知识图谱是一把开启智能机器大脑的钥匙,能够打开Web 3.0时代的知识宝库。本文将从知识图谱的概念、架构、关键技术、应用领域以及一些需要注意的问题等方面,带大家走进知识图谱的世界。
知识图谱是什么?
A knowledge graph consists of a set of interconnected typed entities and their attributes.
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。
通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。
知识图谱这个概念最早由Google提出,主要是用来优化现有的搜索引擎。不同于基于关键词搜索的传统搜索引擎,知识图谱可用来更好地查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。比如在Google的搜索框里输入科比的时候,搜索结果页面的右侧还会出现科比相关的信息比如出生年月,家庭情况等等。
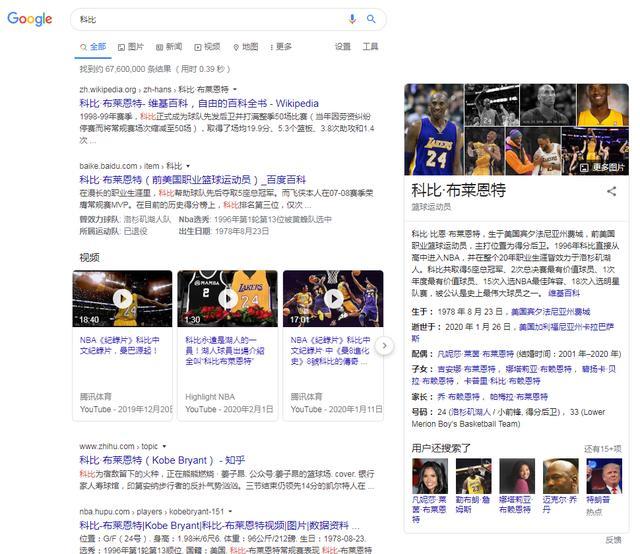
在知识图谱里,我们通常用“实体(Entity)”来表达图里的节点、用“关系(Relation)”来表达图里的“边”。实体指的是现实世界中的事物比如人、地名、概念、公司等,关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”等等。
通过上面这个例子,读者应该对知识图谱有了一个初步的印象,其本质是为了表示知识,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。
知识图谱的表示
那什么叫多关系图呢? 图是由节点(Vertex)和边(Edge)来构成,但这些图通常只包含一种类型的节点和边。但相反,多关系图一般包含多种类型的节点和多种类型的边。比如下图因为图里包含了多种类型的节点和边。这些类型由不同的颜色来标记。
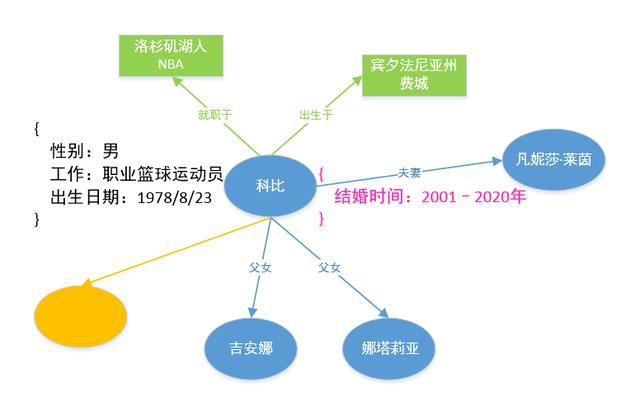
当一个知识图谱拥有属性时,我们可以用属性图(Property Graph)来表示,如上图,科比和凡妮莎是夫妻,他们的结婚时间是2001年到2020年,其中结婚时间就可以作为关系的属性,类似的,科比也有自己的属性,比如性别、出生日期等。这种属性图的表达很贴近现实生活中的场景,也可以很好地描述业务中所包含的逻辑。
除了属性图,知识图谱也可以用RDF来表示,它是由很多的三元组(Triples)来组成。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。目前来看,RDF主要还是用于学术的场景,在工业界我们更多的还是采用图数据库(比如用来存储属性图)的方式。
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。
知识抽取
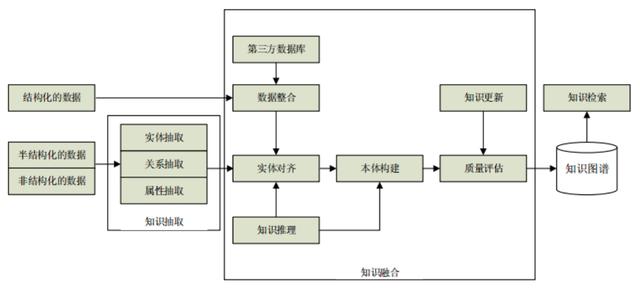
知识图谱的体系架构是其指构建模式结构,如下图所示。知识图谱的构建过程需要随人的认知能力不断更新迭代。
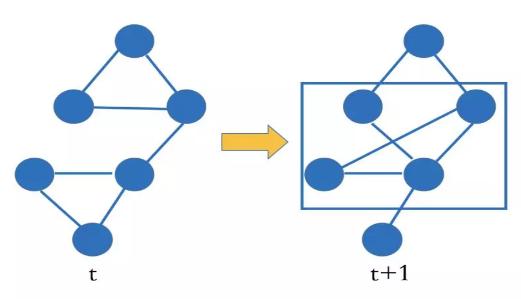
所谓的静态关系图谱,意味着我们不考虑图谱结构本身随时间的变化,只是聚焦在当前知识图谱结构上。然而,我们也知道图谱的结构是随时间变化的。
在下面的图中,我们给出了一个知识图谱T时刻和T+1时刻的结构,我们很容易看出在这两个时刻中间,图谱结构(或者部分结构)发生了很明显的变化。那怎么去判断这些结构上的变化呢? 感兴趣的读者可以关注我,后面会持续更新知识图谱相关技术栈,本文先不做过多讨论。
回到知识图谱的体系架构那张图,知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同的数据源中抽取出来。对于垂直领域的知识图谱来说,它们的数据源主要来自两种渠道:一种是业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是半结构/非结构化的数据。
前者一般只需要简单预处理即可以作为后续AI系统的输入,但后者一般需要借助于自然语言处理等技术来提取出结构化信息。比如在上面的搜索例子里,科比和凡妮莎的关系就可以从非结构化数据中提炼出来,比如维基百科等数据源。
信息抽取的难点在于处理非结构化数据。从一段非结构化的文本中,需要抽取出实体、关系和属性。例如下图是从维基百科拿到的科比文本信息:
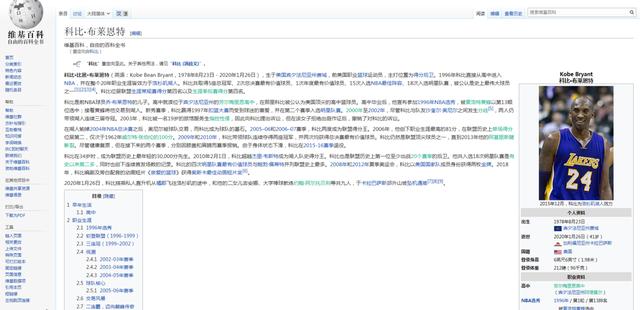
要从海量文字中,构建出类似文章开头的那种知识图谱,需要涉及几个方面的自然语言处理技术:
- 实体命名识别(Name Entity Recognition)
- 关系抽取(Relation Extraction)
- 实体统一(Entity Resolution)
- 指代消解(Coreference Resolution)
首先是实体命名识别,就是从文本里提取出实体并对每个实体做分类/打标签:比如从上述文本里,我们可以提取出实体-“科比·布莱恩特”,并标记实体类型为 “人”;我们也可以从中提取出“宾夕法尼亚洲费城”,并标记实体类型为“位置”。
这种过程称之为实体命名识别,这是一项相对比较成熟的技术,有一些现成的工具可以用来做这件事情。其次,我们可以通过关系抽取技术,把实体间的关系从文本中提取出来,比如实体“科比”和“宾夕法尼亚洲费城”之间的关系为“出生于”等等。
另外,在实体命名识别和关系抽取过程中,有两个比较棘手的问题:一个是实体统一,也就是说有些实体写法上不一样,但其实是指向同一个实体。比如“科比·比恩·布莱恩特”和“科比”表面上是不同的字符串,但其实指的都是科比这个人,需要合并。
实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(Sparsity);另一个问题是指代消解,也是文本中出现的“他”, “它”, “她”这些词到底指向哪个实体。
实体统一和指代消解问题相对于前两个问题更具有挑战性。
大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。
通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
作为科普性的文章,本文的目的是带大家入门,关于知识图谱更深入的知识抽取、知识表示、知识融合以及知识推理技术,篇幅有限,将作为下一篇的重点内容,供大家参考。
知识图谱的搭建
首先需要说明的一点是,搭建一个知识图谱系统最重要的核心在于对业务的理解以及对知识图谱本身的设计,这就类似于对于一个业务系统,数据库表的设计尤其关键,而且这种设计绝对离不开对业务的深入理解以及对未来业务场景变化的预估。 当然,在这里我们先不讨论数据的重要性。
一个完整的知识图谱的构建包含以下几个步骤:
- 定义具体的业务问题
- 数据的收集 & 预处理
- 知识图谱的设计
- 把数据存入知识图谱
- 上层应用的开发,以及系统的评估。
对于定义具体业务问题,要明确的一点是,对于自身的业务问题到底需不需要知识图谱系统的支持。因为在很多的实际场景,即使对关系的分析有一定的需求,实际上也可以利用传统数据库来完成分析的。所以为了避免使用知识图谱而选择知识图谱,以及更好的技术选型,以下给出了几点总结,供参考。

下一步就是要确定数据源以及做必要的数据预处理。在这里我只说明的一点,并不是所有相关的数据都必须要进入知识图谱,对于这部分的一些决策原则在后续的文章中会有比较详细的介绍。
知识图谱的设计是门艺术,作为程序媛,我把它交给更专业的人员。存储上我们要面临存储系统的选择,但由于我们设计的知识图谱带有属性,图数据库可以作为首选。但至于选择哪个图数据库也要看业务量以及对效率的要求。
如果数据量特别庞大,则Neo4j很可能满足不了业务的需求,这时候不得不去选择支持准分布式的系统比如OrientDB, JanusGraph等,或者通过效率、冗余原则把信息存放在传统数据库中,从而减少知识图谱所承载的信息量。 通常来讲,对于10亿节点以下规模的图谱来说Neo4j已经足够了。
做完这些,就可以来到我们最熟悉的环节,进行应用的开发(撸代码)了。
知识图谱的应用
知识图谱应用的前提是已经构建好了知识图谱,也可以把它认为是一个知识库。当我们执行搜索的时候,就可以通过关键词提取以及知识库上的匹配可以直接获得最终的答案。
这种搜索方式跟传统的搜索引擎是不一样的,一个传统的搜索引擎它返回的是网页、而不是最终的答案,所以就多了一层用户自己筛选并过滤信息的过程。
知识图谱的应用主要集中在搜索与推荐领域:
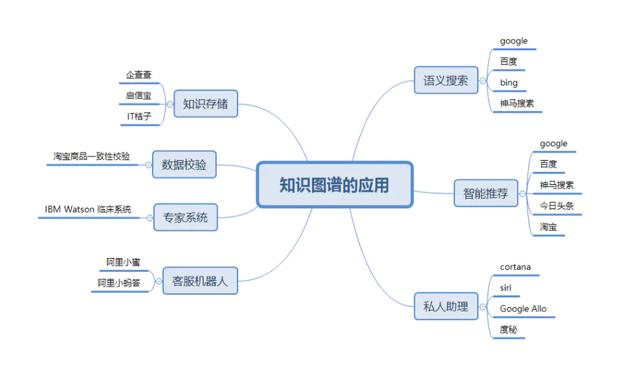
在语义搜索这一块,知识图谱的搜索不同于常规的搜索,常规的搜索是根据keyword找到对应的网页集合,然后通过page rank等算法去给网页集合内的网页进行排名,然后展示给用户;基于知识图谱的搜索是在已有的图谱知识库中遍历知识,然后将查询到的知识返回给用户,通常如果路径正确,查询出来的知识只有1个或几个,相当精准。
问答系统这一块,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。
实践上的几点建议
首先,知识图谱是一个比较新的工具,它的主要作用还是在于分析关系,尤其是深度的关系。所以在业务上,首先要确保它的必要性,其实很多问题可以用非知识图谱的方式来解决。
知识图谱领域一个最重要的话题是知识的推理。而且知识的推理是走向强人工智能的必经之路。但很遗憾的,目前很多语义网络的角度讨论的推理技术(比如基于深度学习,概率统计)很难在实际的垂直应用中落地。其实目前最有效的方式还是基于一些规则的方法论,除非我们有非常庞大的数据集。
最后,还是要强调一点,知识图谱工程本身还是业务为重心,以数据为中心。不要低估业务和数据的重要性。如果本篇对你有帮助,点个赞互相鼓励一下吧!
参考:
- 《知识图谱技术综述》 徐增林, 盛泳潘, 贺丽荣, 王雅芳
- 知识图谱基础(一)-什么是知识图谱
- 这是一份通俗易懂的知识图谱技术与应用指南
作者:臧远慧
简介:就职于中科星图股份有限公司(北京),研发部后端技术组。个人擅长 Python/Java 开发,了解前端基础;熟练掌握 MySQL,MongoDB,了解 Redis;熟悉 Linux 开发环境,掌握 Shell 编程,有良好的 Git 源码管理习惯;精通 Nginx ,Flask、Swagger 开发框架;有 Docker+Kubernetes 云服务开发经验。对人工智能、云原生技术有较大的兴趣。

