01 - 系统概况
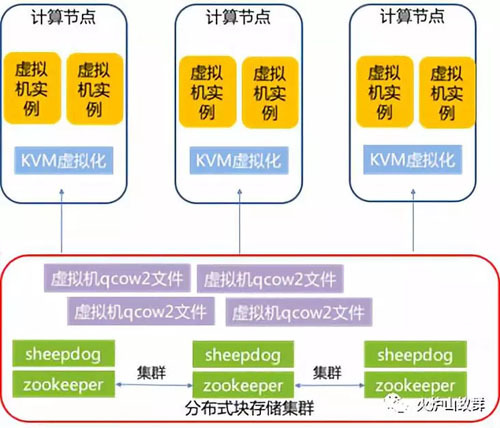
我们内部有一个规模不大的私有云,承载内部应用和测试系统,目前运行了超过1000台虚拟机。采用技术方案为KVM虚拟化+Sheepdog分布式块存储:
(1)运行虚拟机的计算节点为CentOS 6.5,虚拟化技术采用KVM,虚拟机管理采用开源OpenNebula方案(选择OpenNebula主要是历史沿袭,日常管理需求简单,基本够用)。
(2)虚拟机的镜像,运行在后端分布式块存储系统上,此系统是基于开源的Sheepdog架构。
02 - 存在的问题与解决思路
2.1 - 存在问题
由于虚拟机镜像都承载在分布式块存储系统中,虚拟机的所有存储IO都会经过分布式存储系统。在此情况下,一旦分布式块存储系统异常(如承载网络较大规模故障、存储系统集群机制异常等),承载虚拟机的计算节点与存储系统之间的存储IO出现阻塞,进而虚拟机的存储IO也出现阻塞,虚拟机操作系统(特别是Windows操作系统的虚拟机)会出现异常,如Windows系统蓝屏、系统自检、进入检查模式等各种情况。即便存储系统后续恢复正常,这些虚拟机很可能依然处于异常状态。
虚拟机异常,一般有很多常规办法来发现,如:
(1) ping检查。但虚拟机所属应用维护人员可能会禁止ping,或在安全组上做限制。
(2)部署zabbix、nagios等监控系统的agent进行异常监控。但虚拟机所属应用维护人员可能会关闭或卸载agent。
(3)通过计算节点的qemu-kvm的一些工具来判断虚拟机文件系统是否可以写入。但这个方式涉及“侵入”虚拟机,属于严厉禁止的操作。
可以看出上述方法有两个问题:
(1)如果虚拟机归属不同使用人,每个使用人有不同运维风格,习惯或管理要求(如禁止ping或关闭agent客户端),使用常规方法来判断出问题的虚拟机会有疏漏)
(2)无法判断虚拟机(特别是Windows虚拟机)的具体异常情况,如蓝屏、系统自测等。
因此,最稳妥的方式是VNC工具连接到各个虚拟机,检查虚拟机屏幕信息判断其状态,再根据状态一个个修复(VNC虽然可以看到虚拟机屏幕,但是虚拟机都是有登陆账号和登陆密码的,检查人员并没有这些账号密码,因此不会“侵入”虚拟机)。但是修复过程非常繁琐,核查和修订的步骤主要如下:
核查操作:
(1)登陆到某台计算节点,VNC某台虚拟机,通过VNC界面查看其状态(蓝屏、自检等)。虚拟机数量多的情况下,需要多人分工进行开展,通过表格进行记录。
(2)汇总各个检查人员的检查结果表格。
修复操作:
(3)按照表格进行多人分工,各自负责部分虚拟机的修复,如下述4-6步骤。
(4)尝试人动重启虚拟机。
(5)如果依旧蓝屏或其他异常,则需要手动挂载Win PE系统尝试修复。需要手动将Win PE的iso文件拷贝至计算节点,手动修改虚拟机配置文件使其挂载Win PE的iso文件,重启虚拟机进行Win PE模式然后手动进行修复。
(6)修复完毕重启,如果系统依旧无法登录,且虚拟机使用人建议重装操作系统,则需要将虚拟机重置重装。
可以看出,整个过程都是手工对每台虚拟机分别操作,耗时长,效率低。
2.2 - 解决思路
上述手工操作步骤中,VNC配置、虚拟机汇总信息表格、虚拟机配置、Win PE iso镜像,都是文件形式,都可以通过脚本进行批量生成、修改,具备自动化的基础。
将上述手工操作步骤脚本化,形成如下批量核查和修复的脚本工具:
(1)能够自动生成待核查的虚拟机信息excel表格
(2) 能够批量VNC截图虚拟机的屏幕状态,人工识别和判断虚拟机屏幕的状态。
(3)对于需要修复,并能一键挂载Win PE镜像到虚拟机上进行引导修复或重装操作。
03- 批量核查和修复虚拟机的具体方法
3.1 - 工具实现框架
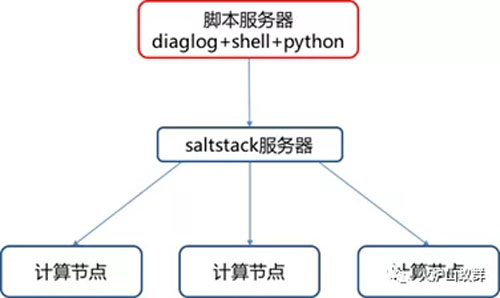
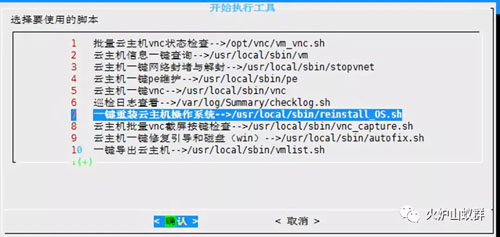
在生产环境里,我们已经用了Saltstack作为配置工具,基于Saltstack的批量操作与配置能力,我们在统一脚本服务器上,制作了对应的shell脚本和python脚本来实现具体功能,并用Linux的Diaglog进行简单汇总展示。如下图:
3.2 - 一键导出虚拟机
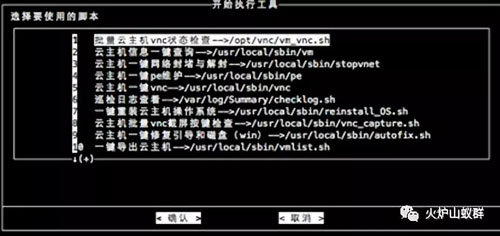
根据集群影响范围及虚拟机数量,按照IP地址顺序,导出所有可能存在问题的虚拟机到excel,导出来后可以进行过滤与编辑,快速进行多人分工核查。
在我们生成环境,同一网段对应的是同一个业务系统,因此我们一般根据虚拟机数量和业务系统(网段)进行分工。
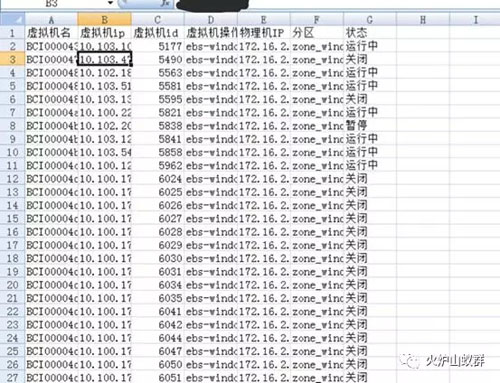
3.3 - 虚拟机批量VNC截屏按键检查
根据3.2步骤过滤出的虚拟机IP地址信息,获取虚拟机所在物理机及VNC端口号,使用VNCdotool工具调用虚拟机VNC接口进行按键测试,并进行虚拟机屏幕截图。
根据虚拟机IP地址信息,生成一个已经设定好模板的checklist表格(csv格式),便于记录和汇总后面步骤中人工判断的信息。表格主要字段为: IP、主机名、虚拟机ID、业务系统联系人、第一次检查结果,引导修复后状态,重装后状态。
将截图信息和表格一并打包下载到本地。
具体步骤如下:
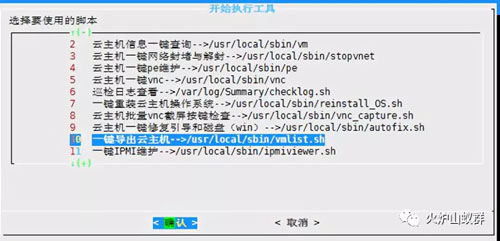
(1)使用《8 虚拟机批量VNC截屏按键检查》,上传记录了虚拟机主机名或者IP地址的vmlist.txt文件
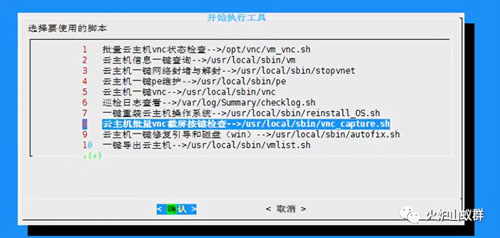
(2)上传vmlist.txt文件后,脚本会读取文件里的主机名或者IP,自动进行VNC登陆和截图,并会压缩成一个以时间日期为名称的压缩文件,可将截图的压缩文件保存到本地。
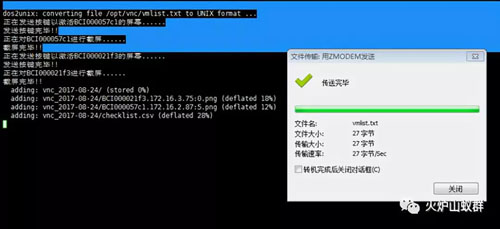
(3)解压压缩文件,进入目录查看虚拟机VNC截图的目前的运行情况,人工检查虚拟机屏幕截图,并在checklist表格里记录检查信息(重点是将蓝屏、自检、无法进入系统的虚拟机过滤出来)。因为截图已经匹配做好,且做好命名,这个时候人工检查工作量就相对小。

3.4 - 虚拟机一键修复引导
(1)如果虚拟机异常,则尝试进行虚拟机修复。

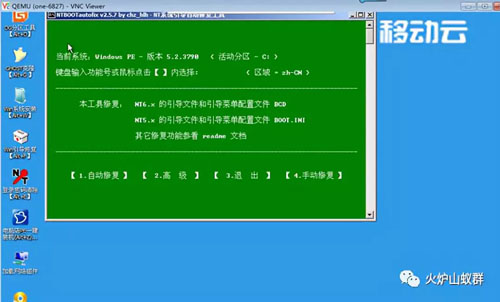
(2)执行工具输入需要修复IP或主机名,脚本将自动从镜像库将Win PE文件传输到计算节点对应目录下,修改虚拟机配置文件来挂载Win PE(Win PE已进行修改,能够自动进入Win PE并打开NTboot修复工具),然后重启虚拟机以使虚拟机配置生效。
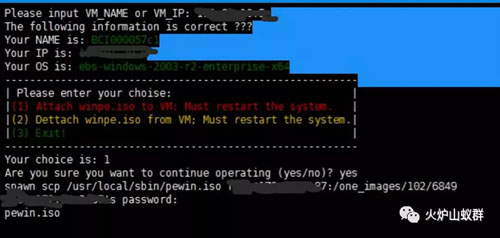
(3)虚拟机启动后,将自动调用NTboot工具进行磁盘修复。此时需要手工进行选择操作和观察修复结果。
3.5 一键重装虚拟机系统
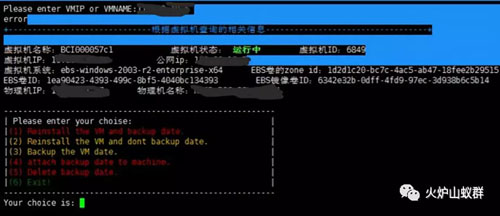
如果需要重装虚拟机,执行工具输入需要重装IP或主机名。脚本将自动:
(1)进入计算节点关闭虚拟机。
(2)进入分布式块存储系统节点备份虚拟机镜像,记录镜像ID,然后卸载镜像。
(3)在分布式块存储系统节点中,通过基础镜像(Windows初始化后的状态)克隆出一个跟原有镜像ID一样的镜像,作为新的虚拟机镜像。
(4)重新挂载新的虚拟机镜像,实现重装。
04 -可探讨和优化的问题
上述的Windows虚拟机检查和修复方法,是我们在一次实际故障后根据故障处理过程总结出来的操作方法和脚本工具,由于同类故障遇到的很少,且我们日常主要做Linux维护,对Windows了解不深,可能存在很多疏漏或可优化的地方,大家如有问题或意见,可以留言讨论。
(1)从根源上来说,还是要保证分布式块存储系统及对应网络的稳定性,这个是此故障场景的根源问题。
(2)从我们遇到的故障现象看,分布式块存储系统异常时,Windows虚拟机容易异常,但Linux则相对较少,但我们不知具体原因是什么(例如Linux对磁盘IO读写、文件系统小读写有更好的优化)。不知Windows是否有什么需要特别优化的配置?如有经验欢迎留言分享。
(3)在我们环境里,虚拟机归属其它团队,他们可能禁止ping或监控agent运行,这个时候如何更好判断虚拟机的“死活”?如有经验欢迎留言分享。
(4)目前还有一些环节是需要人工参与判断,例如看虚拟机屏幕判断是否有蓝屏、是否进入自检。这部分可以结合简单的图像识别技术进行实现,自动化程度会更高。
(5)因为此工具的使用并非高频场景(如果高频,老板铁定要爆炒我们了),所以目前还停留在脚本阶段,暂未纳入到我们的运维平台中,后续我们也会进一步优化和改进。

