在前面的话
车联ROM系统是搭载腾讯TAS智能车载系统。系统搭载在路畅华阳合作伙伴硬件平台上,实现了车机联网,实现了智能语音、网络音乐、实时路况、在线升级等特有功能,并且延伸了腾讯的社交基因,微信和QQ社交能力在乘驾上得以延伸。
村长下面讲的故事,就是围绕车联ROM中智能语音APP展开,请各位看官了解~

一、村长为啥干这事儿
村长是一名腾讯移动客户端测试工程师。跟其他的测试同学一样,从需求、计划、用例设计评审、执行、报告、发布按部就班的进行了自己本职的工作,比如说,车联ROM中语音APP的测试。但是有一天村长回头看自己的语音APP的测试用例,发现测试用例越来越多,测试回归验证时间周期不断加长,同时,仍旧有用户反馈的漏侧等各种问题。
她不禁思考:测试用例真的“足够好”么?真的可以反应真实用户的使用场景么?回归测试时真的需要去运行如此多的测试用例么?
有了这样的疑问和困惑,她去查找很多资料,突然一次例会上交流让她有了新灵感:产品同学对于新功能都会加上埋点以看到用户对新功能的使用反馈,进而对产品设计进行调整。
测试:为何不从用户使用角度来对用例进行划分优化呢?
二、村长想怎么干
在腾讯,倡导的理念就是“一切以用户的价值为依归”。那么在以用户价值为导向的理念下,产品、运营都是从用户使用角度出发,为何测试不能也从用户数据上做文章呢?
下一个问题?这个文章怎么做?怎么指导测试用例?那就需要从用户数据入手,抓住用户主要使用场景,进而优化测试策略,最终又通过版本发布反向验证方式的可行性。
基础思路:基础数据提取——基础数据清洗——基础数据整合——用例修改——版本发布&用户反馈总结
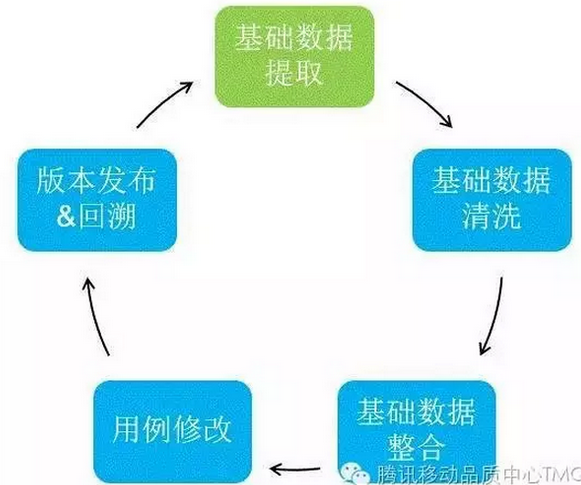
测试用例优化思路
三、村长实际操作
说干就干,说着村长就撸袖子挽裤腿的去干活了。
步骤1:基础数据提取
村长先着手查看运营数据。看到运营数据后,村长脸上写了大大的“蒙圈”。运营数据那么多,具体要从哪些数据里来提取所需信息呢?下面先看看用户数据基本有哪些:
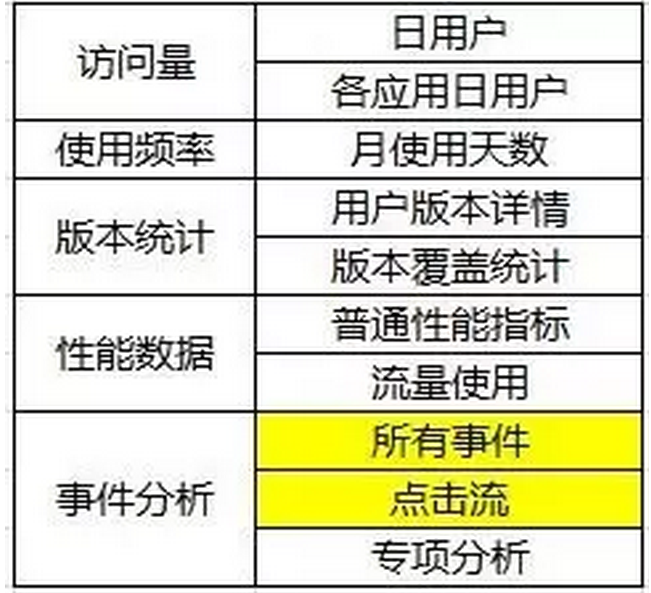
图片3
结合项目特点:村长选取了所有事件&点击流作为分析基础数据;
为什么选取这两个基础数据:
1. 抓住主要工作流,这里就是主要是用户输入流,保证80%以上的场景可覆盖;
2. 其他20%事件可以作为补充用例,可以分不同版本&情况来覆盖;
最终语音APP选取出来的数据字段是这样的,包含了日期、id、用户名、版本号、用户语音识别文本、语音调用应用类型等等。
基础数据ready,怎么分析呢?
步骤2:基础数据清洗
目的:清除无用数据,为下一步数据整合提供输入;
村长拿到基础数据后,哭的心都有了,数据不但多,而且杂,中间夹杂了不少无效数据,也就是“脏数据”。这些数据肯定不能直接整合使用的。那么哪些是不需要的“脏数据”?怎么清洗“脏数据”呢?
通过观察,语音APP中上报字段中,先去除关键字段为空的数据,表现为下面几个字段:
1.SessionID为NULL;
2. SpeechID为NULL;
3. Speechtext为NULL;
在拿到的数据样本中,工具语音会话4499次,脏数据共占比941次,其中840次是操作了语音但是实际并未声音输入,可能就是用户误操作的行为。同时意外发现埋点上报一个BUG,即sessionID=NULL&speechID =NULL,但是speechtext非空(QA中彩蛋,发现这个BUG后,村长默默的乐了)。
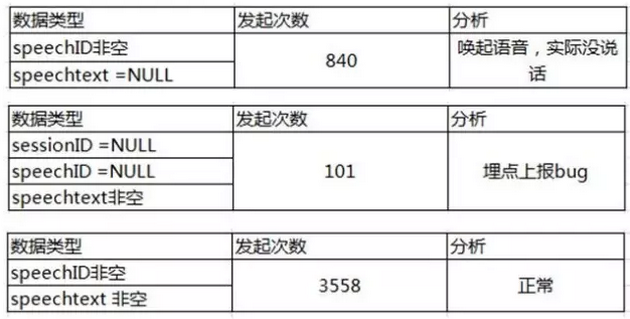
捕获3
最终,剩余的3558次语音会话,就是有效样本数据。Binggo~~有了阶段性成果~继续加油
步骤3:基础数据整合
目的:按照所需处理格式,对基础数据进行重新整合,分类整理。
村长拿到基础数据清洗后结果,问题又来了:怎么归纳整理成修改用例的输入?归纳整理的结果是什么样的?
答案就是:结合需求开搞。啊呸~说的容易,也不举个例子。呃,各位村民,别急,村长慢慢给你说。
话说从软件研发起,就有传说中的需求,也就是指导开发实现的文档。这个文档说明了软件实现的功能点、软件性能指标等方方面面。也就是有了这么一个神圣的文档,测试同学就有据可依去跟开发GG直面PK,是否完成需求的实现等等。
语音APP也有语音需求,如语音需求总表,详细说明了需要调用的APP,具体的每个话术、每个结果状态等等。
在村长的项目中,语音有几方面的话术:导航音乐电话节目等等。每个主功能上又会对应具体的话术,如“打电话给张三”“打电话给张三的联通号码”等等详细话术的要求。村长灵机一动,根据每个类型的的话术进行统计。从统计结果上看,导航类的语音请求最多,详细的语料展示如下。
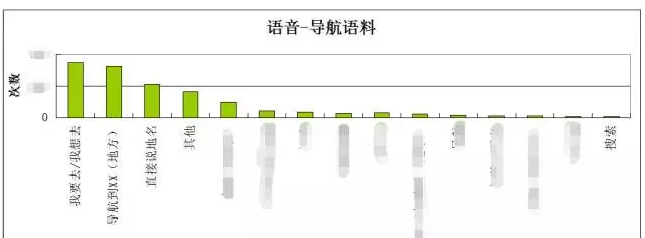
拿到统计结果,村长粗略核对了下产品详细需求,发现39类导航语音话术中,实际用户使用的只有7种。这7种语料中,“我要去我想去”+“导航到XXX”占比最高,也就是用户在发起路线规划的需求是最高的。于此同时,可以看出用户直接说出地名占比也较高。产品层面分析:发起语音时,产品页面会有文字等方面的提示,也就是这些语料占比高的原因。另一些问题:沿途查找导航过程中查询时间路况等方面,均未有用户使用。
分析到这里,村长在想下一步,怎么来指导用例的修改呢?是全面替换原有用例么?
步骤4:修改用例
目的:使用基础数据分析结果,来指导测试用例的编写&修改,最终达到保证用户场景80%的使用。
上文提到了,已经得到了基础统计结果&分析结果。村民一般反馈,那直接用这些数据去修改测试用例得了,还墨迹啥。不,其实还是需要对用例区别对待。不可以全部只按照用户反馈修改,不可以不参考用户反馈修改。这句话很拗口,说白了就是:需要对原有用例按照用户实际路径进行修改,并且修改优先级。在语音APP修改时,按照测程进行重新规划。
原来case,因为不清楚用户实际使用频次,所以所有的语料都必须全量覆盖测试。新case,修改一部分case,并且重新按照用户使用频次标注优先级,在测程中得以优化。
如下语音唤起导航case:原本P1-case:175条。新修改P1-case:31条。同时将原本的“回家去公司查找XX地点放大缩小地图”类case归类为P4,即统计中用户并未使用过的语料。


步骤5:版本发布&用户反馈总结
目的:修改后用例,需要在真正版本发布后,对用户反馈进行归纳整理,选出语音模块漏侧case,完善测试用例和场景。
村长就根据分析出结果,修改后的用例,对V2.1.1版本进行语音APP集成测程重新规划,并最终发布以观察效果。具体效果待后续展示。
四、村长实践后效果
村长在实际实践中,对比了V2.1.0&V2.1.1的的case量、测试耗时、漏侧等相关数据,结果如下图所示,对case量进行调整,case级别进行调整后,实际上用户反馈漏侧也没有任何变化。看来这么干是可行的。
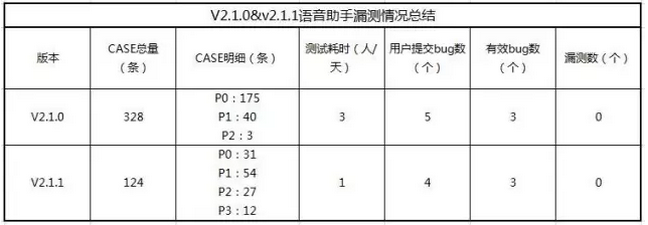
图片5
五、村长后续的打算
做完语音测试用例优化后,村长想从后续几个方面去优化推广:
打算1:统计数据,从运营平台上自动化获取;
打算2:统计数据中,数据整合&数据清洗自动化处理。
打算3:推广到其他测试周期长应用中~
以上是村长在实际测试中,从用户数据逐步提取关键信息,最终指导测试用例删减的故事,希望大家能够喜欢&提出建议和意见。

