常见故障原因
我们所谓系统发生故障是指当它无法再按照规格要求向用户提供服务时。这种故障是由故障所引发的,即内部组件或系统所依赖的外部组件发生故障。有一些故障是可以被容忍的,对用户没有明显的影响,而另一些则会导致系统故障。
为了构建具备容错能力的应用程序,首先需要了解可能出现哪些问题。在接下来的内容中,我们将探讨一些最常见的故障根本原因。到最后,您可能会思考如何应对各种不同类型的故障。

1、硬件故障
在计算机系统中,任何物理组件都可能发生故障。硬盘驱动器、内存模块、电源供应器、主板、固态硬盘、网络接口卡以及中央处理器等,均可能因各种原因停止正常运作。有时,硬件故障甚至可能导致数据损坏。更甚者,整个数据中心可能会因电力中断或自然灾害而发生故障。不过,正如我们将在后文讨论的那样,通过引入冗余措施,许多这些基础设施故障是可以应对的。虽然你可能认为这些硬件故障是导致分布式应用程序失败的主要原因,但实际上,它们往往因为一些非常普通的原因而出现问题。
2、错误处理
在最近对五个流行的分布式数据存储系统进行的用户报告研究中,发现了多数灾难性故障的根本原因是对非致命错误处理的不当。在大多数情况下,这些错误处理中的问题本可以通过简单的测试来检测出来。例如,有些错误处理程序完全忽略了错误。其他则捕捉了过于通用的异常,比如Java中的Exception,然后出于毫无充分理由的原因终止整个进程。还有一些错误处理程序只实施了部分功能,甚至包含了"FIXME"和"TODO"这样的注释。回过头来看,这或许并不太令人意外,因为错误处理往往被视为次要问题。这也是Go语言如此重视错误处理的原因。在后续,我们将更加深入地探讨测试大型分布式应用程序的最佳实践。
3、配置更改
配置更改是导致灾难性故障的主要根本原因之一。问题不仅仅在于错误的配置可能会引发问题,还有一种情况是对于启用了很少被使用的功能的有效配置更改不再按预期工作,或者从来没有按预期工作。配置更改之所以特别危险,是因为它们的影响可能会拖延。如果一个应用程序仅在真正需要配置值的时候才读取它们,那么无效的配置更改可能会在几小时甚至几天后才显现出问题,从而无法及早被发现。因此,配置更改应该像代码更改一样受到版本控制,经过测试,并在变更时采取预防性验证措施。在持续部署的背景下,我们将探讨代码和配置更改的安全发布实践。
4、单点故障
单点故障(SPOF)是指当某个组件故障时,整个系统都会崩溃的情况。实际上,系统可能存在多个单点故障。
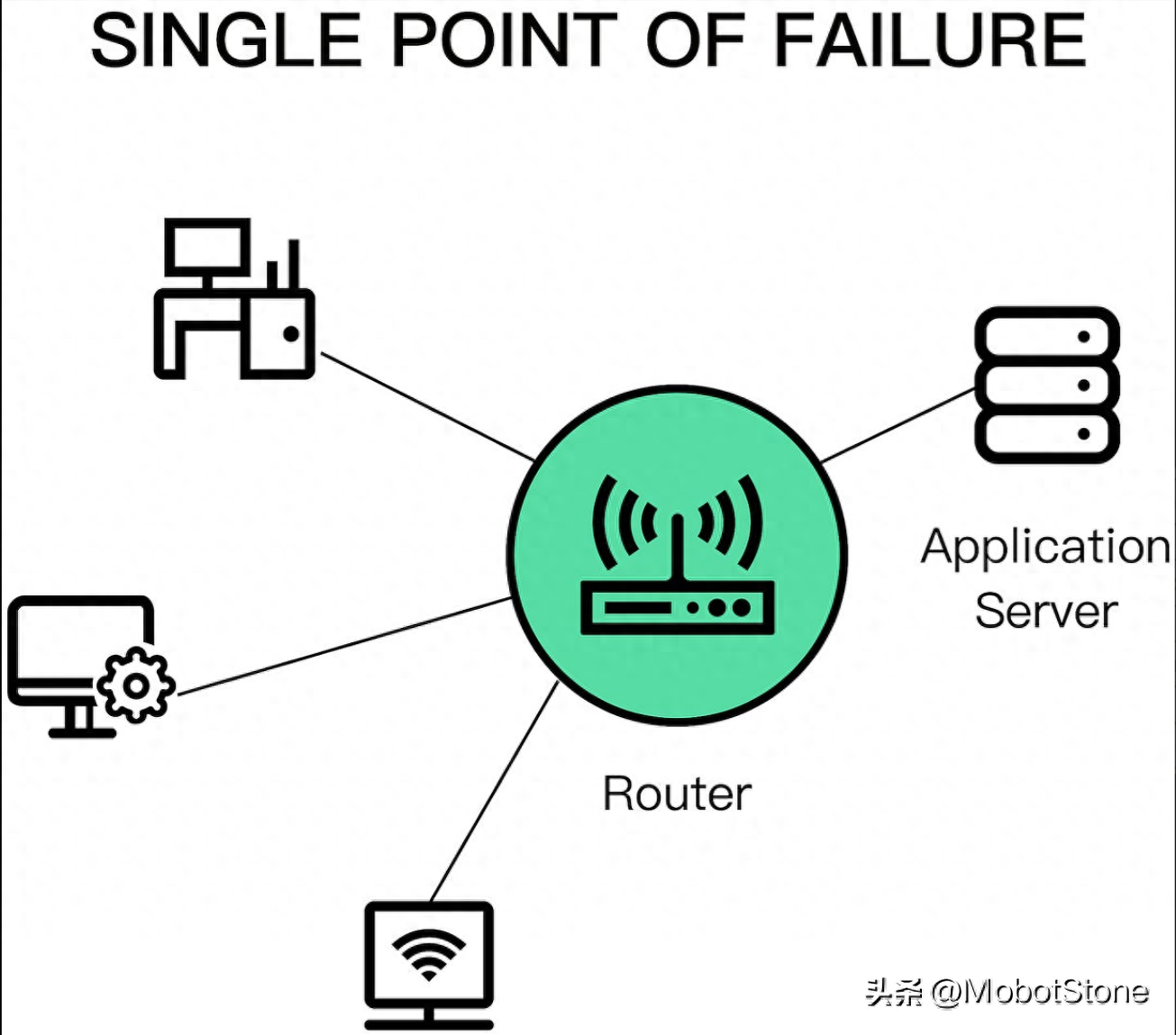
通常情况下,人员往往成为关键的单点故障(SPOF),如果将他们置于可能独立引发灾难性故障的位置,几乎可以确定他们最终会引发这种故障。例如,人类故障经常发生在某人需要按照特定顺序手动执行一系列操作步骤而不能犯任何错误的情况下。相比之下,计算机在执行指令方面表现出色,因此自动化应尽可能得到充分利用。
另一个常见的SPOF是DNS。如果客户端无法解析应用程序的域名,它们将无法连接到该应用程序。造成这种情况的原因多种多样,从域名到期到整个根级域名崩溃都有可能。
类似地,应用程序用于其HTTP端点的TLS证书也是一个SPOF。如果证书过期,客户端将无法与应用程序建立安全连接。
理想情况下,在系统设计阶段就应该识别这些SPOF。检测它们的最佳方法是审查每个系统组件,然后询问如果其中任何一个出现故障会发生什么。有些SPOF可以通过引入冗余来解决,而其他一些则无法。在这种情况下,唯一的选择就是减小SPOF的影响范围,也就是在它们发生故障时对系统造成的损害。我们将在后续讨论的许多弹性模式都旨在减小故障的影响范围。
5、网络故障
当客户端向服务器发送请求时,期望在不久后收到响应。在最佳情况下,请求后很快就会收到响应。如果出现了不同寻常的情况,客户端有两种选择:要么继续等待,要么因为超时异常或错误而取消请求。慢速的网络调用是分布式系统的潜在隐患,因为客户端无法确定响应是否最终会到达,因此它可能会长时间等待,或者干脆不取消请求,从而导致性能下降,而这种问题很难调试。这种故障也被称为"灰色故障",它非常微妙,很难迅速或准确地检测到。由于其特性,灰色故障可能会轻松使整个系统崩溃。
当引入故障检测和超时的概念时,会有很多原因导致未能获得及时响应。举例而言,服务器可能因在处理请求时速度极慢或崩溃而未能及时响应;或者可能是网络丢失了少量数据包,从而引发大量的重传和延迟。
慢速网络调用 是分布式系统的潜在杀手。由于客户端不清楚响应是否最终会抵达,因此它可能花费大量时间等待,甚至可能不会放弃,这将导致性能下降,而问题难以调试。这种故障也被称为 灰色故障,这是一种如此微妙以至于不能迅速或准确检测到的故障。由于其特性,灰色故障很容易将整个系统带入崩溃的边缘。
6. 资源泄漏
从观察者的角度来看,一个非常慢的进程与根本不运行的进程几乎没有什么不同,两者都无法执行有用的工作。资源泄漏是导致进程变慢的最常见原因之一。
内存可能是受泄漏影响最广泛的资源之一。内存泄漏会导致内存消耗逐渐增加。即使是带有垃圾回收功能的编程语言也容易受到泄漏的影响:如果对不再需要的对象保留了引用,垃圾回收器将无法删除它。当泄漏消耗了大量内存以至于剩下很少时,操作系统将开始积极将内存页面交换到磁盘。此外,垃圾回收器将更频繁地启动,试图释放内存。所有这些都会消耗CPU周期并使进程变得更慢。最终,当物理内存不再可用,且交换文件空间耗尽时,进程将无法分配内存,导致大多数操作失败。
内存只是众多可能泄漏的资源之一。以线程池为例:如果从线程池获取的线程进行同步阻塞的HTTP调用而没有设置超时,并且该调用从未返回,线程将不会返回到线程池。由于线程池具有有限的最大大小,如果持续丧失线程,最终线程将耗尽。
或许你认为在前述情况下,采用异步调用而不是同步调用会有所帮助。然而,现代HTTP客户端使用套接字池以避免重复创建TCP连接并支付性能代价。如果请求未设置超时,连接将永远不会返回到池中。由于池的最大大小是有限的,最终将不再有可用的连接。
此外,你的代码并不是唯一访问内存、线程和套接字的代码。你的应用程序所依赖的库也会使用相同的资源,它们可能会遇到我们刚刚讨论的相同问题。
7. 负载压力
每个系统都有其负载容量,也就是它可以承受的负载极限。因此,当导向系统的负载持续增加时,它迟早会触及到这个极限。
然而,有机会的负载增长为系统提供了逐渐扩展和增加容量的时间,这是一种情况;而突然和意外的洪水是另一种情况。
例如,考虑应用程序在一段时间内收到的请求数量。传入请求的速率和类型可能会随时间变化,有时甚至会因各种原因突然改变:
- 请求可能具有季节性。因此,例如,根据一天中的时间,应用程序可能会受到来自不同国家用户的访问。
- 有些请求比其他请求昂贵得多,以意外的方式滥用系统,例如高速爬虫抓取数据。
- 有些请求是恶意的,例如试图通过DDoS攻击来饱和应用程序的带宽,从而拒绝合法用户的访问。尽管一些负载激增可以通过自动增加容量(例如,自动扩展)来处理,但其他情况下,系统需要拒绝请求以保护自己免受过载。
8. 级联故障
或许你认为,如果一个系统有数百个进程,那么如果其中一小部分进程变得缓慢或无法访问,这应该不会有太大的影响。
故障的问题在于它们具有蔓延传播的潜力,会从一个进程传播到另一个进程,直到整个系统崩溃。这种情况发生在系统组件相互依赖的情况下,其中一个组件的故障会增加其他组件故障的概率。
通常需要采取足够大的纠正措施来打破这个循环,比如暂时阻止流量到首次复制品。不幸的是,一旦这些故障开始,它们非常难以减轻,而预防故障从一个组件传播到另一个组件是最佳方法。

