大数据架构是为处理超大数据量或复杂计算而设计的,流程上包括数据的获取、处理和分析。
大数据,可以简单理解为传统数据库无法处理的数据量,比如主从模式的MySQL在简单场景下可以存储和处理上亿条数据,但涉及到分析场景,能处理的数据量可能远远小于1亿。利用大数据架构,可以轻松处理上亿到千亿数据的分析需求。
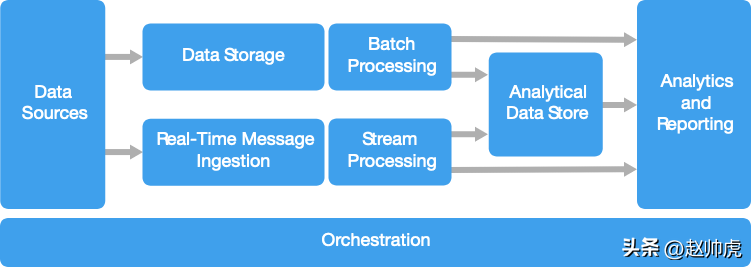
大数据架构通常支持这些使用方式:
- 离线静态数据的批处理
- 实时动态数据的流式处理
- 大数据的交互式查询(ad hoc query)
- 机器学习训练和推理
多数大数据架构会包含下面这些组件:
数据源
所有大数据解决方案都必须从数据源开始,数据源有很多种,比如:
- 应用的数据存储,比如传统关系型数据库MySQL等
- 应用产生的静态文件,比如用户行为日志
- 实时数据源,比如IoT设备
这些数据均来自于大数据系统外部,经过数据清洗等流程存储到大数据系统。
数据存储
离线批处理的数据通常存储在分布式文件系统里,这些文件系统可以以不同的格式存储大量的大文件,比如块存储HDFS上单个block的大小可以是256MB,总体可存储PB量级的数据。当然,存储也分为对象存储和块存储,比如AWS S3是Amazon闭源的对象存储方案,在扩展性和小文件支持上有一些优势。
最近几年,这类分布式块存储或文件存储有一个更时髦的名字:数据湖。
批处理
由于数据量特别大,体现在数据条数多和占用磁盘空间大,大数据架构在应对分析场景时,通常采用耗时的批处理作业去处理数据,处理逻辑包括但不限于转换、过滤、聚合等。这些批处理任务通常会 1)读取源文件,2)处理数据,3)将结果写入新文件。可选的技术有基于MapReduce/Spark的SQL,或使用Java/Scala/Python等编写的MapReduce/Spark任务。
实时消息采集
如果数据源是实时的,那么架构上必须支持捕获并存储实时消息,以方便后面进行流式处理。使用的存储可以非常简单,比如直接append到一个目录下的文件里。但现实中并不会采用这个方案,而是使用一个消息存储充当buffer。这样就能支持多个下游子系统进行独立处理、保障数据不丢失、并获取消息排队的能力。
可选的技术有:Kafka、RocketMQ、RabbitMQ 等。
流式处理
从Source采集到实时消息以后,还需要对消息进行过滤、聚合等操作,用于后续的分析场景。流式数据被处理以后写入Sink。
在这个领域,Flink是名副其实的第一,Flink SQL也是阿里最近几年推行的重点方向,除此之外还有 Spark Structured Streaming,Storm 等技术方案。对比而言,Flink的生态更为完善,Streaming Warehouse也是基于Flink构建的。
分析型数据库
大数据系统的数据源通常是半结构化的数据,分析场景下为了保证性能,通常查询的是结构化的数据表。在传统商业BI系统中,数仓通常以Kimball维度数据仓库理念进行建模,分析型数据库支持在这种数据关系上的查询。相对于Inmon理念,Kimball偏向于保持source不变,中间层做join,最终给业务提供一张大宽表,以满足复杂多样的分析需求。Kimball理念下的数据表关系呈现出典型的星型结构:

除了存算一体的分析型数据库,还有其他方式,比如:
- 通过一个低延迟的NoSQL数据库去管理和展现数据,比如HBase
- 基于分布式存储(HDFS、S3等)管理数据+ Hive metastore 管理结构化信息,支持交互式的查询
可选的技术有:交互式Hive、HBase、Spark SQL,目前流行的也有clickhouse、doris等能够榨干机器性能的报表工具。
数据分析和报表
大数据方案的目标多数是通过分析和报表提供对数据的洞察能力。为了增强分析功能,我们通常在架构中会包含一个数据建模层,比如一个多维OLAP cube表。基于Clickhouse 或 Excel,用户自己通过简单的拖拽或点点点,就能做报表。对于懂一些技术的数据科学家和分析师而言,Jupyter Notebook提供了更强大和弹性的交互式分析能力,使用Python或R 可以更自由地访问更大的数据集,可以更好地支持JOIN操作,也能将结果非常轻松地喂tensorflow/pytorch实现更高级的建模分析。
任务调度与编排
多数大数据方案都包含大量的重复计算。一个经典的工作流会包含:1)transform source 数据;2)在多个source和sink之间转移数据;3)将处理过的数据写入分析型数据库;4)将结果写入报表或仪表盘。为了把这些工作流自动化,我们可以使用一些编排工具,比如 Oozie、Sqoop 或大厂自研的那种。这些编排工具可以很好地处理任务的依赖关系,并严格按照依赖关系进行调度,通常也支持延迟报警、数据质量报警等功能。
上面讨论的这些功能组件,目前有很多开源的技术来支持,比如 Hadoop 系列中的 HDFS、HBase、Hive、Spark、Oozie、Sqoop、Kafka,向量分析数据库Clickhouse、Doris等。目前主流的云平台基本都支持这些开源组件,但也基本上都会自研一些,比如阿里的Max Compute等等。
应用场景
- 存储和处理的数据量远远超过了传统数据库的上限;
- 需要处理非结构化的数据,用于分析和报表;
- 采集、处理、分析实时流数据,或要求低延迟的场景;
架构优势
- 技术选型比较多:可以采用Apache开源技术,也可以使用云服务商的闭源技术,或者混用;
- 并行带来的极致性能:大数据架构充分利用了并行计算技术,能够高性能地处理大批量数据;
- 弹性扩容:大数据的绝大多数组件都支持扩容,可以根据数据量和业务要求选择物理资源,数据量增长时扩容的成本也不高;
- 与现存方案的兼容性:大数据组件既可以用于原始数据的采集,也可以用于顶层业务的数据分析,资源可以混合部署。
有哪些挑战
- 架构复杂度高:大数据架构需要采集多个数据源的大量数据,包含了很多组件,非常复杂。一方面构建、测试和调试大数据处理任务比较麻烦;另一方面,由于组件太多,多个组件的配置需要协同更改,才能达到优化性能的目的;
- 技术栈多:很多大数据技术比较专,使用的框架和语言也多种多样。好的一点是,大数据技术构建新的API时,采用了业界广泛推行的语言,比如SQL;
- 技术成熟度不够高:大数据技术仍然在不断演进。随着Hadoop的核心技术逐渐稳定下来,比如Hive、Pig、HDFS。新技术又不断产生,比如Spark每次迭代都发布了大量的新特性。随着Spark逐渐稳定,Flink、Clickhouse、Doris又崛起成为新的热点;
- 安全性:大数据架构中,数据通常被存储在一个中心化的数据湖里。安全合规地访问这些数据却愈发重要,在多个应用或平台生产和消费数据的场景下尤其重要。
最佳实践
- 充分利用并行计算。大数据架构通常会充分利用多台机器的多核特点,将计算任务并行化,以提升性能。并行计算对数据的存储格式有一定的要求,比如数据必须以能够分隔的格式存储。分布式文件系统(比如HDFS)能够优化读写性能,在实际数据处理中由多个计算节点并行执行,减少了作业的整体运行时长。
- 利用分区。离线数据处理通常按照固定的周期,比如天/周/月级定期执行。把数据文件放到不同的日期分区里,用分区表把数据管理起来,分区的粒度可以与任务执行的时间频率保持一致。这种模式简化了数据采集和作业调度,问题排查也会比较简单。目前主流的框架都支持分区概念,比如Hive分区表,分区作为过滤条件也可以大大缩减计算时扫描的数据量。现在流行的数据湖技术,在分区维度也做了很多优化,比如隐藏分区、bloomfilter索引、hash索引等。另外,在分区的基础上,Spark 3 通过 bucket 优化shuffle数据量。
- 使用 schema-on-read 语义:数据湖概念出现以后,我们可以给文件定义不同的数据格式,数据格式是结构化、半结构化,或非结构化的。通过 schema-on-read 语义,我们可以在处理数据时,动态地给数据赋予格式,而不是在存储时使用定义好的格式。这给我们的架构带来了很多弹性,数据采集这一环,一定程度上避免了数据校验或类型校验带来的问题。业界主流的方式仍然是在Hive提前创建好表结构,数据写入时必须满足结构限制,这样下游的理解和接入成本比较低;另外,metadata使用中心化地存储,还是去中心化,有很多考量因素,选择schema-on-read模式前一定要慎重考虑。
- 就地处理数据。传统的BI解决方案通常会通过extract-transform-load(ETL)任务将数据写入数仓。对于数据量特别大、格式多种多样的数据而言,通常会使用ETL的变种,比如 transform-extract-load (TEL)。使用这种方式,数据在分布式存储内部被转换为目标格式,这个过程可以存在多个任务,产出多个中间表。我们一般用数仓分层理论来规范表的名字和属性,比如ODS、DWS、DWD、APP等。APP层的数据表符合分析场景的格式要求,可以将其数据拷贝到分析型数据库(Clickhouse、ElasticSearch等)。
- 资源使用率 vs 运行时间。在创建批处理任务时,通常要考虑两个方面:1)计算节点上每个计算单元(CPU核)的价格,2)完成一个作业使用的计算节点一分钟花多少钱。举个例子,一个批处理任务,用4个计算节点需要执行8小时。但仔细观察发现,这4个节点在头2个小时满负荷运行,之后只有2个节点满负荷运行。这种情况下,如果使用2个计算节点,作业总的执行时间变成10个小时,并没有加倍;但花的钱变少了。为了缓解这个问题,多个用户/业务共用一个队列是一个简单但不完美的方案,但从更高的层面上,离线/在线资源混合调度才是更大的全局最优解。
- 独占资源。为了保障业务的正常运行,我们可以给不同类型的任务或业务分配独占资源,包括计算和存储。比如,对于离线处理,Spark/MapReduce 可以使用独立的yarn队列;对于Flink/Structured Streaming 任务,也使用独立的yarn队列;对于工作日上班时间的ad-hoc查询,也可以分配独立的队列。当然,业务稳定运行、开发/调试方便和省钱有天然的冲突,要解决这个问题,需要付诸很多努力。
- 对数据采集任务进行编排。在一些简单场景中,业务应用可以直接把文件写入分布式存储,然后供分析工具使用。但在大型互联网公司中,通常不会这么干,而是把外部数据源的数据落到数据湖里,然后使用编排工具把作业统一管理起来,依赖关系同时被管理起来,以便稳定产出、高效地复用在下游复杂的业务场景里。任务开发、定期调度、依赖管理、延迟报警、失败debug,这一切通常被维护在一个有Web页面的公司级平台里。
- 及早清理敏感数据。数据采集过程中,我们可以及早清理掉敏感数据,避免落库。

