Hello,我是瓜哥:
之前在进行对接存储项目的时候,对公司内部使用的文件系统进行了梳理,当前公司内部使用的文件系统有GlusterFS,FastDFS等,由于文件系统在海量小文件和高并发之下性能急剧下降,性能遭遇瓶颈,因此打算建设分布式对象存储平台。下面对市面上比较流行的非结构化文件存储产品进行相关整理和比较。

分布式文件存储的来源
在这个数据爆炸的时代,产生的数据量不断地在攀升,从GB,TB,PB,ZB.挖掘其中数据的价值也是企业在不断地追求的终极目标。但是要想对海量的数据进行挖掘,首先要考虑的就是海量数据的存储问题,比如Tb量级的数据。
谈到数据的存储,则不得不说的是磁盘的数据读写速度问题。早在上个世纪90年代初期,普通硬盘的可以存储的容量大概是1G左右,硬盘的读取速度大概为4.4MB/s.读取一张硬盘大概需要5分钟时间,但是如今硬盘的容量都在1TB左右了,相比扩展了近千倍。但是硬盘的读取速度大概是100MB/s。读完一个硬盘所需要的时间大概是2.5个小时。所以如果是基于TB级别的数据进行分析的话,光硬盘读取完数据都要好几天了,更谈不上计算分析了。那么该如何处理大数据的存储,计算分析呢?
常用的分布式文件存储
常见的分布式文件系统
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存 储服务。
分布式文件存储选型比较
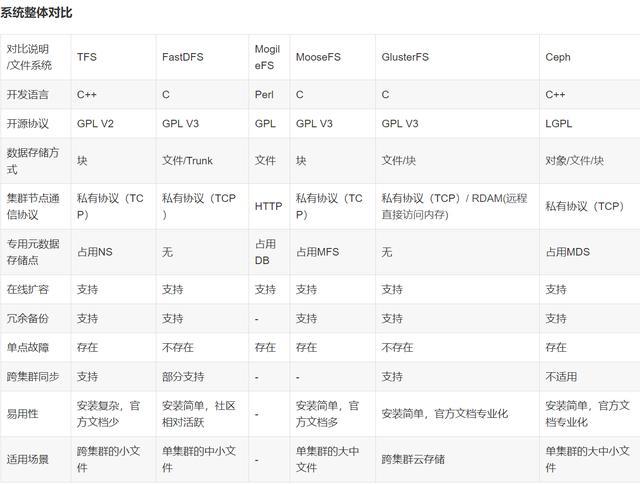
知名开源分布式文件存储
1.GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
2.HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,
后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
3.TFS
TFS(Taobao FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠
和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
Google学术论文,这是众多分布式文件系统的起源,HDFS和TFS都是参考Google的GFS设计出来的。
典型的分布式文件存储的架构设计
我以hadoop的HDFS为例,毕竟开源的分布式文件存储使用的最多。
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
大规模数据集
运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
简单的一致性模型
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
异构软硬件平台间的可移植性
HDFS在设计的时候就考虑到平台的可移植性。这种特性方便了HDFS作为大规模数据应用平台的推广。
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
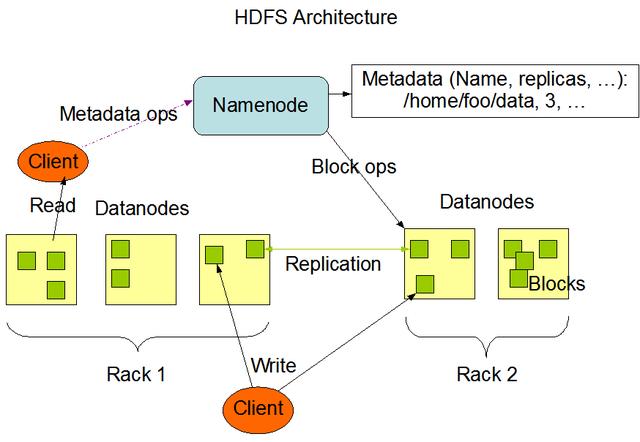
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
分布式存储的未来
随着现代社会从工业时代过渡到信息时代,信息技术的发展以及人类生活的智能化带来数据的爆炸性增长,数据正成为世界上最有价值的资源。
根据物理存储形态,数据存储可分为集中式存储与分布式存储两种。集中式存储以传统存储阵列(传统存储)为主,分布式存储(云存储)以软件定义存储为主。
传统存储一向以可靠性高、稳定性好,功能丰富而著称,但与此同时,传统存储也暴露出横向扩展性差、价格昂贵、数据连通困难等不足,容易形成数据孤岛,导致数据中心管理和维护成本居高不下。
分布式存储:将数据分散存储在网络上的多台独立设备上,一般采用标准x86服务器和网络互联,并在其上运行相关存储软件,系统对外作为一个整体提供存储服务。。
总之,分布式文件存储,不仅提高了存储空间的利用率,还实现了弹性扩展,降低了运营成本,避免了资源浪费,更适合未来的数据爆炸时代场景。

