虚拟化是一个广义术语,通常是指计算元件在虚拟的基础上而不是真实的基础上运行,是一个为了简化管理,优化资源的解决方案。服务器虚拟化则是一项用以整合基于x86服务器,来提高资源利用效率和性能的技术。
本文从企业业务系统和管理角度出发,着重分析研究了X86技术架构下,虚拟网卡与SR-IOV、NUMA、虚拟磁盘格式相应的特点,并探索了不同应用场景下的资源划分和性能优化方案,希望能够通过多应用系统下的实践和最优配置,来提高X86服务器的性能和资源利用效率。
1、x86虚拟化两种常见的架构
对于x86虚拟化,有两种常见的架构:寄居架构和裸金属架构。寄居架构将虚拟化层运行在操作系统之上,当作一个应用来运行,对硬件的支持很广泛。相对的,裸金属架构直接将虚拟化层运行在x86的硬件系统上,可以直接访问硬件资源,无需通过操作系统来实现硬件访问,因此效率更高。
Vmware Workstation和VMware Server都是基于寄居架构而实现的,而VMware ESX Server是业界第一个裸金属架构的虚拟化产品,目前已经发布了第五代产品。ESX Server需要运行在VMware认证的硬件平台上,可以提供出色的性能,完全可以满足大型数据中心对性能的要求。本文主要论述的也是基于X86裸金属架构下的服务器的资源划分和性能优化问题。
2、x86虚拟化资源划分的三个层面
服务器的资源划分简单的讲,包括网络、计算、存储三个层面。每一个虚机都在其连通的网络中,承担一定的计算任务,把计算后的数据存储下来供业务使用。
2.1 网络层面
从网络层面来说,X86物理机使用的是物理的网卡,连接的是物理的交换机。在一台X86被划分成多个VM虚机后,就诞生了虚拟网卡和虚拟交换机。这样在虚拟和物理网络之间就产生了流量传输与交互。如图1所示:
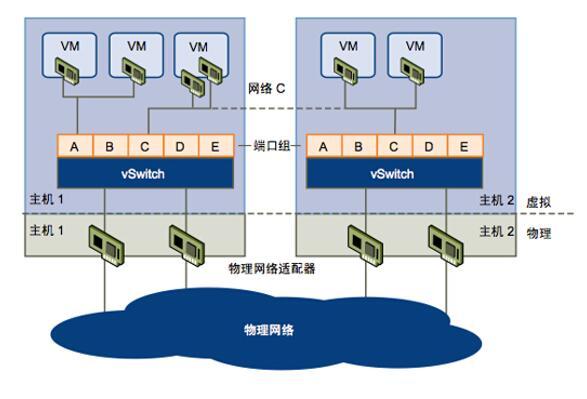
图1:虚拟网络和物理网络
同一台物理机上划分的VM有同一网段和不同网段之分,再根据虚机之间的网络流量是否经过物理网卡,具体可分为四种不同的情况:
第一种情况,比如某业务系统的VM在同一主机的同一网段,则虚拟机之间网络流量不经过主机物理网卡,其最大网络流量为7.6GB。(测试方法:在testvm1上启用jperf server作为网络数据接收端,在testvm2中启用jperf client连接jperf server发送网络数据包,同时加压网络流量。X86主机为双万兆网卡)
第二种情况,比如某业务系统的VM在同一主机的不同网段,则虚拟机之间网络流量经过主机物理网卡,其最大网络流量为5.6GB。测试方法同上。
第三种情况,比如某业务系统的VM在不同主机的同一网段,则虚拟机之间网络流量经过主机物理网卡,其最大网络流量为6.5GB。测试方法同上。
第四种情况,比如某业务系统的VM在不同主机的不同网段,则虚拟机之间网络流量经过主机物理网卡,其最大网络流量为4.6GB。测试方法同上。
测试的几种场景对比表如表1所示。
|
VM虚机 |
物理机 |
网卡 |
所属网段 |
数据方向 |
物理网卡 |
最大数据流量 |
|
vm1和vm2 |
同一主机 |
万兆 |
同一 |
单向 |
不经过 |
7.6G |
|
vm1和vm2 |
同一主机 |
万兆 |
不同 |
单向 |
经过 |
5.6G |
|
Vm3和vm4 |
不同主机 |
万兆 |
同一 |
单向 |
经过 |
6.5G |
|
Vm3和vm4 |
不同主机 |
万兆 |
不同 |
单向 |
经过 |
4.6G |
表1 几种场景的VM测试数据对比
在一台X86物理服务器上进行VM的网络虚拟化,还有一种技术就是SR-IOV。SR-IOV 技术是INTEL提出的一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性。SR-IOV 标准允许在虚拟机之间高效共享 PCIe(Peripheral Component Interconnect Express,快速外设组件互连)设备,并且它是在硬件中实现的,可以获得能够与本机性能媲美的网络 I/O 性能。比如我们把一台X86物理服务器上的万兆网卡通过SR-IOV技术分成4个虚拟网卡给4个VM使用,那么其网络传输性能将比虚拟化网卡给VM使用高很多。
测试方法:在一台X86物理服务器上,4个VM启用jperf server作为网络数据接收端;在另一台X86物理服务器上,4个VM启用jperf client连接jperf server发送网络数据包,同时加压网络流量。两台X86主机为双万兆网卡。
SR-IOV虚拟化测试架构如图2所示:
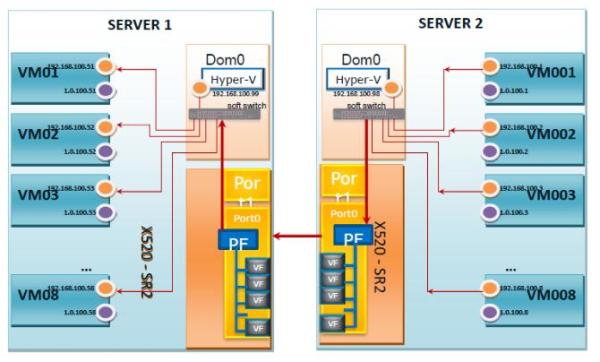
图2:SR-IOV虚拟化测试架构
网络传输的数据量对比如表2所示。
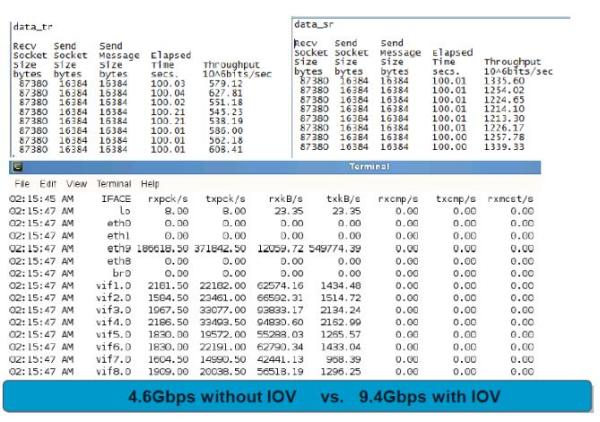
普通的虚拟化传输的最大数据量为4.6Gbps,而SR-IOV的直接硬件虚拟化可达到9.4Gbps。
具有 SR-IOV 功能的设备还有以下优点:节能、减少了适配器数量,同时简化了布线,减少了交换机端口。SR-IOV有很多优点,但是也有很多限制,比如VMWARE里原有的很多功能将对SR-IOV 的虚拟机不可用。比如Vmotion、Storage Vmotion、Vshield、NetFlow、High Availability、FT、DRS、DPM、挂起和恢复、快照、热添加和删除虚拟设备、加入到群集环境。
因此,我们在考虑x86网络虚拟化的时候,更多的需要结合性能、业务特点、基础设施来综合考虑。如果一个业务要求比较高的性能同时不需要更多的灵活性,可以考虑SR-IOV技术。反之则选择X86常见的网络虚拟化技术,结合VMWARE来进行部署。
2.2 计算层面
从计算层面来说,X86物理服务器上的CPU、内存资源都可提供给虚拟机使用。现在的高性能X86服务器一般都是多CPU多核系统,NUMA 架构会越来越受欢迎,因为这个架构可解决多处理器多核和非统一内存架构之间的交互带来的新的CPU、内存资源分配方法的挑战,并改善占用大量内存的工作负载的性能。NUMA架构如图3所示:
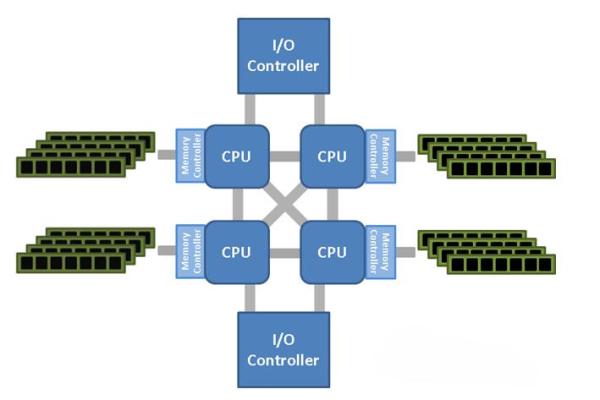
图3:NUMA架构图
传统的服务器架构下是把内存放到单一的存储池中,这对于单处理器或单核心的系统工作良好。但是这种传统的统一访问方式,在多核心同时访问内存空间时会导致资源争用和性能问题。
而NUMA是服务器CPU和内存设计的新架构,它改变了内存对CPU的呈现方式,这是通过对服务器每个CPU的内存进行分区来实现的。每个分区(或内存块)称为NUMA节点,而和该分区相关的处理器可以更快地访问NUMA内存,而且不需要和其它的NUMA节点争用服务器上的资源(其它的内存分区分配给其它处理器)。NUMA也支持任意一个处理器访问服务器上的任何一块内存区域。
某个处理器当然可以访问位于不同区域上的内存数据,但是却需要更多本地NUMA节点之外的传输,并且需要目标NUMA节点的确认。这增加了整体开销,影响了CPU和内存子系统的性能。
例如一台配置了两颗八核处理器以及128GB内存的服务器,在NUMA架构中,每个处理器能够控制64GB的物理内存,每个处理器的八个核心中的每个核心将对应一个8GB的NUMA节点。这将会如何影响虚拟机性能?
由于每个处理器核心访问NUMA节点内内存的速度要比其他节点快,因此当虚拟机内存大小少于或者等于NUMA节点的内存大小时,虚拟机在理论上能够获得最好的性能。所以我们在这台物理服务器上分配虚机时,不要给每台虚拟机分配超过8GB的内存。
如果给虚拟机分配更多的内存,则虚拟机必然要访问其NUMA节点之外的部分内存,这样或多或少会影响其性能。如果应用能够感知NUMA,那就更好了。vSphere使用vNUMA可以创建能够感知NUMA的虚拟机。该虚拟机将会被分割为虚拟NUMA节点,每个vNUMA节点将会被放置到一个不同的物理NUMA节点。尽管虚拟机仍旧在两个NUMA节点之间扩展,但虚拟机内的操作系统和应用能够感知NUMA,资源使用将会得到优化。
NUMA已经对在数据中心服务器上安装及选择内存的方式带来了很多改变。在给服务器增加物理内存时,我们需要注意增加的内存要在NUMA节点之间进行平衡及匹配以使主板上的每个处理器拥有相同的内存。如果在我们所举例的服务器上配置更多的内存,那么必须在处理器之间平衡这些内存模块。如果增加64GB的内存,那么每个处理器将分配到32GB的内存(每个处理器可支配的内存将增加到96GB,服务器总内存数将达到192GB),每个NUMA节点的内存大小将从8GB增加到12GB。
结合VMWARE的最佳实践,VMware一般给CPU建议,最大支持64个vCPU,一般不超过32个,最好不要超配置;内存一般不给建议,根据不同的业务对内存大小会有不同的要求,当然最好不要跨NUMA单元去进行调用。
另外还要注意一点NUMA架构只针对物理CPU(Socket),不针对核(Core)。由于每个Socket控制的内存插槽是不同的,因此要确保内存插槽是均匀的。例如128G内存分为8个16G的内存条,那么应该4个插在一个Socket的内存插槽中,另4个插在另一个socket的内存插槽中。在为虚机分配vCPU资源时,也尽可能按照Socket/Core的倍数分配,比如1X1, 1X2, 1X 4, 1X8, 2X1, 2X2, 2X4, 2X8等组合,但不要使用2X3, 2X5, 2X7这种组合。后面的组合会引起跨Socket的内存调用,从而容易导致性能下降.
2.3 存储层面
从存储层面来说,X86物理服务器上的VM连接后端存储划过来的LUN。在Lun上创建虚拟磁盘有三种方式:厚置备延迟置零、厚置备置零与精简置备。如图4所示:
图4:磁盘三种模式
厚置备延迟置零(zeroed thick)以默认的厚格式创建虚拟磁盘,创建过程中为虚拟磁盘分配所需的全部空间。创建时不会擦除物理设备上保留的任何数据,但是以后从虚拟机首次执行写操作时会按需要将其置零。简单的说就是立刻分配指定大小的空间,空间内数据暂时不清空,以后按需清空;厚置备置零(eager zeroed thick)创建支持群集功能(如 Fault Tolerance)的厚磁盘。
在创建时为虚拟磁盘分配所需的空间。与平面格式相反,在创建过程中会将物理设备上保留的数据置零。创建这种格式的磁盘所需的时间可能会比创建其他类型的磁盘长。简单的说就是立刻分配指定大小的空间,并将该空间内所有数据清空;精简置备(thin)使用精简置备格式。最初,精简置备的磁盘只使用该磁盘最初所需要的数据存储空间。如果以后精简磁盘需要更多空间,则它可以增长到为其分配的最大容量。简单的说就是为该磁盘文件指定增长的最大空间,需要增长的时候检查是否超过限额。
另外thin provision格式在VM使用的时候比起厚置备格式也会有一些负面的性能影响。这是因为thin provision格式的磁盘是动态扩大的,一个数GB大小的vmdk文件在磁盘上不是一次生成的,因此不像厚置备格式的磁盘那样可以占用连续的磁盘空间,因此在访问thin provision格式的磁盘的时候,必然会因为磁头在不连续的磁盘块之间移动导致寻址时间较长,从而影响到Disk IO性能。
综上所述,无论是在部署还是应用时,thin provision格式的性能都不如厚置备,所以在空间不紧张够用的情况下建议大家使用厚置备格式的虚拟磁盘。
3、结合业务如何进行x86虚拟化后的性能优化
例如一个Linux下的postfix邮件系统,包含邮件服务器,数据库和网络。从磁盘看邮件系统的一个最大的问题是:不是很多大文件的读写,而是很多小文件的读写,而且这些读写请求是来自同一时间的多个进程或者线程。对这种很多小文件的读写应用服务,在分配邮件用户所在的磁盘时,建议使用Thin provision模式。这样既避免了初始空间的大量占用,也可以做到随需增长。
从内存上看,对于postfix而言,它的每一个进程不会消耗太多的内存,我们期望的是大量的内存被自动使用到磁盘缓存中来提高磁盘I/O速率,当然这个我们不需要操作,Linux帮我们完成了!Linux虚拟内存管理默认将所有空闲内存空间都作为硬盘缓存。因此在拥有数GB内存的生产性Linux系统中,经常可以看到可用的内存只有20MB。从处理器上看邮件系统,不管是smtp、imap对CPU的占用都不是很大。这样我们在分配CPU和内存资源时,就可以按照NUMA架构来配置固定大小的单元。比如一台配置了两颗八核处理器以及128GB内存的服务器,虚拟化成4台邮件服务器,就可以每台分配成4核32G。
从网络上看,邮件系统会频繁的使用网络子系统,但是邮件系统的瓶颈还是磁盘的吞吐而不是网络的吞吐,对应这种应用不要求强交互,延迟是允许的,所以网卡是虚拟的还是SR-IOV的影响都不大。
对于邮件系统的数据库服务器,因为小文件随机读写比较多,数据库的磁盘可以选择厚置备模式,提高小数据块的IO。
对于不同的业务系统,具体的问题还需要具体分析,性能优化不是一朝一夕的事,随着业务的发展变化,优化的技术手段和方式都会相应的随之改变。
4、从企业日常使用和管理角度看x86服务器的虚拟化
不同的企业级应用对于CPU和内存资源和空间的利用率是不同的,如何利用NUMA架构来优化资源的分配和提高性能对于企业数据中心的管理也是非常有意义的。见表3。
|
应用 |
CPU |
内存 |
IOPS |
吞吐 |
|
数据库 |
高 |
高 |
140 IOPS |
15MB/S |
|
邮件系统 |
低 |
高 |
320 IOPS |
20MB/S |
|
VDI桌面 |
低 |
低 |
15 IOPS |
4MB/S |
|
网站 |
随需变化 |
随需变化 |
1400 IOPS |
18MB/S |
|
文件服务器 |
低 |
低 |
80 IOPS |
9MB/S |
表3 不同企业级应用的资源利用率对比
对于数据库服务器,由于对CPU和内存资源要求较高,不适合多机共享资源使用,所以尽可能使用配置较好的物理机,而对于VDI桌面、文件服务器则更适合NUMA架构下固定CPU和内存单元的分配,邮件系统则需要根据具体情况做NUMA架构的资源分配,对于随需变化的网站则不一定全部适合做NUMA,比如网站中的缓存服务器则更适合做非NUMA架构的内存分配。在分配磁盘空间时,对IO性能需求比较大的业务系统,适合做厚置备的空间分配;对IO性能需求不是很高的、业务增长空间不是很大的业务系统,则适合做精简配置的空间分配。
5、结束语
X86服务器虚拟化是一项用以整合服务器资源、提高效率的技术。X86虚拟化可以带来更高的服务器硬件及系统资源利用率,带来具有透明负载均衡、动态迁移、故障自动隔离、系统自动重构的高可靠服务器应用环境,以及更为简洁、统一的服务器资源分配管理模式。X86服务器虚拟化在资源划分后的性能优化也极大提高了数据中心的整体资源利用率,符合当今绿色节能的新理念。

