
本文的读者
-
你为代码总是被同事们写乱了而苦恼,但是又无法 Review 每一行代码
-
你要开发一个 SaaS,实现各种复杂功能的组合,但是又不能像互联网公司一样堆很多人来开发微服务
-
你模仿过主流的微服务,DDD 等做法,但并没有达到理想的效果,不介意尝试一些非主流的新办法
本文的目标是以尽可能浓缩的篇幅提供可模仿的步骤来达成“如何不 Review 每一行代码,同时保持代码不被写乱”的目标。总共三步
-
第一步:不要拆分代码仓库,不要拆微服务。Monorepo is all you need,Feature Toggle is all you need。
-
第二步:管控集成类需求的代码审查:主板加插件。
-
第三步:管控规范型需求的代码审查:独家收口。
第一步:不要拆分代码仓库,不要拆微服务
拆分微服务以及代码仓库的缺点
-
利用组织边界来强化代码的分工边界会导致将来调整阻力很大。我们对于代码应该如何组织的认识是随着新需求不断调整的。不要轻易动用“组织架构”这样的核武器来达成小目标。
-
拆分了代码仓库之后不利于在编译期做集成,做集成后的整体验证。即便运行时集成有万般好处,也没有必要丧失掉编译期集成的选项。
-
跨代码仓库的代码阅读,开发时的辅助和检查都会变困难。
-
微服务控制变更风险的灰度边界是固化的,也就是微服务的大小。切得越细,每次变更的东西就越少,风险就越小。这不够灵活。
-
微服务的弹性边界是固化的,如果某种视频编辑需要特别多的内存,我们希望独立伸缩,就得把这部分代码切割出来变成一个独立的微服务。
拆分微服务和代码仓库相比单体架构,最重要的目标是减少分支冲突,控制发布变更的风险。但是拆分微服务和代码仓库并不是最佳的解决方案。Monorepo + Feature Toggle 是更好的解决方案。
-
Monorepo:所有的代码都在一个仓库里。这样就不存在不同模块的仓库有不同的版本问题。大家都是统一的一个版本。升级线上系统的过程拆分成:部署+发布,两个步骤。部署的时候,整个 Monorepo 的代码都部署到目标机器上了,但并不代表发布了。
-
Feature Toggle:特性开关来精确控制哪些逻辑分支被发布出去。这样部署就和发布解耦了。要灰度多少比例,可以精确控制。要一个特性开关的两个版本的逻辑分支共存,也可以实现。
使用 Monorepo + Feature Toggle 可以提供所有拆分微服务达成的目标,同时克服以上微服务拆分带来的缺点
-
通过目录结构来控制代码所有权。你可以要求这个目录下的代码必须经过你的 Code Review。调整目录结构比调整代码仓库容易得多,比调整组织架构要容易得多。
-
可以保持编译期集成这个选项。
-
可以更容易实现开发时辅助和检查工具,可以很方便地阅读跨模块的代码
-
变更风险更小,不仅仅开关回滚很快,而且开关可以灵活地定向灰度,而且一个开关的控制范围大小也可大可小,粒度非常灵活。
-
弹性边界更灵活,不需要因为要独立扩缩容,就得把代码切分出去
经常听说的一个说法是最终是要拆分成微服务,多仓库的。单体应用单仓库只是一个过度形态。这会导致我们认为为啥 不 一步到位呢。 但事实并非如此,微服务和多仓库并不一定适合所有人。 你可以用 Monorepo + Feature Toggle 用一辈子。
具体如何实践 Monorepo + Feature Toggle 按照 https://www.branchbyabstraction.com/ 和 https://trunkbaseddevelopment.com/ 的指导去做就可以了。
第二步:管控集成类需求的代码审查
当我们把代码都放一个代码仓库里之后,立即要面临的问题是代码不会写乱么?你怎么控制什么代码写在哪里?每一行代码写之前都来问你,每一行代码写完了都需要你来 Review 么?
所以,我们需要一种强制检查代码写在了正确的位置的自动化机制。这个机制就叫“依赖管理”。对应常见的编程语言
-
如果是 TypeScript,这个叫 package.json
-
如果是 Golang,这个叫 go.mod
-
如果是 Java,这个叫 POM.xml
当我们把代码拆分成多个包(或者叫模块),并使得这些包(模块)形成特定的依赖关系,就可以通过编译器检查控制什么代码必须写在什么地方,从而不需要靠人去检查。这个依赖关系如下图所示
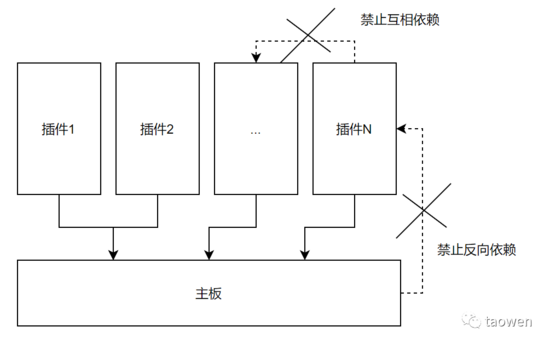
-
插件:尽可能完整的实现一个独立的功能,比如面向最终用户的完整的页面
-
主板:当插件与插件之间有功能上的集成需要的时候,通过绕路主板来实现,而不能直接在插件和插件之间有引用关系
这样做的好处是可以减少 Review 的负担。不需要盯着每一行代码了,只需要重点盯着主板的修改就可以了。实现的步骤是
-
先决定每个插件里封装什么的数据库表。如果是前端模块,则是封装什么后端的数据接口
-
因为插件不能引用插件,所以对应的页面和功能就会自然选择有这些数据库表的插件里来写。因为写在其他插件里的话就访问不到了
-
然后对于需要来自多个插件数据才能实现的功能,我们通过主板来实现
比如说我们决定有一个团购插件,有一张表 GroupPurchaseCampaign 记录了团购活动的参与商品和规则。那么要展示团购活动列表的时候,就会自然有限选择在团购插件里来写,因为这个插件里可以访问这张表。这里说的“访问”是指可以 import GroupPurchaseCampaign 这个类型的意思。插件不能 import 另外另外一个插件定义的类型,但是不意味着运行时不能访问别的插件的数据。运行时的数据都是通的。限制的是编译期,谁可以 import 谁。
当需要主板进来实现”集成类需求”的时候,应该如何做。分为以下三类
-
一个界面需要同时展示来自两个插件的数据。例如商品详情页,需要常规商品数据,需要当前的券活动,需要当前的限时折扣活动等。在主板里把界面分成多个槽,然后不同的槽由不同的插件来实现。
-
一个操作需要多个插件的数据进行综合决策判断。例如计算价格的函数,需要综合商品的原价,需要取得购物车选择券,需要判断是否满减等。在主板里把价格的计算流程里留出槽,然后不同的槽由不同的插件来实现。
-
一个插件的界面里需要展示来自其他插件的数据。例如退款申请界面,需要展示商品图片等。这个不同之处在于整个页面绝大部分都是由一个插件自己实现的,只是在局部的地方需要其他插件的数据。所以就不值得把整个页面都下沉到主板里去写。实现方法是在主板里声明一个ProductCard组件,然后这个组件由常规商品插件实现,再由退货插件来使用用。
主板起到的作用和 C 编程里的“头文件”的作用是一样的,就是给模块之间相互调用提供声明。主板的代码要尽可能的少,绝对不要在主板里提供 CRUD 的裸数据接口,主板里定义的是界面的槽,流程的槽,而不是直接把数据库的原始数据暴露出去。
技术上如何实现:在一个包里提供声明, 在 另外一个包里写实现。 这个有两类做法:
-
通过运行时多态来实现。在主板里定义 interface,在插件里写实现 interface 的类的或者函数。然后在启动的时候,做一次 “AutoWire” 的绑定操作。这个绑定最简单的方式可以是对类型为函数指针的全局变量做一下赋值操作。也可以由 Spring 这样的依赖注入框架来做 AutoWire。
-
通过编译期做源代码的复制粘贴。需要在编译之前先对源文件做一下处理,然后再喂给编译器。
无论是哪种具体实现技术,都不要实现成如下图所示这样
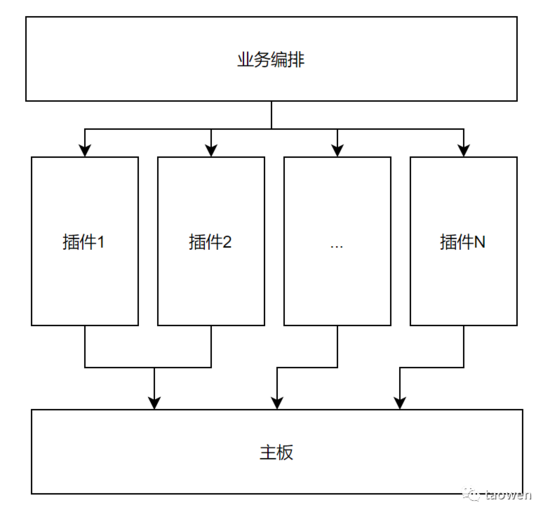
在插件之上 不应该有 一个额外的包(模块)包含业务逻辑了。插件对主板的插入应该是一个 AutoWire,纯机械不含业务的过程。业务编排这样的概念一定不要出现在依赖关系的最顶层。我们已经在最底下的主板实现了所谓的“业务编排”了。
SaaS 可以把自己的功能拆解到多个插件来实现。但是经常有“按需”组装,或者付费购买的需求。我们并不需要动态来组装代码来获得“按需”组装的产品效果。代码可以是一份,只是通过运行时的开关来控制某些插件是否启用。这些开关可以是配置文件,也可以是数据库表来控制。在没有启用的时候,界面上完全隐藏相关的组件(就是 if/else 判断),用户也察觉不到这个功能的存在。付费购买其实就是付费买这个开关,也不需要像 Apple Store 那样真的去做什么代码下载和安装。当然给外包公司做二次开发就是完全另外一个话题了,与本主题无关。是否打开某个插件可以是全局性的(给每个商家或者租户启用),也可以是“订单”级别。一个所谓的订单履约流程,需要组合多个插件的功能。对于每个订单来说,都有一堆 bit 开关来决定某个插件是否启用了,以及对应的业务数据是什么。比如 GroupPurchase + OrderSelfPickup + Order 可以组合成团购自提的订单。订单在此处只是一个例子,不同类型的业务有自己的领域概念。
第三步:管控规范型需求的代码审查
有了主板加插件,Monorepo 已经切分出了多个子目录了。每个开发者也基本上能够知道什么需求写在什么目录下,哪些目录是自己经常修改的。接下来的问题是,如果每个开发者都各写各的,那他们之间有重复实现怎么办?谁来避免同一个东西,被不同产品经理提出多遍,再由不同的开发者用不同的姿势实现多变,导致浪费和返工?这个也是一个 Code Review 的问题。不能指望有一个人来 Review 每一行代码。
解决办法就是我们希望有一个人来“收口”,然后由这个人来保证收口之后的代码没有重复的实现,建立合理的抽象。如下图所示
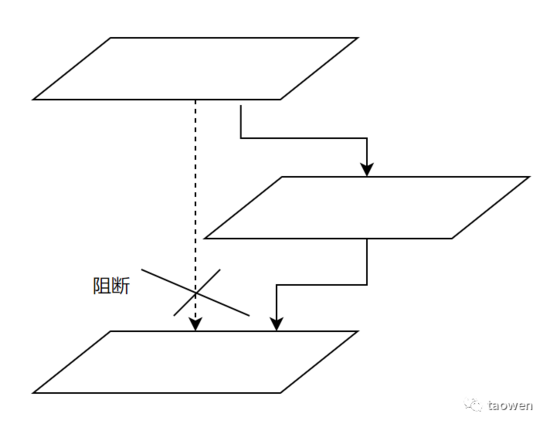
所谓“收口”,就是要阻止上图中这样的绕过“这层抽象”,去访问“底层API”的行为。比如说,所有的编程语言都提供了 Http 调用的能力。但是我们希望封装一个 Http Restful API 的调用 SDK。在这个 SDK 里我们统一实现重试,统一实现熔断摘除故障节点这样的一些功能。避免每个调用 Restful 接口的地方都重复地 try catch,重复地写不一致地重试逻辑。那就需要有一个人来封装这样的库,同时强制所有“应该使用这个库的地方”都使用了这个库。
实现方案要比管控集成类需求要稍微麻烦一些。集成类需求可以用包之间的依赖关系来约束什么代码写在哪里,规范型需求的问题是假设一个业务包,比如团购。它依赖了 Http Restful SDK,而 Http Restful SDK 又依赖了 Http 的库。那么就意味着团购这个包通过依赖的传递性,也依赖了 Http 的库。在现有的编程语言里,都无法禁止团购的包通过传递性依赖获得的调用 Http 库的权利。这个时候我们就需要通过自制 lint 工具的方式,在编译期额外做更严格的依赖关系检查。通过 lint 检查,强迫所有访问 Http 库的代码都“收口”到某个目录里。然后我们就可以通过 Review 这个目录的改动,确保重试逻辑只写了一份,而不是散落到各个地方。
这样的 lint 规则可以检查以下类型的访问
-
对某个 API 是否可以调用:比如 Http 库的 API
-
对某个自定义类型是否可以调用其指定的方法:比如 Datetime 类型,或者业务上自己封装一个 Money 类型
-
对某个 API 的某几个参数是否可以传值:比如组件库中的 Button 组件提供了 style 属性,我们不希望把这么灵活的属性暴露出去
-
对语言和框架某些特性是否可以使用:比如 vue 文件中可以写 style,但是我们不希望所有的目录都可以写 style
再举一个例子。通过 lint 检查,我们可以确保所有包含样式的前端组件都写在某个目录下,比如说 RegularUi 和 SpecialUi。其他目录中的组件,只能是通过组装 RegularUi 和 SpecialUi 目录中的组件来完成自己的设计稿还原。当然这样就是一种“收口”。我们可以通过 Review 对 RegularUi 和 SpecialUi 这两个目录下文件的修改,来发现是不是有两个开发者在尝试实现极度类似的页面组件,也可以促成两个产品经理互相交流一下,是不是把两个组件合并成一样的行为,避免不必要的实现成本。
“收口”的代价是不可避免会出现很多一次性的需求,个性化的需求。比如优惠券的界面就是要和其他界面不一样。因为对样式做了收口,所以就不能直接写在优惠券这个包里面。于是就有了 SpecialUi 这个目录,用于写被收口了,但是并不可复用的东西。SpecialUi 里的组件数量的多寡,体现了 Ui 不一致性的严重程度。如果每个页面都不一样,都非常有艺术感。那说明这样的产品并不适合对样式进行收口,就应该各写各的,每个页面都纯手工打造。
“收口”的 lint 检查的关键是要去掉对人的主观判断的依赖。我们不需要判断这里来是不是一定能复用 RegularUi。我们宁愿过度收口,导致 SpecialUi 的出现,也要避免人为主观判断的介入。这种“过度的”收口,是规范型需求能实现自动化检查的关键。一旦我们允许酌情出现一些例外的情况下,那么又变成了需要 Review 每一行代码了。
“收口”之后的一个风险是强行抽象。明明不适合复用同一个组件的场合,仍然复用了同一个组件。导致组件变得更复杂,导致组件经常被修改。一个对策是控制组件或者函数的参数个数,参数应该尽可能地少。如果某个函数在 Monorepo 中有10处调用,但是其名为 IsVipUserPriviliged 参数仅仅在 1 处调用有传值。那么这个 IsVipUserPriviliged 参数大概率是不应该被添加进来的,是强行抽象的产物。对于 IsVipUserPriviliged 的处理,更适合直接写在调用的地方,而不是被写到可复用的目录里。
收益
在这三步都完成之后,你获得了一个“机器人”。它帮你在每个开发者提交代码的时候检查代码是不是写到了正确的位置。 在 通过了这个机器人检查的基础上,你只需要关注重点的一些目录就可以了,对其他的修改仅仅需要抽查。 这个机器人能够像拆分了微服务一样,确保代码不写乱。 同时不像微服务那样,拆分之后就很难调整了。 因为代码仍然一个仓库里,只是分了目录,随时都可以再调整。

