
前言
日常工作中,缓存的使用随处可见。缓存使用得当,对提升系统的性能,提高用户体验感有着至关重要的作用。但是如果使用不当,就会出现一些令人费解或者数据混乱的问题。本文将给大家普及常见的一些缓存使用与缓存使用过程中的踩坑点,希望能帮助大家更好的理解与使用缓存,文中如有写的不对的地方,欢迎大家留言指正。
java缓存形式/介质
众所周知,缓存之所以访问速度快,是因为把缓存的交互介质是内存。而常规的例如mysql数据交互介质是磁盘。那么常见的java中或者中间件供我们可以用来做缓存的开发的工具有几种呢?
jvm本地内存
jvm本地内存常见使用为定义一个全局静态变量,保证后端服务在运行过程中,对应的对象空间直接保持被引用,不会被GC给回收。
guava缓存工具类
存储数据的本质与jvm内存类似,内部依靠维护java集合的子类来存储数据,但是提供了缓存数据的过期时间,过期策略等设置,像一个小型的中间件。
redis
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。常用作数据库、缓存和消息代理。Redis 提供了诸如字符串、散列、列表、集合、带范围查询的排序集合、位图、hyperloglogs、地理空间索引和流streams等数据结构。Redis 内建复制、支持 Lua 脚本、支持 LRU 缓存淘汰策略、事务和不同级别的磁盘持久化,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。同类型中间件中,Redis是最火的,没有之一。
几种常用缓存的对比
| jvm缓存 | guava缓存 | redis缓存 | |
|---|---|---|---|
| 速度 | 第一 | 第二 | 第三 |
| 缓存数据是否占用jvm内存 | 是 | 是 | 否 |
| 提供过期时间等策略 | 否 | 是 | 是 |
| 能否缓存大量数据 | 否 | 否 | 是 |
| 应用重启缓存是否丢失 | 是 | 是 | 否 |
| 使用场景 | 字典类型数据,加载后修改频率低 | 支持jvm缓存所有功能,并且适合与缓存token类型具有时效性的数据 | 支持guava缓存所有功能,支持日常工作所有缓存场景,应用系统数据重启与否不影响缓存数据的加载与使用 |
缓存常见的坑
在分析缓存的坑之前我们先来看一下缓存的增删改查如何保证数据库与缓存的数据一致性。
查询
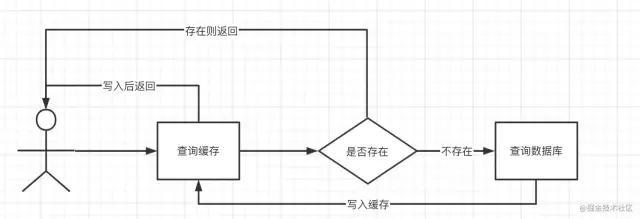
查询时先查询缓存,如果缓存存在直接返回,不存在则查询数据库,将数据库查询结果写入缓存【此处默认数据库存在数据,不存在的情况后面分析】,然后将缓存的结果数据返回。
增删改
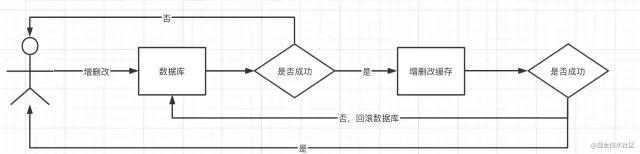
增删改时先增删改数据库,保证数据库数据先被修改,然后同步缓存内数据,如果中间发生异常,则调用数据库事务回滚数据。
缓存穿透
概念
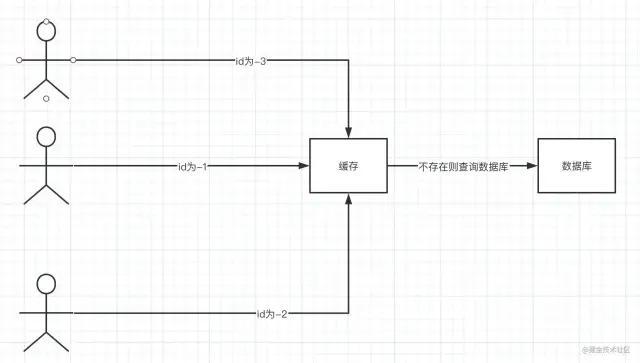
正常情况下,查询的数据都存在,如果请求一个不存在的数据,也就是缓存和数据库都查不到这个数据,每次都会去数据库查询,这种查询不存在数据的现象我们称为缓存穿透。如上图,用户一直请求接口查询不存在的id数据【数据库中只存在id>0的数据】,对应的数据永远不可能在缓存中。在高并发场景下,大量请求打到了数据库,数据库可能被突发的流量给打挂。
3.1.2.解决方式
1.过滤垃圾数据
在知道查询的id数据大于0或者基于id是某种规则【例如雪花id】生成的情况下。过滤掉数据库中不可能的存在的请求。方法入口直接增加一个参数校验。
2.缓存空值
发生穿透的原因是数据在数据库中不存在,那我们把null值给缓存下来,当请求到达时直接返回null。当然这里对缓存是必须加上过期时间的,以免后续真的存在此id的数据。过期时间不宜过长,根据实际业务场景并发量来进行设置。
3.IP拦截
对于恶意的攻击请求,一直请求无效的数据,可以设置ip请求策略。如果对应的ip短时间内发起了大量请求,且请求参数均为不存在的数据。则将ip进行封禁一段时间,不允许再次请求系统。
**4.布隆过滤器
布隆过滤器(BloomFilter)用来判断某个元素(key)是否存在于某个集合中我们把有数据的key都放到BloomFilter中,每次查询的时候都先去BloomFilter判断,如果没有就直接返回null 。
注意BloomFilter没有删除操作,对于删除的key,查询就会经过BloomFilter然后查询缓存再查询数据库,所以BloomFilter可以结合缓存空值用,对于删除的key,可以在缓存中缓存null
缓存击穿
严格意义上说缓存穿透是缓存击穿的一种。只不过缓存击穿是查询的有效数据。在高并发情况下,查询缓存时,缓存中的数据不存在或者已经失效了。那么会导致大量的请求打到了数据库,打挂数据库
解决方式
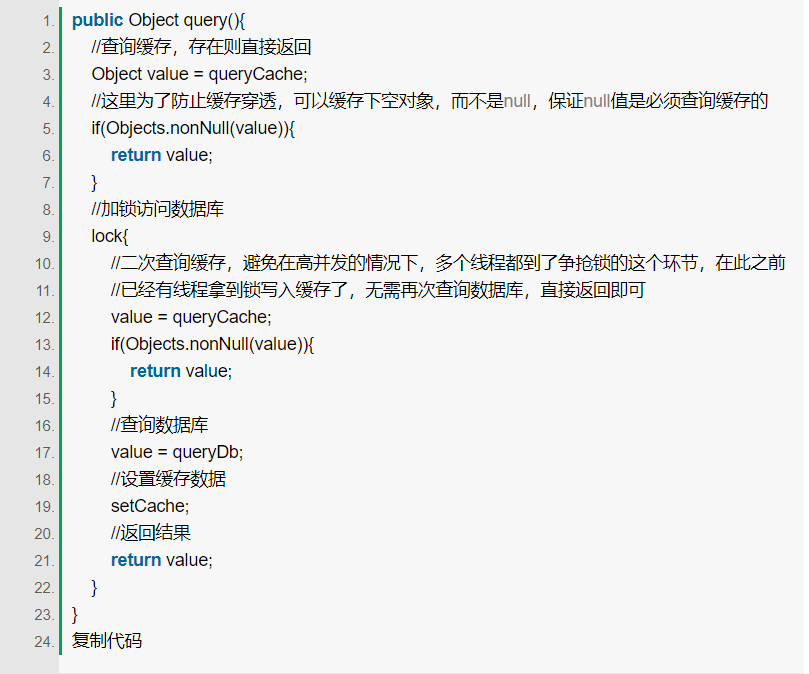
先来分析一下场景,大量请求同时到了缓存,缓存不存在,再请求数据库。然后再将请求结果写入到缓存。问题就是多个线程几乎同时读取缓存,又几乎同时重写缓存。多线程并发下解决问题,当然是用锁。单体应用可以使用synchronized关键字或者ReentrantLock进行加锁,分布式服务则可使用分布式锁的方式来实现加锁。
大致的伪代码如下:
缓存雪崩
概念
缓存雪崩也是缓存击穿的一种,缓存设置了过期时间/淘汰策略的情况下,在某个时间点,大量的缓存失效。高并发情况下大量请求打到了数据库。
解决方式
缓存雪崩时,请求方式与缓存击穿一致,主要如何防护缓存雪崩,基本指导思想为:
热点数据设置永不过期,缓存淘汰策略为淘汰最早过期数据
数据缓存过期时间设置高离散度随机值,避免某个时间点,大量缓存同时过期。
性能问题
概念
使用了缓存,但是性能还是上不去的场景。例如双十一场景下,订单数据量比较大。如果新增修改删除所有操作都要先操作一遍数据库,再回写缓存的话效率是很低的。
解决方式
把缓存当做数据库来使用,当然这里需要使用redis这种高可用的持久化缓存中间件。数据存在redis中,数据交互都直接交互redis。扛过流量高峰之后,启用定时任务,将redis的数据刷入至数据库或者ES。当然这里也可以使用消息队列,这里不具体展开。
总结
本文着重讲述了缓存的增删改查策略与日常坑点。
数据一致性
查询操作,先走缓存再走数据库,再更新缓存。
增删改操作,先走数据库再更新缓存。
坑点
从缓存雪崩去理解缓存穿透与缓存击穿。
高性能
读写持久化缓存数据,异步刷盘mysql。
本文转载自微信公众号「码农小胖哥」,可以通过以下二维码关注。转载本文请联系码农小胖哥公众号。


