么是否就证明万事大吉,可以开开心心上线了呢?还不行。这个时候还要对更细粒度的数据做一些分析,保证你看到的“好结果”是真的。举个极端点例子,万一是系统Bug导致新版本多统计出了更多的用户呢?我们相信,在AB实验结束并且展现了良好的结果时,你已经基本接近成功了,但是永远不要在分析更详细用户数据之前下结论。
6.忽视技术实现
有些看不见的东西一样会影响用户,AB测试阶段除了产品特性的不同,技术细节也会改变,这些会不会影响到实验结果?如果新版本加载更多的css资源,会不会导致页面加载变慢?这些看不见的细节也会影响用户体验,给实验结果带来干扰。
7.不去思考为什么
AB测试不会一直成功,甚至失败的次数可能更多,但是如果实验结束之后不去思考为什么,那才是彻底的失败。实际上AB测试失败的时候,才是我们从中学习并真正了解用户的时候,千万不要放弃这样的机会,要多问些为什么。
“想要提高成功率,先提高失败率。”

8.用错误的度量标准
举个例子,如果你优化的是网站首页的性能,那么就不要拿全站的统计结果去做度量标准。度量标准要选好,不要想当然。
9.做一系列的测试
如果新版本有10个细节上的改动,那么是不是我们要做10个AB测试来分别测试他们的效果呢?当然不行,千万不要这么做。产品的改动效果绝对不是线性相加的,不同的特征之间要一起组合才能生效,就好比把背景变黑之后一定要把字体变白才行。
10.实验设置有噪声
还有很多我们无法预料的因素可能会影响到实验结果,那么怎么办呢?我们不止要做AB测试,还要做AA测试,用AA测试来保证实验设置本身没有噪声干扰,这个也很重要。于是在实际中你要把1/3的用户分配给B组,1/3的用户分配给第一个A组,1/3的用户分配给第二个A组。
11.忽略环境的改变
不管你的AB测试是成功了还是失败了,在一定时间之后你都要重新审视它,因为环境变了。昨天失败的AB测试,很可能是你的理念超前了,也许过了一年用户就可以接受了呢?一次失败不代表用永远失败,反之亦然。
12.交叉访问污染
当线上同时存在两个版本的时候,你一定要考虑到单个用户的体验。如果一个用户在不同浏览器、不同设备上访问到了不同的版本,那么可能会带来用户体验的下降,同时对收集的数据造成干扰。比如,如果AB版本之间的差异过于明显,那么老顾客可能就会很讨厌那个新版本,而在新版本上表现出消极的行为,同时在老版本上表现积极的行为,而我们无法从统计结果中对这种偏差就行纠正。所以保证单个用户体验的一致性就很重要。
13.漏斗污染(Funnel pollution)
不确定这个翻译准确不准确,就直接按英文直译了。如果你是一个电商网站,那么你最终的目标是要用户下单付款,你的优化目标应该是针对整个下单的全流程,并且以最终下单的数量作为度量标准。假如你在首页做了某些活度,让点击产品页面的用户大幅度提升,有些统计数据看起来会很漂亮,但是对最终的结果可能没有任何帮助。这个也要注意。
14.同时运行多个AB测试
线上同时存在多个版本的话,实在是有点复杂,一般情况下不会这么干,但仍要警惕。
15.使用错误的经验
AB实验毕竟是一项科学实验,所以我们要用数据说话,不能想当然。不要乱用一些道听途说的经验,比如:“1000个用户样本就够了”,实际上收集多少用户的数据是要严格计算的。上一篇文章我们分享过类似的工具。再比如,不要以为在桌面端测试通过的方案,就可以放心在手机端同时上线了,实际上不同平台的差异非常大,必须单独进行AB测试。
总之,要记住开头提到的AB测试成立的两个前提,要时刻检验它们是否成立:
A组和B组的用户一定是要“随机”分配。
在以你测试的时间点为中心的一定时间范围内,用户的行为是不变的。

