安全软件的重点是能使系统更加安全。在开发软件时,绝对不想引入新的故障点,或者增加软件运行系统的攻击面。所以我们自然会认真对待安全的编码实践和软件质量。在这篇文章中,我们想解释一下我们在内部使用的用来发现漏洞和缺陷的模糊测试技术,以便在这些漏洞发生在客户那里以及我们亲爱的bug赏金猎人之前找到它们。
一种已经被漏洞赏金猎人证明是非常有效的发现软件安全漏洞的一种称为fuzzing的技术,这种技术需要在目标程序中注入意外或畸形的数据,以便导致输入错误处理,例如可利用的内存损坏。为了创建模糊测试用例,一个典型的模糊测试器将会改变现有的样本输入,或者根据定义的语法或规则集生成测试用例。一种更有效的模糊方法是覆盖引导模糊测试,程序执行路径被用于为测试用例生成更有效的输入数据。覆盖引导模糊测试会尝试最大化程序的代码覆盖率,以便测试程序中存在的每个代码分支。随着一些覆盖引导模糊工具的开源,如American Fuzzy Lop (AFL),LLVM libFuzzer和HonggFuzz,使用覆盖引导模糊测试技术从未如此简单。你不再需要掌握深奥的技术,或者花费无数个小时编写测试用例生成器规则,或者是收集覆盖目标所有功能的输入样本。在最简单的情况下,你可以使用不同的编译器编译现有的工具,或者分离出你想要的模糊测试功能,只需编写几行代码,然后编译并运行fuzzer。fuzzer将每秒执行数千甚至数万个测试用例,并从目标中的触发行为中收集一组有趣的结果。
如果你想要开始使用覆盖指导自己的模糊测试,下面会提供几个示例,描述如何使用我们内部所喜欢的两个Fuzzer:AFX和LLVM libFuzzer来构建一个被广泛用于XML解析的工具库——libxml2的模糊测试工具。
用AFL进行模糊测试
将AFL用于实际的模糊测试的例子很简单。在Ubuntu 16.04 Linux上,你可以通过系统的xmllint实用程序和AFL,并执行下面的七个命令来进行libxml2的模糊测试。
首先我们来安装AFL并获取libxml2-utils的源代码。
$ apt-get install -y afl
$ apt-get source libxml2-utils
接下来,我们对libxml2进行配置和构建,配置的时候使用AFL编译器并编译xmllint实用程序。
1. $ cd libxml2 /
2. $ ./configure CC=afl-gcc CXX=afl-g++
3. $ make xmllint
最后,我们为AFL创建一个包含“ ”的示例文件,然后开始并运行afl-fuzz。
$ echo "" > in/sample
$ LD_LIBRARY_PATH=./.libs/ afl-fuzz -i ./in -o ./out -- ./.libs/lt-xmllint -o /dev/null @@
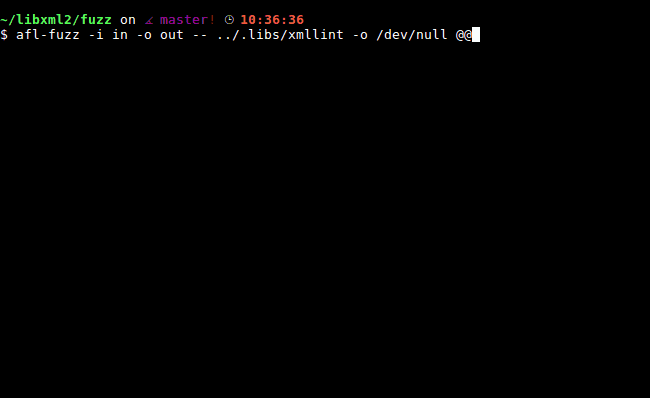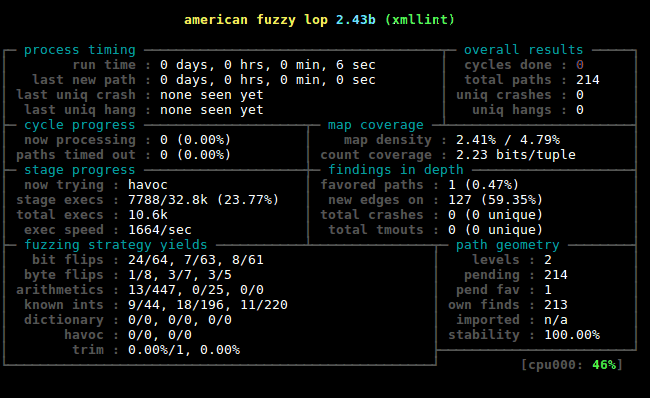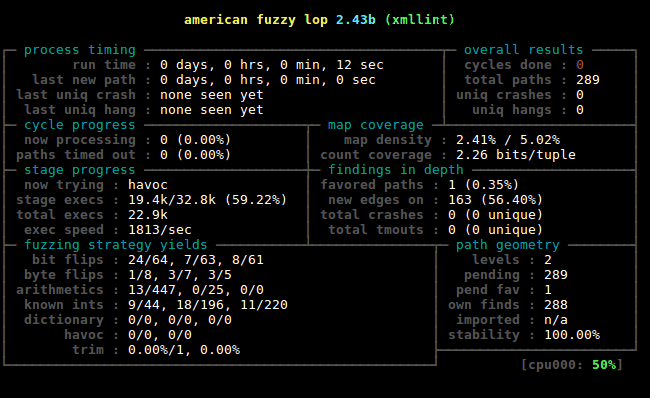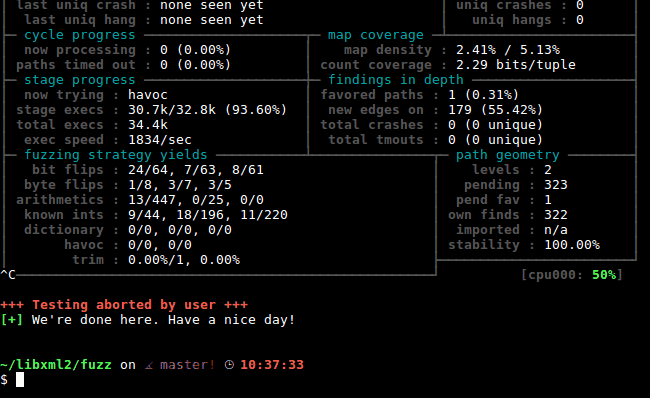
AFL将会不停地持续进行模糊测试,写入输入,并在./out/queue/中触发新的代码覆盖,在./out/crashes/中触发输入崩溃,在 /out/hangs/触发输入挂起。有关上图中的AFL运行状态的更多信息,请参阅:http://lcamtuf.coredump.cx/afl/status_screen.txt
使用LLVM libFuzzer进行模糊化
我们现在使用LLVM libFuzzer来对libxml2进行模糊测试。要开始模糊测试,你首先需要引入一个目标函数LLVMFuzzerTestOneInput,它从libFuzzer接收模糊测试输入缓冲区。代码看起来像下面这样。
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
DoSomethingInterestingWithMyAPI(Data, Size);
return 0; // Non-zero return values are reserved for future use.
}
针对libxml2的模糊测试,Google的fuzzer测试套件提供了一个很好的模糊测试示例函数。
// Copyright 2016 Google Inc. All Rights Reserved.
// Licensed under the Apache License, Version 2.0 (the "License");
#include
#include
#include "libxml/xmlversion.h"
#include "libxml/parser.h"
#include "libxml/HTMLparser.h"
#include "libxml/tree.h"
void ignore (void * ctx, const char * msg, ...) {}
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
xmlSetGenericErrorFunc(NULL, &ignore);
if (auto doc = xmlReadMemory(reinterpret_cast(data), size, "noname.xml", NULL, 0))
xmlFreeDoc(doc);
return 0;
}
在编译我们的目标函数之前,我们需要使用clang和-fsanitize-coverage = trace-pc-guard来编译所有依赖关系,以启用SanitizerCoverage覆盖跟踪。 为了启用
AddressSanitizer(ASAN)和UndefinedBehaviorSanitizer(UBSAN),捕获许多可能难以找到的错误,还需要使用-fsanitize = address,这是一个很不错的主意 。
$ git clone https://github.com/GNOME/libxml2 libxml2
$ cd libxml2
$ FUZZ_CXXFLAGS = “-O2 -fno-omit-frame-pointer -g -fsanitize = address,undefined -fsanitize-coverage = trace-pc-guard”
$ ./autogen.sh
$ CXX="clang++-5.0 $FUZZ_CXXFLAGS" CC="clang-5.0 $FUZZ_CXXFLAGS" CCLD="clang++-5.0 $FUZZ_CXXFLAGS" ./configure
$ make
在这篇文章里面,libFuzzer没有附带预编译的clang-5.0软件包http://apt.llvm.org/,所以你仍然需要自己检查并编译libFuzzer.a,参考文档在这里:http://llvm.org/docs/LibFuzzer.html#get-started,但这个文档可能会在不久的将来发生变化。
第二步是编译我们的目标函数,使用相同的标志,并将其与libFuzzer运行时和我们之前编译的libxml2进行链接。
$ clang++-5.0 -std=c++11 $FUZZ_CXXFLAGS -lFuzzer ./libxml-test.cc -I ./include ./.libs/libxml2.a -lz -llzma -o libxml-fuzzer
现在我们准备好运行我们的fuzzer了。
$ mkdir ./output
$ ./libxml-fuzzer ./output/
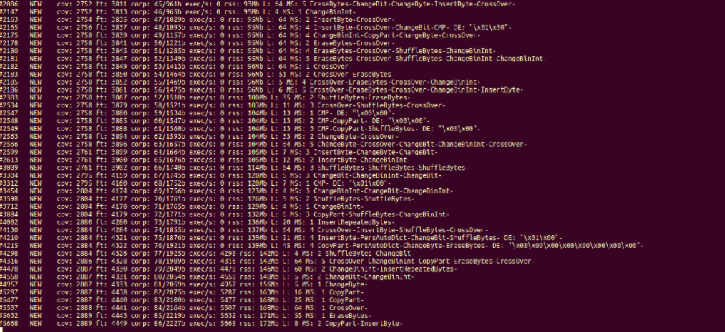
我们没有使用任何样例输入,所以libFuzzer会从生成随机数据开始,以便找到在libxml2目标函数中触发新代码路径的输入。触发新覆盖的所有输入都将作为示例文件存储在./output中。由于libFuzzer在进程中运行,所以如果发现了错误,它会保存测试用例并退出。在配置高端的笔记本电脑上,libFuzzer的单一实例每秒可以达到超过5000次执行,一旦开始生成具有更多覆盖范围的测试用例,速度就会减慢到2000左右。有关解释输出内容的更多信息,请参见:http://llvm.org/docs/LibFuzzer.html#output
创建语料库
如果你的目标是快速的执行模糊测试,比如每秒执行数百甚至数千次,那么你可以尝试生成一个基础语料库。即使使用更复杂的格式,如AFL作者Micha?Zalewski对JPEG文件进行模糊测试,使用覆盖引导模糊测试也可以做到这一点,但是为了节省时间,你应该获得尽可能小的应用程序的典型文件。文件越小,模糊测试越快。
当生成语料库时,AFL没有给出任何补充标记。只需要给出一个小的样本输入,例如“ ”作为XML示例,并像通常那样运行AFL。
使用libFuzzer可以有更多的标志来进行实验。例如,对于XML,你可能需要尝试使用“ -only_ascii = 1 ”。对于大多数格式的一个很好的技术是执行多个时间较短的运行,同时增加我们的Fuzzer的每一轮的最大样本量,然后合并所有结果以形成输出的语料库。
$ for foo in 4 8 16 32 64 128 256 512; do
./libxml-fuzzer -max_len=$foo -runs=500000 ./temp-corpus-dir;
done
$ ./libxml-fuzzer -merge=1 ./corpus ./temp-corpus-dir
使用这种方法,我们首先需要收集最大长度为4字节的有趣的输入,接下来运行分析4字节的输入,并将其用作8字节输入的基础等等。这样我们就可以用更小的输入来发现“简单”的覆盖范围,当我们移动到较大的文件时,我们就有了一个更好的初始设置。
为了获得这个技术的一些数字,我们用示例脚本进行了三次运行。

平均来说,运行语料库生成脚本在我们的笔记本电脑上花了大约18分钟。LibFuzzer在迭代结束时仍然经常发现新的coverage,其中-max_len大于8字节,这表明,对于这些长度,使用libFuzzer花费的时间也比较长。
为了比较,我们还采用了libFuzzer的默认设置,并运行了三次,大概用了18分钟。
$ ./libxml-fuzzer -max_total_time=1080 ./temp-corpus-dir
$ ./libxml-fuzzer -merge=1 ./corpus ./temp-corpus-dir;

从这些结果我们看到,我们运行的语料库生成脚本平均执行了更多的测试用例,生成了一组更大的文件,触发了比使用默认值生成的集合更多的覆盖和功能。这是由于libFuzzer使用默认设置生成的测试用例的大小导致的。以前的libFuzzer使用的是64字节的默认的-max_len,但是在编写libFuzzer时,刚刚更新了一个默认的-max_len为4096个字节。在实践中,由脚本生成的样本集已经非常有效地起作用了,但是在长时间连续模糊测试中,与默认设置相比,效果不同,并没有收集到数据。
生成语料库是一个令人印象深刻的壮举,但是如果我们将这些结果与W3C XML测试套件的覆盖范围进行比较,我们看到,将不同来源的示例文件包含在你的初始语料库中也是一个好主意,在你弄清目标之前,会得到更好的覆盖。
$ wget https://www.w3.org/XML/Test/xmlts20130923.tar.gz -O - | tar -xz
$ ./libxml-fuzzer -merge=1 ./samples ./xmlconf
$ ./libxml-fuzzer -runs=0 ./samples
#950 DONE cov: 18067 ft: 74369 corp: 934/2283Kb exec/s: 950 rss: 215Mb
将我们生成的语料库合并到W3C测试套件中将代码块覆盖率增加到18727,所以并不是那么多,但是我们仍然获得了83972个功能,从而增加了这些测试用例的总吞吐量。这两个改进最有可能是由于小样本触发了W3C测试套件未涵盖的错误条件。
“修剪”你的语料库
在将目标模糊测试一段时间后,最终会出现一大堆模糊测试文件。这些文件中的很多文件是不必要的,将它们“修剪”成更小的集合可以为你提供与目标相同的代码覆盖。为了实现这一点,这两个项目都提供了语料库最小化工具。
AFL为你提供了可用于最小化语料库的afl-cmin shell脚本。对于上一个示例,为了最小化在./out目录中生成的语料库,你可以将生成的最小化的文件集放在./output_corpus目录中。
$afl-cmin -i ./out/queue -o ./output_corpus -- ./.libs/lt-xmllint -o /dev/null @@
AFL还提供了另一个工具afl-tmin,可用于最小化单个文件,同时可以保持前面看到的相同的覆盖率。请注意,在一大堆文件上运行afl-tmin可能需要很长时间,因此在尝试afl-tmin之前,首先要使用afl-cmin进行几次迭代。
LibFuzzer没有提供外部“修剪”工具 – 它具有内置的称为merge的语料库最小化功能。
$./libxml-fuzzer -merge=1

令人惊讶的是,没有字典的运行结果与第一次运行的推荐字典的测试结果没有显著的差异,但是使用“真实”字典,在运行期间发现的覆盖量就发生了巨大变化。
字典真的可以改变模糊测试的效果,至少在短时间内是这样的,所以他们值得去做。Shortcuts,像libFuzzer推荐的字典,很有帮助,但你仍然需要额外的手动操作来利用字典中的潜力。
模糊测试实验
我们的目标是在几台笔记本电脑上做一个在周末长时间运行的模糊测试。我们运行了两个AFL和libFuzzer的实例,对上面的例子进行模糊测试。第一个实例是没有任何语料库的,第二个是W3C XML Test Suite的修剪语料库。然后可以通过执行所有四组的最小化语料库的运行来比较结果。这些fuzzer的结果不是直接可以比较的,因为两个fuzzer都使用不同的仪器来检测执行的代码路径和特征。libFuzzer测量两件事情,用于评估新的样本覆盖率,块覆盖率,被访问的隔离代码块和特征 覆盖,这是不同代码路径特征(如代码块和命中次数之间的转换)的组合。AFL不对观察到的覆盖率提供直接计数,但在我们的比较中我们使用总体覆盖图密度。地图密度表示我们所击中的多少个分支元组,与覆盖地图可以容纳多少个元组成比例。
我们的第一次运行并没有按预期的那样进行。2天7小时后,我们发现了大文件使用确定性模糊测试的缺点。我们的 afl-cmin最小化语料库包含了一些超过100kB的样本,导致AFL在加工之后减慢了运行速度,仅次于第一轮的38%。AFL需要几天的时间才能通过单个文件,我们在样本集中有四个,所以我们决定在我们删除超过10kB的样本后重新启动实例。可悲的是,星期天晚上11点,“备份第一”不是我们头脑中的第一件事,AFL的数据被意外覆盖,所以没有第一个比较的结果。我们设法在中止之前保存AFL UI。
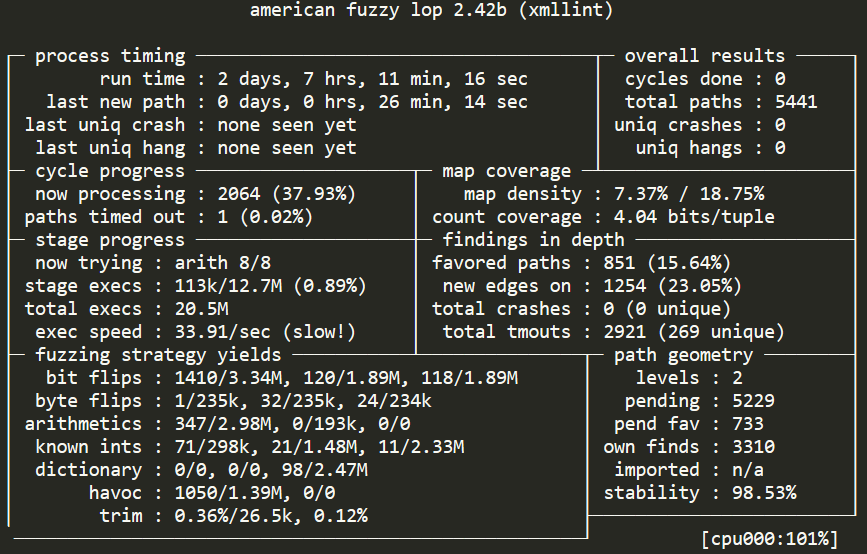
模糊测试两天的完整结果可以从下面的图表中找到。

我们实际上从来没有试图把这些fuzzer相互对抗。即使在我们的实验中,这两个fuzzer结果都是惊人的。从W3C样本开始,由libFuzzer测量的发现覆盖率之间的差异只有1.4%。同时这两个fuzzer都发现了几乎相同的覆盖。当我们合并了四个运行的所有收集的文件和原始的W3C样本时,组合覆盖率仅比libFuzzer单独发现的覆盖率高出1.5%。另一个值得注意的是,即使在2天之后,没有初始样本,libFuzzer或AFL都没有发现比以前的演示更多的覆盖率,在10分钟内反复产生了一个语料库。
我们还使用W3C样本在libFuzzer模糊测试运行期间生成了覆盖发现的图表。
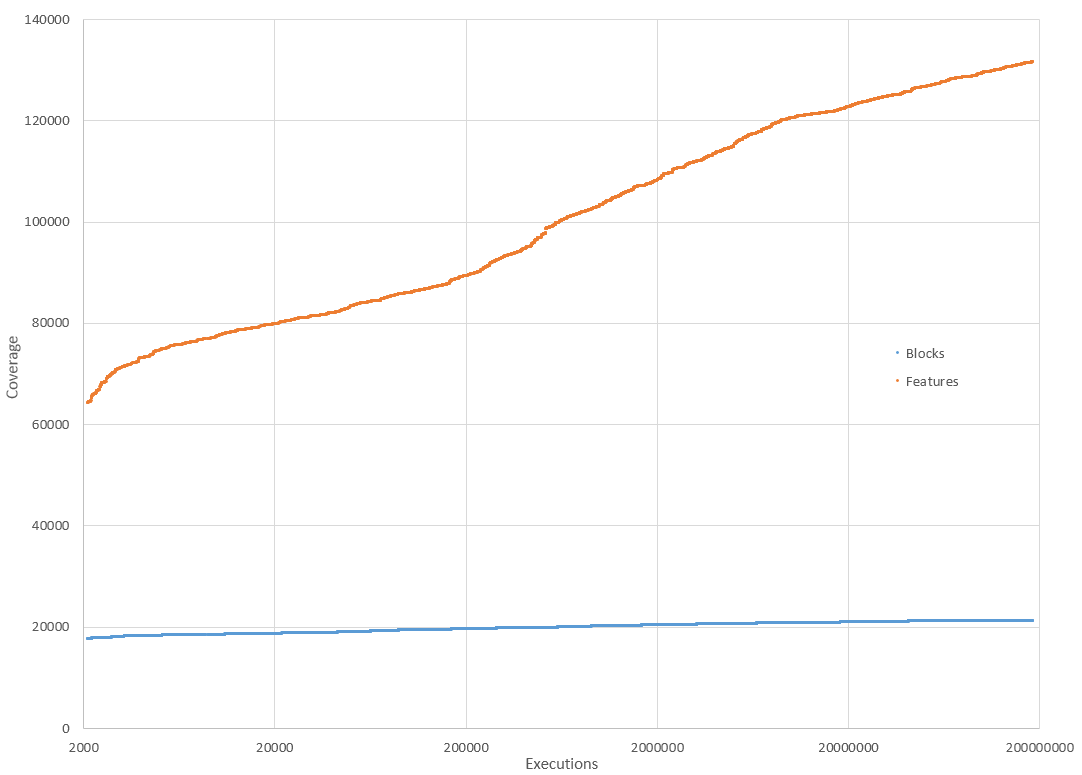
我应该使用哪一个?
正如我们上面的详细说明一样,AFL使用起来非常简单,可以几乎无需安装即可开始使用。AFL负责发现错误处理以及与崩溃类似的东西。但是,如果你没有可用的命令行工具,如xmllint,并且需要编写一些代码来启用模糊测试,通常使用libFuzzer来获得卓越的性能。
与AFL相比,libFuzzer内置了数据清洗功能的支持,例如AddressSanitizer和UndefinedBehaviorSanitizer,可以帮助你在测试过程中发现微妙的错误。AFL对清洗功能有一些支持,但根据你的目标,可能会有一些严重的副作用。AFL的文档中建议在没有清洗功能的情况下运行模糊,并且使用清洗功能构建分开的运行输出队列,但没有实际的数据可用来确定该技术是否可以捕获与ASAN启用的模糊测试相同的问题。有关AFL和ASAN的更多信息,你可以从AFL的源码中找到docs/notes_for_asan.txt。
然而,在许多情况下,运行两个fuzzer是有意义的,因为它们的模糊测试,碰撞检测和覆盖策略略有不同。
如果你最终使用了libFuzzer,那么你应该参考一下Google编写的非常不错的 libFuzzer教程。

