现今互联网软件的测试策略和方法论相比传统软件有着很大的不同,造成两者有显著区别的根本原因在于互联网软件的发布周期比起传统软件的发布周期要快很多,这种发布周期的巨大差异使得两者的测试基础架构建设有着显著的不同。同时,现今的很多传统软件企业也在尝试借鉴互联网测试领域的工程思维和最佳实践,希望可以找到一些有“化学反应”的结合点来优化传统软件的测试基础架构。
本文就将围绕这个话题展开讨论,看看有哪些互联网领域的测试基础架构的最佳实践可以被很好地应用到传统软件测试中去。我们会探讨两个主题,一是互联网企业如何在有限的时间内基于可扩展的测试执行集群完成大量测试用例的执行,并且会去讨论传统软件企业从中可以学到什么。二是互联网企业的高效率的失败用例分析与分类实践,同样的做法也可以被传统软件企业采用。
现在,对于很多传统软件企业的的开发流程依旧遵循传统的V模型,因此对应的测试策略通常也就顺其自然地采用了金字塔模型。但是在互联网企业中,由于普遍采用敏捷开发模型,所以对应的测试策略、测试流程和测试方法都会使用敏捷实践。因此,两者的测试理念和方法论的差别就会比较大。以下的图1展示了两者的测试策略模型。
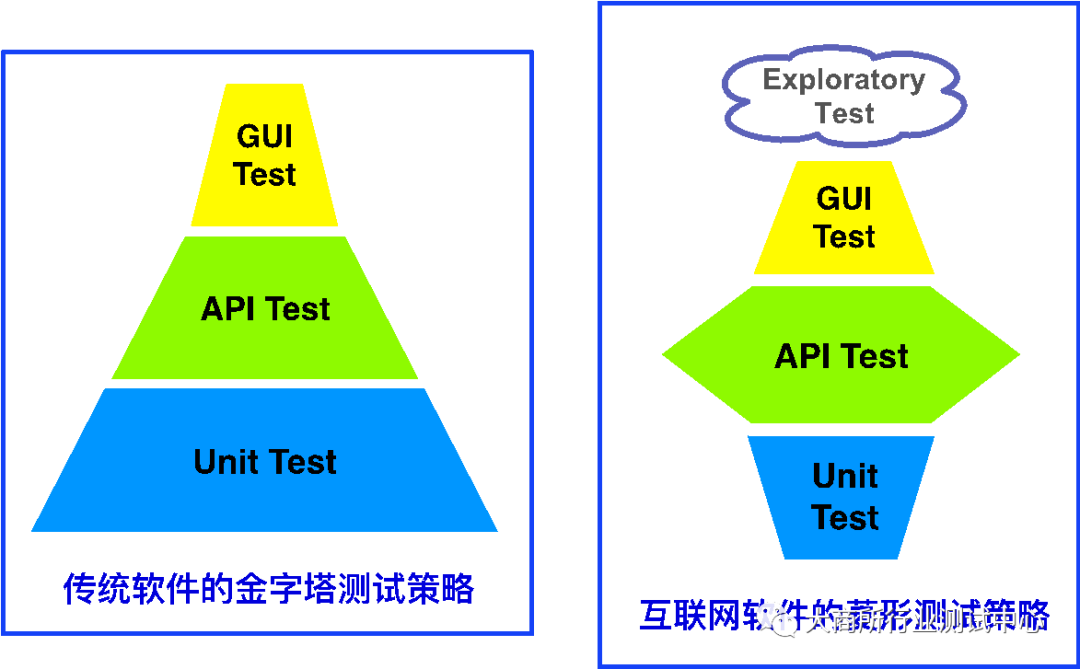
图1:传统软件和互联网软件的测试策略比较
传统软件的金字塔测试策略模型
在传统软件的测试策略金字塔模型中,我们往往提倡尽可能早的发现和暴露潜在的软件缺陷,因为发现缺陷的周期越靠后,那么缺陷修复的代价就越大。因此我们强调比较重量级的单元测试,这个阶段的测试依据是代码的详细设计,我们希望从底层实现上就能把控软件的质量。接着在单元测试之上,我们会去做集成测试或者API接口测试,以保证各个已经经过充分单元测试的模块组装在一起之后能够提供预期的设计功能,此阶段测试的依据是那些API接口的功能设计。最后在金字塔的最上层,会根据产品的功能需求来设计并执行相对完整的,并且是基于终端用户的端到端(E2E)的测试。
互联网软件的菱形测试模型
对于互联网软件的测试,通常只会做很少量的单元测试,但是对于API接口测试会非常重视,几乎占据了整个测试工作一半以上,甚至百分之六七十的工作量,是整个互联网产品测试工作的重中之重。对于最上层面向终端用户的端到端(E2E)测试,往往会采用GUI自动化测试技术来覆盖最核心业务功能的回归测试,而基于探索式测试来发现尽可能多的功能缺陷。
因此,如果你从测试的角度去审视传统软件和互联网软件的测试方法和技术,你会发现两者会有很大的不同。造成两者有显著区别的根本原因在于互联网软件的“快”,传统软件的发布通常是以“月”甚至是以“年”为单位的,而互联网软件的发布通常是以“天” 甚至是以“小时”为单位,发布周期的巨大差异使得两者的测试基础架构、测试策略、测试工具体系都有着显著的不同。所以,互联网的测试基础架构以及相关配套的测试工具链建设都是围绕“快”这个字来设计和开展的。那么我们接下来就来看一下为了顺应这个“快”,互联网的测试都面临了哪些挑战,我们又是如何来解决的。与此同时,我们会来讨论这些互联网的最佳实践中有哪些是传统软件可以借鉴和受益的。
挑战一:大量的测试用例需要在较短的时间内执行完成
由于传统软件的发布周期是比较长的,所以留给测试的执行时间也是比较充足的,当使用自动化的回归测试时,如果执行完一轮全回归测试的时间需要48小时甚至是更长的时间,也没有任何问题,因为每次产品发布前留给测试的时间窗口往往都有好几周,执行一轮自动化全回归测试的时间只占其中的一小部分。
但是,由于互联网软件的发布周期通常都很短,在CI/CD的支持下,目前很多互联网企业都可以做到“一天一发布”,因此,留给测试的时间窗口往往都会很短,一般来说,CI/CD的自动化程度越高,那么发布的频率就越高,同时留给测试的时间窗口就越短。也就是说大量的自动化测试用例需要在很短的时间,通常只有3-4个小时的时间内执行完,而且随着CI/CD自动化程度的不断提高,发布的频率就会更高,留给测试执行的时间就会更短。
为了在尽可能短的时间窗口执行完所有的自动化测试用例,我们就必须采用测试用例并发执行的手段,技术实现上就必须引入测试执行环境集群Selenium Grid,该集群可以承载大量GUI自动化测试用例的并发执行。
进一步,为了方便开发或者测试人员使用测试执行环境集群,或者说为了使测试执行环境集群的技术细节对于使用人员透明,就需要引入统一测试执行环境服务(TBS,Test Bed Service)。TBS的主要职责是负责管理、创建,扩容/收缩测试执行集群,并且为测试集群的使用者提供统一的入口。
一个典型的GUI测试执行环境架构如下图2所示,TBS会根据等待执行的测试用例的排队情况,动态决策测试执行集群的节点数量和类型,通常会使用Docker和Kubernetes来实现TBS的Gird管理。
当建立了TBS之后,当有大量的测试用例执行请求到来的时候,TBS首先会根据“测试用例的总数量”以及“要求在多少时间内执行完成”这两个指标去计算出需要多少个测试执行节点,假定计算得出需要在120分钟内执行完3000个测试用例大概需要500个执行节点,接着会进一步根据测试的执行要求,比如80%的测试需要执行在Chrome浏览器上,20%的测试需要执行在Firefox浏览器上,来决定最终节点的类型。一旦这些参数确定了之后,这些节点就会基于Docker技术被自动创建并挂载到Selenium Gird测试集群中。以上所有的过程对于测试集群的使用者来说都是透明的,这些背后具体的工作都是由TBS完成的。
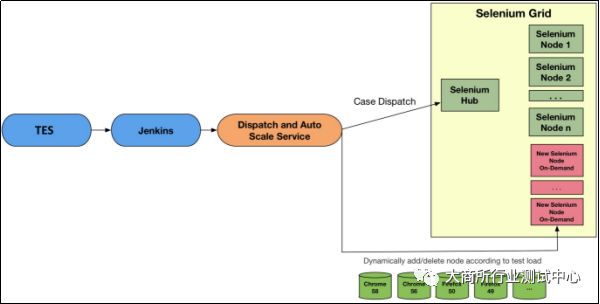
图2:典型的GUI测试执行环境架构
通过挑战一,传统软件测试能从中学到什么?
知道了互联网的测试执行环境的最佳实践后,你是否对于传统软件的测试执行环境建设也有所启发。是的,这个实践对于传统软件企业也是完全适用的,如果你所在的企业或者项目正在为测试执行环境准备而烦恼时,推荐你可是试试TBS的实践。
具体来讲,建议传统软件企业可以引入Selenium Grid来搭建自己的测试执行集群,并且通过Docker技术来管理Selenium Node,一方面就可以大幅度降低测试执行Node的维护成本,另一方面可以提高测试执行的并发度,加快测试执行完成的周期。至于要不要实现测试执行集群规模随着测试用例排队情况来自动伸缩,那还要取决于软件企业测试用例规模的差异化程度,如果需要执行的测试用例规模一般是比较固定的,那就可以采用固定的测试执行集群规模;反之,如果需要执行的测试用例规模的差异非常大,那就很难用固定规模的集群,因为规模大了会出现平时大量执行Node闲置,浪费资源,规模小了在测试执行高峰时段,测试并发度又不够。此时,强烈建议引入互联网的自动伸缩设计。
挑战二:失败用例的分析
由于互联网软件的全回归测试用例基数一般都是很大的,多的情况会有好几万个,少的一般也会上千,通常全部自动化测试很难一次性全部执行通过,往往会由于各种原因而导致失败,所以对于每个失败的测试用例的我们都需要去分析用例失败的原因。如果是测试用例问题,那就需要修复测试用例;如果是环境问题,就需要将该环境问题递交给相应的环境团队;如果是发现了真正的软件缺陷,那就需要将该测试用例和缺陷报告分配给正确的业务团队。
如果以上这些失败测试用例的基本分析和分配工作都是由人工完成的,那么这个的工作量其实是不小的,你可以想象一下,我们假定一轮回归测试只有1000个测试用例,哪怕只有5%的测试用例执行失败,那么每轮测试跑完需要人工分析的测试用例数量就有50个,我们假定一个测试工程师每天可以分析10个失败用例,那每一轮测试结束后,至少也要5个工程师1天的时间去分析,这个时间还仅仅是最基本的分析并在此基础上把失败用例分配到正确的团队,还没有包括缺陷的修复以及修护后的再验证。
实际工程项目中,往往测试用例数量远远不止1000个,而失败率实际也很难做到5%这么低,所以实际情况就是每轮测试执行完通常需要去分析几十个到几百个失败的测试用例。对于传统软件企业,这个问题可能还不是太关键,并不会因此而阻碍整个项目的进度,因为总的测试时间窗口是很长的。但是对于互联网软件来说,这个时间就完全不能被接受,就像上面提到的,互联网软件的发布周期很短,其中留给测试的整体时间是很少的,通常就是几个小时,此时,如果单单一个失败用例分析和分配就需要这么大的工作量,显然就会成为整个发布周期中的瓶颈节点,所以是必须要想办法去优化这个过程的。
那互联网团队是如何来解决这个问题的呢?答案就是“基于机器学习的失败用例自动分析和分配”方案,注意这里的“自动分析”并不是指分析用例失败真正的root cause,而是分析这个问题最有可能属于那个团队,接着就可以自动完成失败用例的分配,全程不需要人工参与,这个方法的具体落地是通过引入了测试日志分析服务(TLAS,Test Log Analysis Service)。每轮测试结束后,所有失败用例的分配都是在分钟级别通过TLAS自动完成,大大提高了整个测试流程的效率。
TLAS的主要架构以及工作方式如图3所示,其中,技术实现的关键有以下6点:
1. 被测应用的输出日志必须严格遵循统一的规范,每条日志的模块名字、时间戳、异常发生时的日志级别和规范都需要被严格定义,这个需要通过在研发过程中的“可测试性需求”来推进。
2. 测试用例本身的输出日志也必须严格遵循统一的规范。
3. 需要建立一个存储样本训练结果和参数的内部数据库,通常采用非关系型数据库。
4. 采用最适合的分类算法和聚类算法,并在前期训练阶段提供充足的训练样本信息。
5. 实际应用过程中,需要不断利用真实数据收敛自动分类的准确率。
6. 确定了失败用例的分类后,通过直接调用缺陷管理系统的API接口来实现失败用例的分配。
通过挑战二,传统软件测试能从中学到什么?
那么我们回过头来看一下,这个方式是否适用于传统软件测试,答案显然也是肯定的,同样可以大幅度提高失败用例的自动分配效率,同时还能节省大量的人力成本。当然如果传统软件想要应用这个模式,分类算法这部分可以做适当的简化,前期阶段甚至可以就先根据一些日志中的关键字来做分类,比如遇到“ORA-XXX“,那这个问题很能需要数据库团队来分析,那就可以把这个失败用例分配给数据库团队来做进一步的分析;如果遇到”页面对象无法定位“问题,那很可能是由于前端界面有了变化,GUI测试用例没有能及时更新,所以就应该先把这个失败用例分配给测试用例的责任人。
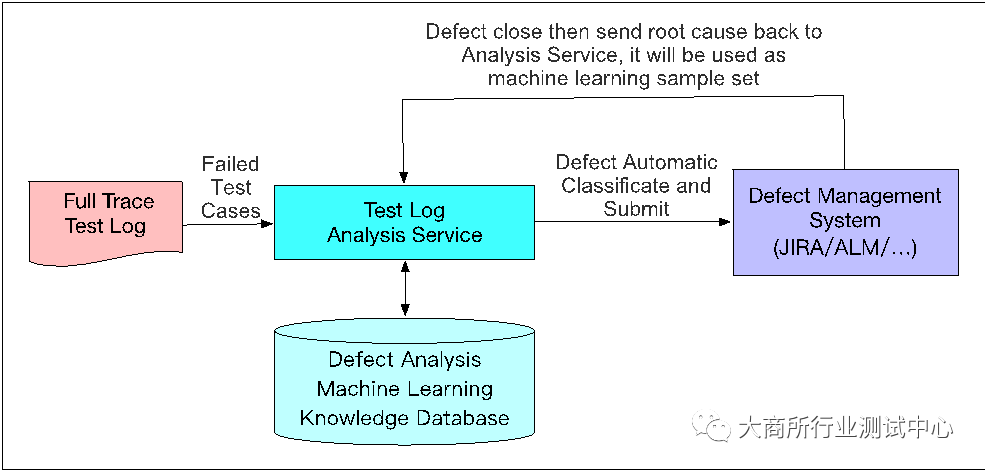
图3:测试日志分析服务的基本原理与架构
总结
通过以上的讨论,我们看到,像“大量的测试用例需要在较短的时间内执行完成“和” 低效的失败用例分配“等一系列问题其实无论对于互联网软件还是传统软件来讲,都是存在的,但是由于在传统软件行业由于发布频率较低,这类问题并没有成为整个测试过程中的瓶颈,也没有到非解决不可的地步。但是对于互联网软件,由于快速的迭代周期,CI/CD下的频繁发布,这类问题俨然已经成为了影响产品快速上线的拦路虎,已经到了非解决不可的地步,于是就出现了本文所介绍的互联网行业的最佳实践和创新。
当有了这些优秀的,并且被证明可以落地的最佳实践之后,我们应该反观传统软件行业,将这些互联网行业的最佳实践和方法论”有的放矢“地运用到传统软件行业中去,相信传统软件行业一定可以从中受益良多。

