
大家好,我是强哥。一个热爱暴走、读书、写作的人!
一、推荐系统的数据源
1. 根据产品功能要素来划分
(1)用户行为数据
(2)用户画像数据
(3)物品画像数据
(4)场景化数据
2. 根据数据载体来划分
(1)数据价值
(2)类别数据
(3)文本数据
(4)图片数据
(5)音视频数据
3. 根据数据组织形式来划分
(1)结构化数据
(2)半结构数据
(3)非结构化数据
二、数据预处理
1. 抽提(Extract)
2. 转换(Transform)
3. 加载(Load)
总结
推荐系统是机器学习的子领域,跟一般的机器学习算法一样,推荐算法依赖数据来构建推荐模型,有了模型后需要进行模型训练,最终为用户提供个性化的推荐服务(模型推断)。推荐系统由于其解决的问题的特性(推荐系统解决的是信息过滤与资源匹配的问题)以及自身的强业务相关性,构建推荐系统的数据来源及数据处理方式有自身的特点,本章我们就对推荐系统涉及到的数据源及数据预处理相关的知识进行介绍,方便我们在后续章节中构建推荐算法模型。
一、推荐系统的数据源
推荐系统根据用户在产品(APP、网站等)上的操作行为,挖掘用户的兴趣点,预测用户的兴趣偏好,最终为用户做个性化推荐。在整个推荐过程中,涉及到的要素有用户、物品、用户的操作行为、用户当前所处的场景等4类。这每类要素都是具备对应数据的。按照这种要素划分,推荐算法可以利用4类数据。另外,根据数据自身的特性,数据也可以分为数值数据、类别数据、文本数据、图片数据、音视频数据等5类。最后,根据推荐系统依赖的数据的组织形式(数据范式),又可以将数据分为结构化数据、半结构化数据、非结构化数据3大类。下面我们分别按照这3种分类方式来详细描述推荐系统所依赖的数据及这些数据的特点。
1. 根据产品功能要素来划分
根据数据来源的产品功能要素来分,推荐系统依赖的数据分为用户行为数据、用户画像数据、物品画像数据、场景化数据4大类,见下面图1,下面我们分别介绍各类数据及其特点。

图1:推荐系统依赖的4类数据源
(1) 用户行为数据
行为数据是用户在产品上的各种操作行为,比如浏览、点击、播放、购买、搜索、收藏、点赞、评论、转发、加购物车、甚至滑动、暂定、快进快退等等一切操作行为。用户在产品上的操作行为为我们了解用户提供了线索,用户的操作行为也是用户真实意图的反馈。通过挖掘用户行为,我们可以获得对用户兴趣偏好的深刻洞察。
根据用户的行为是否直接表明用户对物品的兴趣偏好,用户行为一般分为显式行为和隐式行为。显式行为是直接表明用户兴趣的行为,比如点赞、评分等。隐式行为虽不是直接表示用户的兴趣,但是该行为可以间接反馈用户的兴趣变化,只要不是用户直接评分、点赞的操作行为都算隐式反馈,包括浏览、点击、播放、收藏等等。
用户行为数据是最容易收集、数据量最多的一类数据(因为用户的任何操作行为,我们都可以进行埋点收集)。这类数据需要我们进行收集、预处理才能最终被推荐算法使用。这类数据获取也相对容易,只要我们按照规范进行埋点就能够保证数据范式正确,当然埋点也是需要经验的,目前有很多第三方服务商提供埋点实施方案,在这方面没有经验的企业是可以进行采购的。
有些产品由于自身特性,往往是很难收集到除了用户行为外的其他数据的(或者即使可以收集到,但是成本太大,比如UGC产生的数据可能就非常脏乱),因此,充分利用用户行为数据对构建高质量的推荐系统是非常关键的。
目前个人信息保护法正式实施了(2021年9月1日正式实施),另外国家也会开始管控算法业务,未来用户是可以关闭日志收集等相关服务的,这对未来的推荐算法落地是有比较大的挑战的。
(2)用户画像数据
用户画像数据是对用户相关信息的客观描述。包含用户自身所带的属性,比如年龄、身高、体重、性别、学历、家庭组成、职业等等。这些数据一般是稳定不变(如性别)或者缓慢变化(如年龄)的。而有些用户画像数据是通过用户的行为来刻画的,通过用户行为给用户打上相关标签,这些标签也成为用户画像的一部分,比如动漫迷、果粉、健身达人等等。
人类是一个社会化物种,用户的不同属性决定了用户所处的阶层或生活圈层。不同的阶层或生活圈又有不同的行为特征、生活方式、偏好特点,在同一圈层的用户具备一定的相似性,这种相似性为我们做个性化推荐提供了特有的方法和思路(比如基于社交关系的推荐就可以很好利用用户画像相关的信息)。
另外,通过用户对物品的操作行为,我们可以将物品所具备的特征按照某种权重赋予用户,这些特征就构建了用户的兴趣画像,相当于给用户打上了相关的标签(比如喜欢看“恐怖片”的人)。从这些兴趣偏好出发,我们可以给用户做个性化推荐。
有些产品由于业务特性是可以很好地收集到用户画像信息的,比如支付宝、微信等需要用户用身份证或者绑定银行卡,这就可以获得比较完整、隐私的用户个人信息了。而有些产品(比如今日头条、快手等),用户不需要注册就可以使用,比较难获得用户自身相关的信息。不管怎样,用户在产品上都会留下行为轨迹,基于这些行为轨迹,我们都可以挖掘出用户行为刻画出的画像特征。
(3)物品画像数据
推荐系统中最重要的一个“参与方”是待推荐的物品,物品自身是包含很多特征和属性的。对于商品来说,品类、价格、产地、颜色、质地、外观、品牌、保质期等等都是商品的元数据。如果有关于物品的描述信息(如电影的剧情介绍),我们还可以利用NLP技术从描述信息中提取关键词来作为画像特征。另外,图片、音频、视频中,我们通过深度学习等技术也是可以提取关键词来作为画像特征的。
物品画像也可以通过用户行为来刻画。比如某个物品是比较热门的物品,我们可以给该物品打上“热门”的标签。某个物品很受某类人喜欢,也可以给该商品打上相关标签,比如“白领专用”。
(4) 场景化数据
场景化数据是用户在对物品进行操作时所处的环境特征及状态的总称,比如用户所在地理位置、当时的时间、是否是工作日、是否是重大节日、是否有重大事件(比如双十一)、当时的天气、用户当时的心情、用户所在产品的路径等等。这些场景化信息对用户的决策是非常重要的、甚至是起决定作用的。比如,美团饿了么这类基于地理位置服务的产品,给用户推荐餐厅是一定是在用户所在位置或者用户指定收货地点附近的。
恰当地使用场景化数据,将该类数据整合到推荐算法中,可以更加精准地为用户进行个性化推荐,产生更好的使用体验和商业化价值。
按照产品功能要素来划分是一种比较偏业务的划分方式,可以让我们更清晰地看到问题。我们在第三篇中讲解召回算法时,就是按照这4类产品功能要素(即用户行为召回、用户画像召回、物品画像召回、场景信息召回)来展开的。
2. 根据数据载体来划分
随着互联网与科技的发展,网络上传输、交换、展示的数据种类越来越多样化,从最初的数字、类别、文本到图片,再到现在主流的音视频,基于这些数据载体的不同,推荐系统建模依赖的数据可以分为5类,见下面图2。

图2:推荐系统依赖的5种数据载体
(1)数值数据
推荐系统算法用到的可以用数值来表示的数据都属于这一类,比如用户年龄、收入、商品价格、配送距离等等。数值数据也是计算机最容易处理的一类数据,基本上是直接可以用于算法中的。其他类型的数据要想很好地被推荐算法利用,一般会先利用各种方法转化为数值数据(我们会在特征工程那一章讲解具体的方法和策略)。
(2)类别数据
类别数据是这类具备有限个值的数据,类似计算机编程语言中的枚举值,比如用户性别、学历、物地域、商品品牌、商品尺码等等。类别数据也比较容易处理,一般用one-hot编码或者编号就可以转化为数值型数据。当然如果类别数量巨大,用one-hot编码会导致维度很高、数据过于稀疏等问题,这时可以采用hash编码或者嵌入的方法了。
(3)文本数据
文本数据是互联网中数量最多的、最普遍的一类数据,物品的描述信息、新闻文本、歌词、剧情简介等都是文本数据。处理文本类数据需要借助自然语言处理相关技术。比如TF-IDF、LDA等都是比较传统的处理文本数据的方法,当前比较流行的Embedding方法可以获得比较好的效果。
(4)图片数据
随着智能手机摄像头技术的成熟,图像处理软件的发展,以及各类APP的流行,拍照和分享照片更加容易了。另外图片比文本更容易传达信息,因此当前互联网上到处充斥着各种图片,图片数据是互联网上的主流数据类型,商品的展示图、电影的缩略图、用户朋友圈的照片等等都以图片的形式存在。
对于图片类数据的处理,目前的深度学习技术相对成熟,包括图片的分类、对象识别、OCR、图片的特征提取等等,精度已经足够用于产品了,在某些方面(如图片分类)甚至超越了人类专家的水平。
(5)音视频数据
音视频数据我们并不陌生,甚至在移动互联网爆发之前都已经存在了很多年了(录音机和摄像机可以记录声音和视频)。但只有当移动网络及软硬件成熟后,以这两类数据为载体的产品才发展壮大。音频类的产品有喜马拉雅、荔枝FM等,视频类除了爱奇艺、腾讯视频、优酷等长视频APP外,目前大火的抖音、快手等短视频应用非常受欢迎。游戏直播、电商导购直播等应用也是视频类数据的输出媒介。音乐的数字化,各类音频学习软件(如樊登读书、得到APP等)也促进了音频数据的增长。
音视频数据的价值密度小,占用空间多,处理相对复杂,在深度学习时代,这些复杂数据的处理也变得可行了。音频数据可以通过语音识别转换为文字,最终归结为文本数据的处理问题,视频数据可以通过抽帧转换为图片数据来处理。目前比较火的多模态技术也可以直接处理原始的音视频数据。
图片、音视频数据属于富媒体数据,随着传感器种类的丰富(手机、无人机、激光雷达等)、精度的增强(比如拍照能力越来越强)、相关互联网应用的繁荣(如抖音、快手等都是基于富媒体数据的应用),网络上出现了越来越多的富媒体数据,并且占据了互联网数据的绝大多数,因此是非常重要的一类数据,也是未来的推荐系统需要重点关注的数据。
按照数据载体来划分数据的好处是方便对数据进行处理,从中提取构建推荐算法需要的特征。我们在第15章讲解特征工程时,就是按照数据的这种划分方式来讲解的。
3. 根据数据组织形式来划分
按照数据组织形式不同,不同类型的数据处理起来难易程度是不一样的。人类是比较善于理解和处理二维表格类数据(结构化数据)的,这就是为什么关系型数据库(主要是处理表格类数据)在计算机发展史上具有举足轻重地位的原因。随着互联网的发展,数据形式越发丰富,不是所有数据都是结构化的,有些数据是半结构化甚至是无结构化的(具体见下面图3),下面分别对这3类数据加以说明。

图3:三种数据组织形式
(1)结构化数据
所谓结构化数据就是可以用关系型数据库中的一张表来存储的数据,每一列代表一个属性/特征,每一行就是一个数据样本。一般用户画像数据和物品画像数据都可以用一张表来存储,用户和物品的每一个属性都是表的一个字段,因此是结构化数据。下表就是商品的结构化表示。
|
商品 |
品牌 |
价格 |
品类 |
颜色 |
|
iPhone13 Pro |
苹果 |
9888元 |
手机 |
远峰蓝、石墨色、银色、金色 |
|
尼康 D7500 |
尼康 |
7299元 |
数码 |
黑色 |
|
浪琴(Longines)瑞士手表 康卡斯潜水系列 机械钢带男表 L37824066 |
浪琴 |
13000元 |
钟表 |
L37824766、L37824566等 |
表1:商品画像数据的结构化表示
结构化数据是一类具备Schema的数据,也就是每一列数据的类型、值的长度或者范围是确定的,一般可以用关系型数据,如MySQL、ProgreSQL、Hive等来存储,这类数据可以用非常成熟的SQL语言来进行查询、处理。
(2)半结构数据
半结构化数据虽不具备关系型数据库这么严格的Schema,但数据组织是有一定规律或者规范的,利用特殊的标记或者规则来分隔语义元素或对记录和字段进行区隔。因此,也被称为自描述的数据结构。常见的XML、Json、HTML等数据就属于这一类。
对于用户在产品上的操作行为,我们一般按照一定的规则来对相关字段进行记录(比如可以用Json格式来记录日志,或者按照规定的分割字符来分割不同字段,再拼接起来记录日志),这类数据也属于半结构化数据,一些半结构化数据是可以通过一定的预处理转化为结构化数据的。
半结构化数据对推荐系统是非常关键的。推荐系统最终的推荐结果可以采用Json的格式进行存储或者以Json的形式在互联网上传输最终展示给终端用户。很多推荐模型也是采用固定的数据格式存储的,比如ONNX(Open Neural Network EXchange,开放神经网络交换)格式,是一种用于表示深度学习模型的标准,可使模型在不同框架之间进行迁移。
半结构化的数据一般有比较松散的范式,这类数据也有适合的数据存储工具,一般会用key-value形式的NoSQL数据库存储,比如HBase、Redis、MongoDB、Elastic Search等等。
(3)非结构化数据
非结构化数据,是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来存储的数据,也没有半结构化数据这种有一定的规律或者规范。非结构化数据包括文本、图片、各类数据报表、图像和音视频数据等等。非结构化数据由于没有固定的数据范式,也是最难处理的一类数据。
文本、短视频、音频、商品等都包含大量的非结构化数据。即使物品本身是非结构化的(比如抖音上的短视频),我们也可以从几个已知的维度来定义物品,从而形成对物品结构化的描述,如上面表1中就是针对商品从多个维度来构建结构化数据。
随着移动互联网、物联网的发展,各类传感器日益丰富,功能多样,人际交往也更加密切,人们更愿意表达自我,人类的社交和生产活动产生了非常多的非结构化数据,非结构化数据量成几何级数增长。
怎么很好地处理非结构化数据,将非结构化数据中包含的丰富信息挖掘出来,并应于算法模型中,是具备极大挑战的,但是如果利用的好,是可以大大提升推荐算法的精准度、转化率等用户体验、商业化指标的。随着NLP、图像处理、深度学习等AI技术的发展与成熟,我们现在有更多的工具和方法来处理非结构化数据了。推荐系统也享受到了这一波技术红利,在这些新技术的加持下,推荐效果越来越好。
非结构化的数据由于没有固定的范式,一般可以采用对象存储工具进行存储,如Apache Ozone(https://ozone.apache.org/)等。目前基本所有的云服务厂商都会提供对象存储工具,方便客户存储非结构化的对象文件。
上面从3个不同的分类角度来介绍了推荐系统的数据源,我们知道了哪些数据是对推荐系统有用的,当我们获取了这些数据之后我们就需要对它们进行适当的预处理并存储下来,方面后续的推荐系统建模使用。下面一节我们来简介介绍一下数据预处理相关的知识点。
二、数据预处理
数据预处理一般称为ETL(Extract-Transform-Load),用来描述数据从来源到最终存储之间的一系列处理过程,一般经过抽提、转换、加载3个阶段。数据预处理的目的是将企业中的分散、零乱、标准不统一的数据整合到一起,将非结构化或者半结构化的数据处理为后续业务可以方便处理使用的(结构化)数据,为企业的数据驱动、数据决策、智能服务提供数据支撑。
数据基础设施完善的企业一般会构建层次化的数据仓库系统,数据预处理的最终目的也是将杂乱的数据结构化、层次化、有序化,最终存入数据仓库。对于推荐系统来说,通过ETL将数据处理成具备特殊结构(可能是结构化的)的数据,方便进行特征工程,最终供推荐算法学习和模型训练使用。下面分别对ETL3个阶段的作用进行简单介绍。
1. 抽提(Extract)
这一阶段的主要目的是将企业中分散的数据聚合起来,方便后续进行统一处理,对于推荐系统来说,依赖的数据源多种多样,因此是非常有必要将所有这些算法依赖的数据聚合起来的。推荐系统的数据源比较多样,不同的数据抽取的方式不一样,下面分别简单介绍。
用户行为数据一般通过在客户端埋点,通过HTTP协议上传到日志收集web服务(如Nginx服务器),中间可能会通过域名分流或者LB负载均衡服务来增加日志收集的容错性、可拓展性。日志一般通过离线和实时两条数据流进行处理。离线数据通过预处理(比如安全性校验等)进入数仓,实时流经Kafka等消息队列,然后被实时处理程序(如Spark Streaming、Flink等)处理或者进入HBase、ElasticSearch等实时存储系统供后续的业务使用。用户行为日志的收集流程见下面图4。
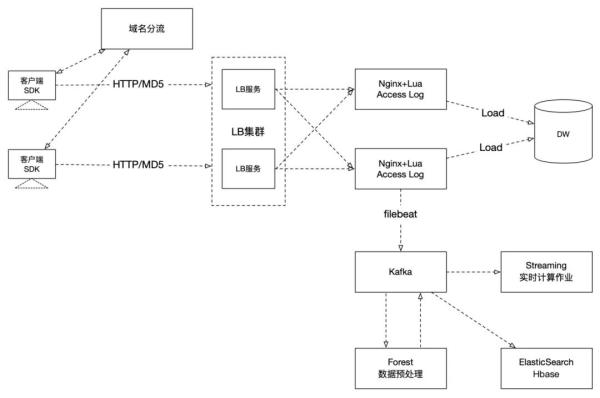
图4:用户行为日志收集流程(右上角进入DW的属于离线数据,右下角经过Kafka的属于实时流)
对于用户画像数据、物品画像数据一般是存放在关系型数据库中的,实时性要求不高的推荐业务可以采用数据表快照(按天从业务系统中将数据库同步到Hive中)进行抽取,对实时性有要求的信息流推荐可以采用binlog实时同步或者消息队列的方式抽取。
场景化相关数据一般是描述用户当前状态的数据,一般是通过各种传感器或者埋点收集的,这类数据也生成于客户端。通过上面图4右下角的实时日志收集系统进入消息队列,供后端的实时统计(如时间序列数据库、ES进行存储进而查询展示)或者算法(通过Spark Streaming或者Flink等)进行处理。
2.转换(Transform)
这个阶段是ETL的核心环节,也是最复杂的一环。它的主要目标是将抽取到的各种数据,进行数据的清洗、格式的转换、缺失值填补、剔除重复等操作,最终得到一份格式统一、高度结构化、数据质量高、兼容性好的数据,提供给推荐算法的特征工程阶段进行处理。
清洗过程包括剔除掉脏数据、对数据合法性进行校验、剔除无效字段、字段格式检查等过程。格式转换是根据推荐算法对数据的定义和要求将不同来源的同一类数据转为相同的格式,使之统一化、规范化的过程。由于日志埋点或者数据收集过程中存在的各种问题,真实业务场景中,字段值缺失是一定存在的,缺失值填补可以根据平均数或者众数进行填补或者利用算法来学习填充(如样条差值等)。由于网络原因日志一般会有重传策略,导致重复数据,剔除重复就是将重复的数据从中过滤掉,从而提升数据质量,以免影响最终推荐算法的效果(如果一个人有更多的数据,那么在推荐算法训练过程中,相当于他就有更多的投票权,模型学习会向他的兴趣倾斜,导致泛化能力下降)。
3. 加载(Load)
加载的主要目标是把数据存放至最终的存储系统,比如数据仓库、关系型数据库、key-value型NoSQL中等。对于离线的推荐系统,训练数据放到数仓中,画像数据存放到关系型数据库或NoSQL中。
用户行为数据通过数据预处理一般可以转化为结构化数据或者半结构化数据,行为数据是最容易获得的一类数据,也是数据量最大的一类数据,这类数据一般存放在分布式文件系统中,原始数据一般放到HDFS中,通过处理后的行为数据都会统一存放到企业的数据仓库中,离线数据基于Hive等构建数仓,而实时数据基于HBase等构建数仓,最终形成统一的数据服务,供上层的业务使用。
某些数据,比如通过特征工程转化为具体特征的数据,这类数据可能需要实时获取、实时更新、实时服务于业务,一般可以存放在HBase或者Redis等NoSQL中。
用户画像、物品画像数据一般属于关系型数据,这类数据比较适合存放在关系型数据库(如MySQL)或者NoSQL中。
对于图片、音视频这类比较复杂的非结构化的数据,一般适合存放在对象存储中。当前比较火的数据湖技术(如Delta Lake、Iceberg、Hudi等)就是希望整合以数仓为主导的传统结构化数据存储与以图像音视频为主的非结构化数据。在数据湖体系下,推荐系统依赖的所有数据源都可以存储在数据湖中。
总结
推荐系统是机器学习的一个分支,因此推荐算法依赖数据来构建模型,最终为用户提供个性化的物品推荐。本章简单梳理了推荐系统的数据源及数据预处理相关的知识点。
推荐系统数据源可以按照3种形式来分类。按照推荐产品功能要素来划分,可以分为用户行为数据、用户画像数据、物品画像数据和场景化数据四类。按照数据载体来划分,可以分为数值数据、类别数据、文本数据、图片数据、音视频数据等5类。按照数据组织形式来划分,可以分为结构化数据、半结构化数据与非结构化数据。
当我们获得了各类不同的、可以用于推荐系统模型构建的数据,我们还需要将这些数据收集、转运、预处理并存储到数据中心。当所有的数据都准备就绪了,后面我们才可以基于这些数据去构建算法模型。我们会在后续章节具体介绍推荐系统相关的算法模型。

