引言
“网络就像wifi,没有故障的时候,就没有人意识到它的存在”,这句话有无数的翻版,但是对于网络工程师来说,这就是现身说法。

由于即便是在上千人的公司,网络工程师的人数也仅仅是个位数,所以他们的工作也鲜为人知 。
“网络是不是有问题?”这句话几乎成了所有SRE排错时的口头禅,如果这个时候网络工程师表示沉默,或者无法拿出足够的证据,那背锅几乎是无疑的。
如何让网络环境的运行状态更加透明?如何在每次业务故障的时候自证清白?这不仅是基础服务团队要关心的内容,更是整个技术团队想要了解的黑匣子。
监控
网络设备存活监控
对于SRE来说,需要监控程序是否正常;对于主机组来说,需要监控服务器硬件是否正常;对于网络来说,我们首先需要关心网络设备是否可达。当一台TOR不可达时,基本上预示着会有一片服务器不可达,业务的痛感是相当强烈的。
网络设备的监控最好和业务监控系统尽量解藕,因为网络故障极有可能引发业务系统异常,如果恰巧导致的是业务的监控系统异常,那网络设备的告警将失去可靠性,且不说“监控不准”这个锅是谁的,这种局面会让网络工程师Trouble Shooting时陷入被动,延长了故障时间。
每一个网工在走出校门的那一刻,都已经具备基本的编程基础, 况且交换机的数量和服务器的数量有着量级上的差别,所以如果你能看懂几句python,100+的python代码即可搞定一个简易的设备存活监控的程序,Github中可搜索 NodePingManage 就是一个很好的例子,还可以通过多点部署来消除单点故障。有了这类工具, 从此全网的各个角落的可达性终于明了, 漆黑的网络环境,似乎反射出了一丝光明。
设备日志监控
设备存活告警虽然可以预警很多异常,并且准确度很高,但是对于冗余性做得比较好的网络,能Ping通并不代表完全没问题,此时,细心的网络工程师会去看日志,这里可以反映出更多细节。对于万台服务器规模,网络设备的数量也就千台,但是逐台查看日志,人肉判断是否有异常,那简直是场噩梦。
《日志告警》程序就成为网络工程师们居家旅行必备之良品,只需要一台Syslog服务器,部署一个日志监控程序,当发现日志中出现特殊关键字,触发邮件+短信告警即可。这么高大上的工具当然需要更多的编程技巧,150+ python代码才能搞定。Github中类似的解决方法有很多,搜索LogScanWarning即可得到一个示范案例。
从此你可以在业务无感的情况下,发现网络中的异常, 例如:风扇转速异常/电源模块故障/ospf邻居状态抖动/端口flapping/有黑客在爆破我的设备/设备硬件parity error/模块收发光异常/Kernel报错等等。优秀的网络工程师可以在故障发生时快速定位,牛X的网络工程师可以在故障发生前就消除隐患,防范于未然。
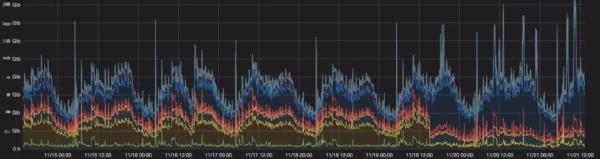
流量监控
高速公路铺得再好,也架不住车多人多。确保网络顺畅,品质优良,没有丢包,延时稳定也是网络工程师的职责 ,此时流量监控就成了刚需。
业务的飞速发展体现在网络层面就是DC内流量上涨/DCI流量上涨/IDC出口流量上涨/专线流量上涨,流量监控可以准确掌握业务的高峰和低谷,当线路需要扩容时,带宽使用率是老板参考的重要数据。一般情况下线路中的流量超过50%即可发起扩容,因为这意味着当备份链路down之后,主线路将出现拥塞。
接口error监控
接口的Error包监控和流量监控一样,均可以通过snmp采集,OID:ifOutErrors,ifInErrors , Error包出现增量会直接影响业务的服务质量,一旦发现需要优先处理,否则业务会拎着一堆TcpTimeOut指标找上门来。
当然,可以通过snmp采集的信息还有很多,例如:设备的CPU/内存/温度/防火墙的Session等,掌握这些信息对了解设备的工作环境也颇有益处,如果你要做一个自动化巡检工具,那么这些指标必不可少。市面上提供网络监控的软件有很多,例如:Falcon / Zabbix / Solarwinds / Cacti / Nigos等,有开源的也有收费的,功能类似,此处不加赘述。
制造自动化运维工具
第一章中的组合拳打完之后,基本上不会出现“意料之外的故障”,所有的异常都应该有据可查,当SRE莫名其妙提出对网络环境的质疑时,你应该早已心中有谱。
但是网络工程师的工作并非只有救火,日常运维工作中,经常需要配合业务发展做一些线上变更/ 机房扩建/业务类故障排查等。作为一名“懒惰”的网络工程师,程序可以帮忙点什么忙呢?
UserDevice Tracker
这个名词借用于Solarwinds套装中的一个组件,直译为“用户设备追踪器” , 在中小型企业网运维中,经常会有这样的需求:
- 知道服务器的IP,请问连接在交换机的哪个口?
- 知道交换机的某个端口,请问连接的服务器的IP是多少?
- 给你一台服务器的MAC地址,怎么知道在哪个交换机的哪个口?
大型互联网公司一般会有CMDB或者网络管理平台来记录这些信息, 但是如果你是一家中小型企业的网管,没有运维研发团队做支持,并且还在沿用二层的环境(服务器网关在核心设备),那就比较费劲了。以上几个问题其实归根到底是要捋清楚三个要素的对应关系:PORT<>MAC<>IP 。
举个例子:
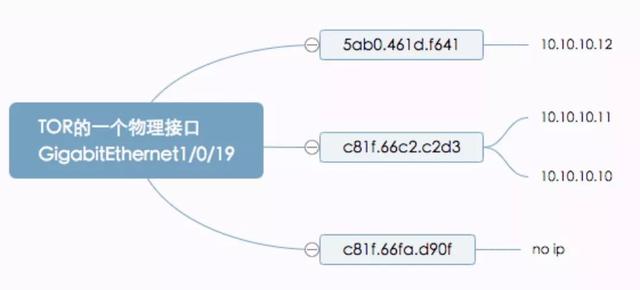
一台交换机有多个物理接口,一个物理接口下可以有多个MAC,一个MAC可以对应多个IP,或者不对应任何IP。有了这个基本的模型,只需要做两件事情即可找到全网设备这三元素的对应关系。
首先去服务器直连的交换机获取MAC表(即MAC<->PORT),然后再去服务器的网关设备获取ARP表(即IP<->MAC),这两张表根据MAC地址作为唯一主键即可得到PORT <->MAC<->IP的对应关系。
信息的获取可以通过模拟登陆或者OID采集均可,Github中也有很多类似的代码可供参考,有了这个对应关系,即便没有CMDB,你依然可以快速定位想要的信息, 普通网工查找这个信息需要5分钟, 而你只需要5秒钟。
网络设备北向接口的二次封装
日常网络运维工作中,经常会有一些 “简单重复劳动”,例如:为某个接口划分Vlan/给某台设备添加一条指向主机的路由等, 这些操作既没有科技含量,还占用了工程师宝贵的时间,更要命的是再简单的人肉操作,重复的次数只要足够多,总有失误的时候,正所谓“常在河边走,哪有不湿鞋”,但是在这种问题上犯错误简直是对职业生涯的抹黑,如此“鸡肋”的工作怎么才能干得漂亮?
以《自动划分交换机接口Vlan》的功能为例, 如果有一个工具只需要你提供三个参数:设备IP/端口/vlan编号, 就能自动登陆设备把特定接口划分到指定Vlan,那岂不是美哉。
没错!你需要的是一个对设备封装后的接口, 现在多数网络设备厂商都会提供自己的API,无论是NETCONF还是RESTful,只要读懂了使用手册,即可通过程序轻松变更设备的配置,甚至你可以用更加”接地气”的方法,用程序“模拟登陆”设备 ,虽然这个方法在效率上比不过NETCONF和RESTful API,但是在通用性上那简直无敌,因为没有哪个厂商的设备不支持SSH或者TELNET的。
有了这个理论基础,一些简单的网络上的操作就可以通过自己封装的接口来实现变更,甚至可以把变更的权限交给业务,只要业务提交的请求是合法的,变更可立即上线生效。
此时,肯定会有人大惊失色!把网络设备的权限交给业务,这样真的好么?万一改坏了怎么办……所有的疑惑都是正常的,同时也都是有解的。
还是以《自动划分交换机接口Vlan》举例子,你可以限制程序执行的内容,你可以规定交换机只能是TOR不能是CSW,你可以约束接口只能是Access不能是Trunk,你可以限定被操作的接口下流量必须为0bps,以避免误操作影响到业务,你可以通过动态Token保证接口的安全,你可以要求必须提供接口下现存的MAC以定位接口的位置,你还可以对调用者加白名单,另外,操作成功后还需要有短信+邮件反馈操作后的结果,等等……
所有的考量都可以固化为代码规则,只有程序是最忠实的执行者。接口可以提供7*24小时全年无休的服务,而人的精力是有限的,用程序去应对业务那些简单有规律的需求,节省出工程师宝贵的时间来思考人生,这才是网络工程师自动化运维之路的正道。
总结
以上,是笔者结合自身工作经历总结的一些心法,写代码对于网络工程师来说确实有些难度,但是只要跨过这道坎,你会得到更多富裕的时间来扩展自己的专业道路,谨以此文,希望能抛砖引玉为自动化网络运维尽绵薄之力。

