Netflix 是欧美地区最大的网络视频提供商,用户超过了 Youtube。全球每天有超过 190 个国家,一亿多会员在 Netflix 上观看 1.2 亿小时的电影、电视剧和纪录片等等。同时,Netflix 也制作了像纸牌屋这样的广受欢迎的电视剧。

为了支持大流量,高并发的访问,Netflix 网站架构经过了一系列的重构。

上图是 2008 年之前 Netflix 的网站架构,从图中我们可以看到这是一个非常传统的架构。
为什么要实现微服务的转型?因为 Netflix 有足够痛的经历,Netflix 在 2008 年曾经遭遇过一次 4 天的服务宕机,原因是他们生产环境的数据库挂掉了,并且经过 4 天才得以修复。
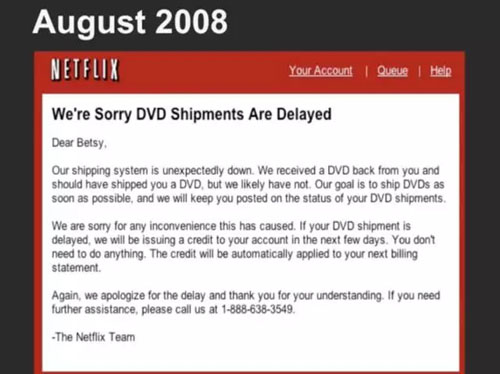
这是 2008 年 Netflix 给受影响用户所发送的道歉邮件。当时所有的用户都收不到他们自己订购的 DVD。难以想象 4 天的宕机,业务停滞,为整个开发团队带来多大的压力。
痛定思痛,Netflix 决定转型微服务架构,来实现高可用,动态扩容,来应对越来越多的用户访问。
Netflix 用了 7 年时间完成了这个转型,目前,Netflix 的云平台上运行了 500 个微服务,每天会有 100-1000 的变更部署到线上环境。
线上环境部署在亚马逊 3 个 Region,9 个可用区,为全球用户提供稳定的网络视频服务。下面来看看 Netflix 实现微服务的原则和经验总结。
Netflix 微服务开发原则
01购买 VS 自己开发
当 Netflix 需要一个功能时,如果有现有的方案可以购买(当然这里的“购买”不仅仅是购买第三方的服务,也包括开源软件的使用和贡献。),他们会选择不去开发这个功能。
只有在市面上或开源社区里没有解决方案时,他们才会考虑自己开发这个功能。这样做的目的,是快速的实现需求,提供服务,而不是将大把的研发资源投入在重复造车轮上。
02实现真正无状态服务
不依赖 Sticky Session,你的服务是否是真正的无状态?这可通过破坏性测试(Chaos Monkey)来验证。
由于 Netflix 无法在测试环境完全模拟出真实的线上环境,导致很多微服务的可用性问题在测试环境测试时没法发现,但是在线上环境却频繁发现微服务并不是完全高可用,于是 Netflix 决定在线上环境进行破坏性测试。
Chaos Monkey 的作用是识别云环境中的服务,然后随机的对他们进行关闭,对系统实施破坏。
可采取的破坏性措施包括:关闭特定服务接口,关闭特定缓存服务,关闭特定 DB 服务,增加网络丢包率,增大网络延迟等。通过这样的测试来确定自身的微服务是不是真正做到无状态。
运行破坏性测试的时机一般是特定的时间点和特定的时间段。Netflix 每周一,五凌晨 3 点会在生产环境上进行自动化的破坏性测试,来确保他们的服务在生产环境上是真正无状态的。
这里需要注意的是,他们是在生产环境上做破坏性测试,因为你永远无法模拟和生产环境一模一样的环境。这样的测试场景能够保证线上碰到问题,能够从容应对。
03向上扩展 VS 水平扩展
如果一味的为去提高机器性能,增加 CPU、内存,终将有一天会遇到瓶颈。如果系统支持水平扩展,那么系统扩容的空间是很难达到瓶颈的,特别是在云环境,你可以更容易的获得足够的计算资源。
04弹性伸缩的冗余和隔离
任何节点都应该有超过一个的冗余备份,来避免单点失败。在你的集群里,是否能够支持关掉任何一个节点,且你的集群还能正常运行?
如果不能,就说明存在单点失败。一旦发生服务异常,要将服务影响到的范围做隔离。
Netflix 微服务开发实践
01从关系数据库迁移到 Cassandra
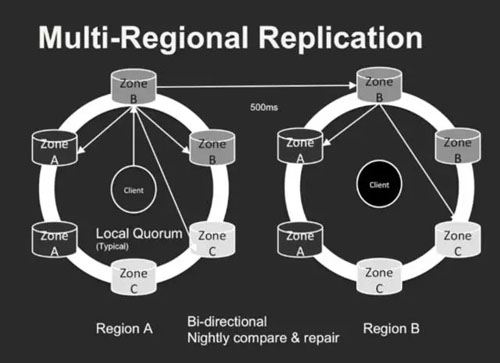
Netflix 的开发者为 Cassandra 数据库贡献了很多源代码,其中一个功能就是做跨 Region 的异步数据一致性处理。
02Netflix 如何定义优先级

如何定义任务的优先级?对于这个问题,每个团队都会有不同的的选择。
在 Netflix,优先级最高的任务是创新,可靠性是排第二位的,这样可以保证员工有足够大的空间进行创新,让产品能够快速的迭代。
03端到端的负责
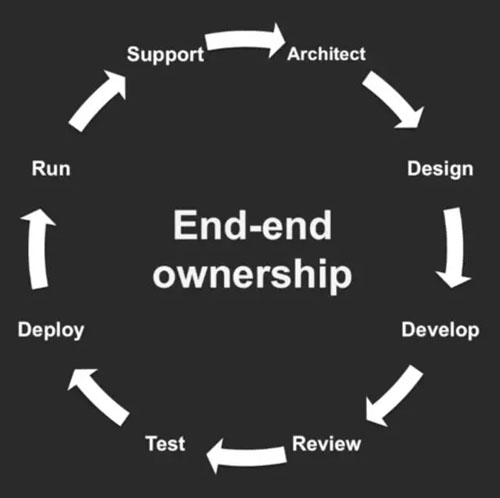
每个团队自行负责产品的设计,架构,开发,构建,部署,运维,支持。团队各自发布自己的模块,团队间模块解耦,升级时向下版本兼容,互不影响。

当每个团队都独自管理自己的服务时,你会发现公司的组织结构变成上图所示的样子。每个团队更加的灵活,发布的速度更快,尝试新技术的意愿也更加强烈。
04区分关注焦点
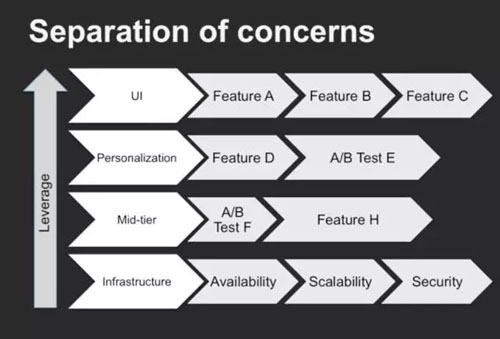
为了让所有业务团队能够独立的交付他们的服务,Netflix 内部有 SRE 团队,为所有业务开发团队提供基础工具链的支撑。
SRE 团队关注的问题是基础设施,中间件的提供和运维,包括性能,可靠性,扩展性,安全漏洞,监控等等;业务部门关注的是功能,页面交互等等。
让每个团队关注不同的问题,这样的好处是保证团队不会重复去解决相同的问题。
Netflix 微服务经验总结
01微服务是组织结构的变化
当你的组织决定接受全部的变化,那就意味着,你不再需要测试团队,运维团队。这很困难,大部分人不愿意接受变动,这是人员的问题,会被情绪干扰。
之前 Netflix 有测试、DBA、运维的团队,现在每个团队自己负责这些任务,SRE 团队负责底层的基础架构和中间件的支持。
02微服务的落地需要时间
进行微服务落地的这个阶段,你会经历:
维护两套系统。
支持两种技术栈。
多主节点数据同步。
03使用缓存保护数据库
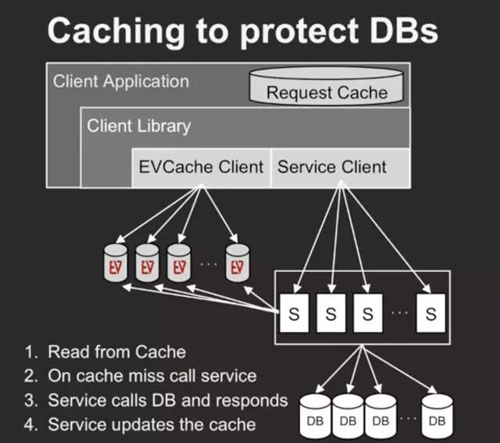
Netflix 基于 MemCache 开发了 EVCache。目的在于让更多的缓存被命中。如果没有命中,请求会访问到数据库,这时需要在缓存里补上这条记录。
04重视运维可视化
在每个服务器上,管理员需要看多少监控报表?Netflix 每秒生成 2 千万监控数据,这些是人工完全无法去观察的,所以需要从这些数据里过滤出哪些是异常数据。
日志也有同样的需求,需要具备从大量数据中消除噪音的能力,并且将这些数据可视化出来,有了可视化的数据,你才能够对流程进行改进。
05服务故障处理
首先确认故障的级别是核心业务故障还是非核心业务故障。同时你需要让服务以最快的速度回滚。
Netflix 孵化并开源了一个工具叫做 Hystrix。这个工具的作用是帮助分布式服务中增加延迟容错和故障回滚的逻辑。在服务发生故障时,帮助你隔离故障服务的访问接口,提供回滚机制,确保故障不会大面积扩散。
进行 Region 级别的破坏性测试,Netflix 举行了一个"ChaosCon"的活动,活动测试目标是将美国西岸数据中心的所有线上服务器进行 Chaos Monkey 测试。有 40 个工程师参与了在线的抢修恢复,花了 4 个小时,全部修复了问题。
随后 Netflix 又举办了第二次"ChaosCon"活动,这次只有 20 个工程师,花了 2 个小时解决了全部问题。到了今天,所有修复的方案都变成了脚本,自动化的修复线上的故障。
破坏性测试不仅仅能够测出系统处理故障的能力,而且能够度量团队是否有足够多的人了解整个系统,当问题发生了,是否能够快速找到正确的人解决问题。

从上图可以看到"ChaosCon"测试的实时流量监控。左上角是美国西岸的数据中心,当该中心服务大面积停掉之后,Netflix 会监控到服务的故障区,开始隔离故障区域,通过 DNS 服务迁移用户访问流量到东岸数据中心,直到西岸的服务恢复。
"ChaosCon"测试会影响到用户体验,Netflix 每个月会做一次 Region 级别的测试。如果你的目标是真正的高可用,那么你也需要做类似的实践,从这些事故中总结经验教训。
06容器化
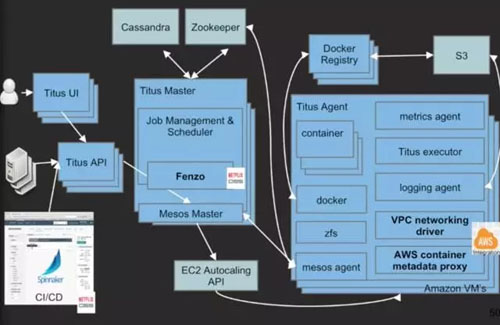
容器化可以大大提高开发者的体验,增加开发者的满意度。在 Netflix 实现容器化的时候,社区还没有成熟的容器管理的平台,所以他们自己开发了一套容器管理平台,在这个平台的研发过程中,也孵化出了大量的开源项目。
幸运的是,目前容器化管理平台已经有了很多的方案,例如谷歌的 Kubernetes,Apache 的 Mesos,Rancher,Docker 公司的 Swarm 等等,可以去评估,使用,不用去重复造轮子。
Netflix 通过深刻的转型,从传统架构的 Java 应用转型成为最超前的微服务架构,并且通过破坏性测试验证了微服务在线上环境的高可用性,为高并发请求提供了强大的支撑。
同时,内部团队的开发模式也得到了改进,基础工具链团队提供工具支撑,解决所有开发团队的通用问题;业务团队只需关注业务功能的实现和创新,这样做不仅提升了客户满意度,也大大提高了开发者的满意度。

