
一. 问题&分析
在读多写少的互联网业务场景,往往“读”性能会成为第一个瓶颈。
随着业务的发展,数据库负载越来越高,逐渐成为系统的瓶颈。面对“读”性能瓶颈,大致有以下几种解题思路:
- 提升 DB 配置从而获取更高的性能。使用更 NX 的机器,升级 DB 的 CPU、内存、磁盘等;
- 使用更多的 DB 来分担读压力。对 DB 进行“拆分”,一个 DB 实例负责数据写入,一组 DB 实例负责数据查询,也就是常说的读写分离;
- 将 读 压力转移到其他存储引擎。比如引入读性能更高的 Cache,让 Cache 挡在 DB 前面,降低落到 DB 上的请求量;
上面三种方案各具千秋,但性价比最高的仍旧是“读写分离方案”:
- 方案一,升级硬件资源,简单粗暴,主要是金钱上的考量;另外,硬件是存在天花板的,金钱不能解决一切问题;
- 方案三,缓存是提升读性能的一大杀器,追求性能的同时需要做很多事,比如调整逻辑代码、进行一致性保障、增加运维成本等,同时也为系统引入更多的复杂性。落地效果非常不错。但有时,杀鸡焉用牛刀?
- 方案二,中规中矩介于两者之间,无需过量的金钱投入,也无需过早的引入太多复杂性
二. 读写分离
以数据库部署架构为基础,对数据操作进行分离,主节点主要处理写请求,从节点主要处理读请求。
通过引入多个副本来分散读请求,从而实现 读请求 的水平扩展。主副本 与 从副本 间的数据一致就是通过 “复制” 来完成。
读写分离架构有几个非常重要的概念:
- 主副本。也称主节点,可以接受 读&写请求;
- 从副本。也称从节点,只能处理 读请求;
- 复制。主副本 与 从副本 间 基于“复制”技术实现数据同步;
- 路由。基于路由规则将请求分发至整个集群(主副本 + 从副本)
以最常见的MySQL主从架构为例:
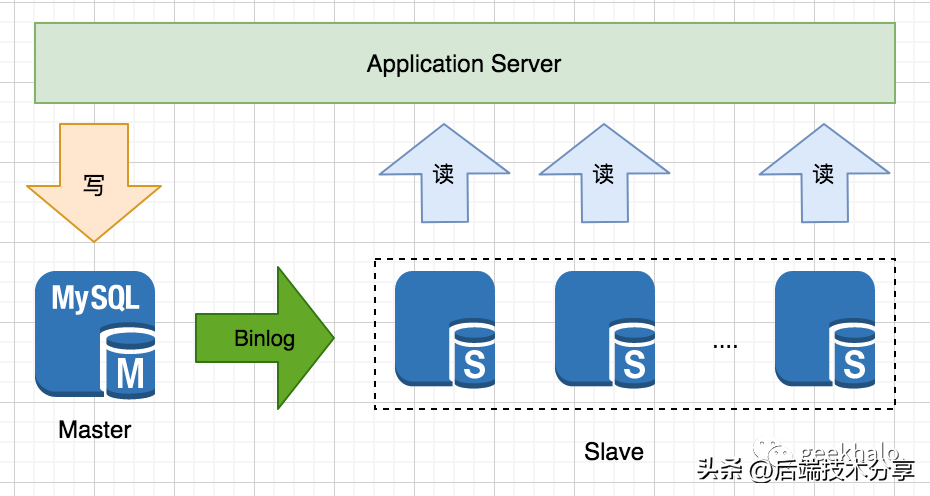
通过扩展 Slave 可以实现 读请求 的水平扩展,核心流程如下:
- 应用将写请求路由到 Master 节点;
- Master 节点完成写入后(事务提交),将变更写入到 Binlog;
- Slave 节点从 Master 节点获取 Binlog,并执行变更(涉及中继日志和并发复制),保持与 Master 数据一致;
- 应用将读请求路由到 Slave 节点,从 Slave 中获取数据;
备注:Slave 过多会加重 Master 的压力,可通过多级复制或分区进行解决。
读写分离架构可以方便的对读请求进行扩展,看似美好,但需要解决两个问题:
- 数据同步。如何保障主从副本间的数据一致性,通常情况下由存储引擎的“复制”机制来保障;
- 请求路由。何时操作主副本,何时操作从副本,如何在多个副本间做负载均衡?
1、复制模式
复制模式主要解决数据同步问题。通常比想象中的复杂,在此只对 单主复制 进行介绍,对于多主复制,由于过于复杂,并不在讨论范围。
(1)同步复制
同步复制架构如图所示:
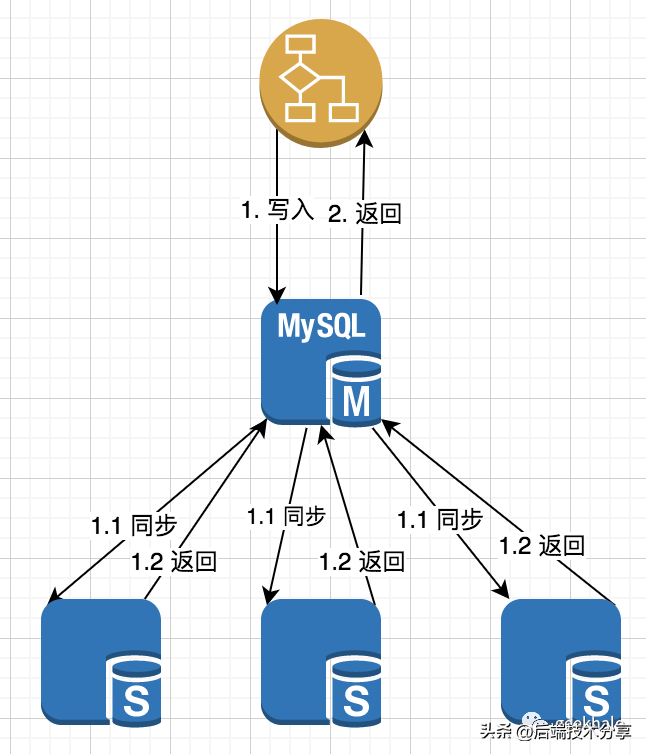
核心流程:
- 主节点处理完请求后,将复制信息同步到所有节点;
- 待所有节点返回后,再向用户返回最终结果;
特点:
- 优点
- 强一致性保障,应用写入成功后,从节点与主节点间就达成了一致,不存在数据延时问题
- 缺点
- 影响写入性能。写性能 = Master + Max(Slave)
- 影响可用性。某个 Slave 异常,直接影响写入,导致写入流程被中断
常见应用场景:
- 在实际开发中,该方案很少使用,特别是在 CAP 最终一致性思想的影响下
- TiDB 等 NewSQL 内部通过一致性协议保障 强一致,基于 NRW 理论保障可用性,这块非常复杂,不在讨论范围
(2)异步复制
异步复制架构如下:
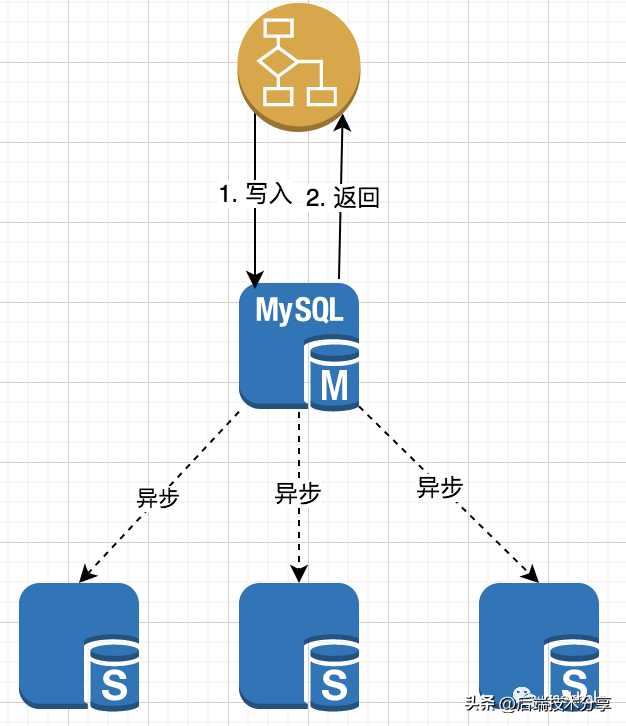
核心流程:
- 主节点处理完请求后,直接返回处理结果;
- 从节点通过异步方式从主节点获取信息;
特点
- 优点:写入性能好
- 缺点:存在数据丢失风险
应用场景
- 数据安全性要求低,性能要求高的场景,如 日志记录 等
- 极端情况下的“饮鸩止渴”,如 秒杀、大促场景
(3)半同步复制
半同步复制是同步复制和异步复制的结合体,架构如下:
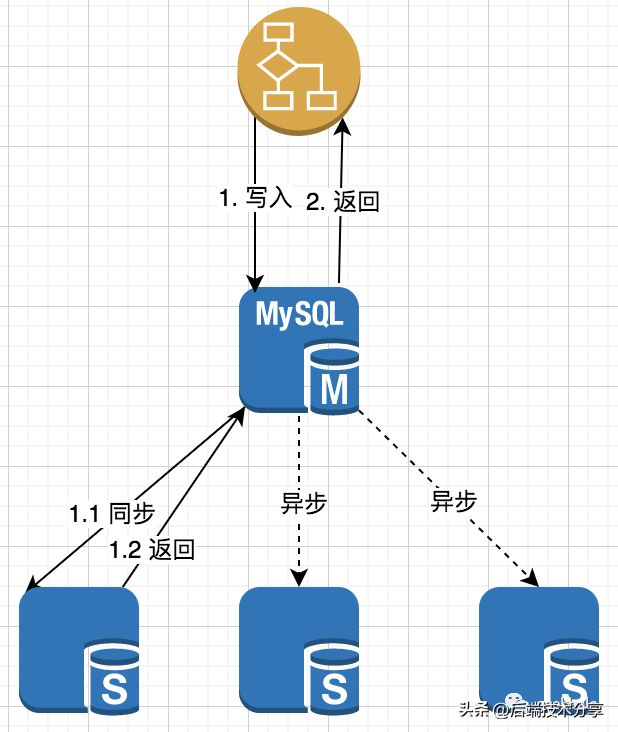
核心流程
- 主节点处理完请求后,对部分节点进行同步复制,等待其复制完成后,在向应用返回最终的处理结果;
- 其他剩余节点进行异步复制
特点
- 在性能和一致性间做平衡
应用场景
- 满足大多数业务场景。
2、路由模式
路由模式,主要决定请求如何分发到众多的数据库节点。
(1)应用路由
在应用层使用代码对请求进行分发,整体架构如下:
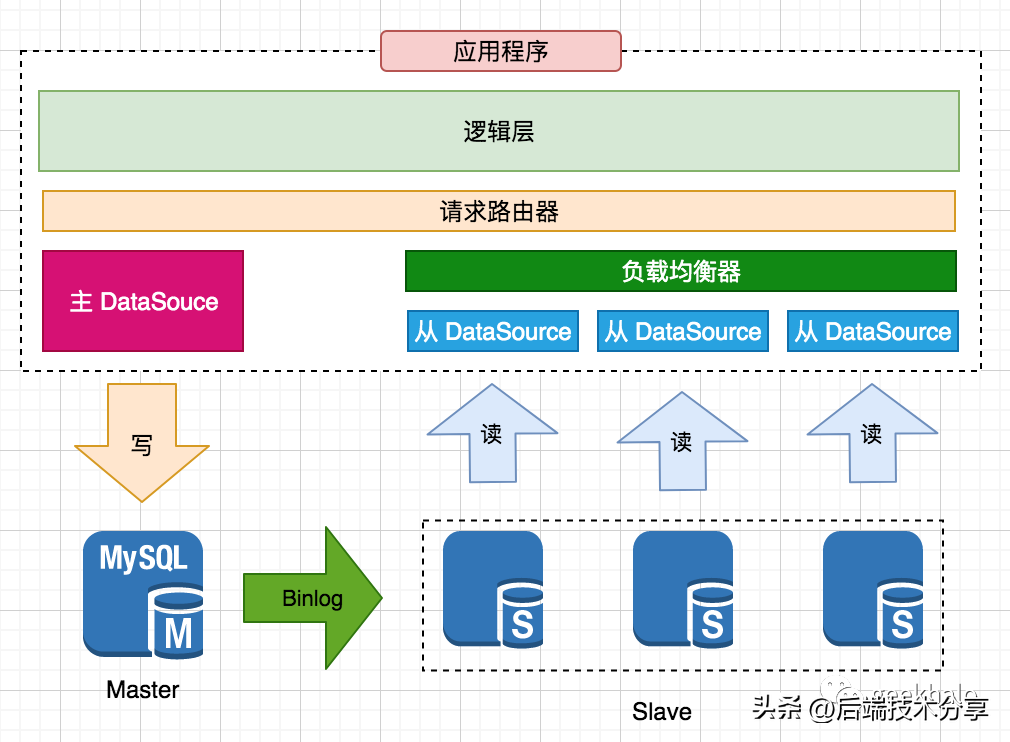
核心流程:
- 为每个数据库节点构建一个DataSource,结合 ORM 框架,构建不同的 DAO
- 应用代码根据业务场景,调用不同的 DAO 实现,完成读写操作
- 多个从节点 DataSource 可以封装为 一个聚合 DAO,内嵌负载均衡算法,在不同的 从库 间进行路由
特点:
- 优点:简单,使用编码实现,掌控力最强
- 缺点:对系统存在极大的侵入性,需要修改大量的逻辑代码
场景:
- 存在于老的项目或需要极致掌控力的场景
(2)智能数据源
将多个 DataSource 封装为一个具有路由功能的 SmartDataSource,整体架构如下:
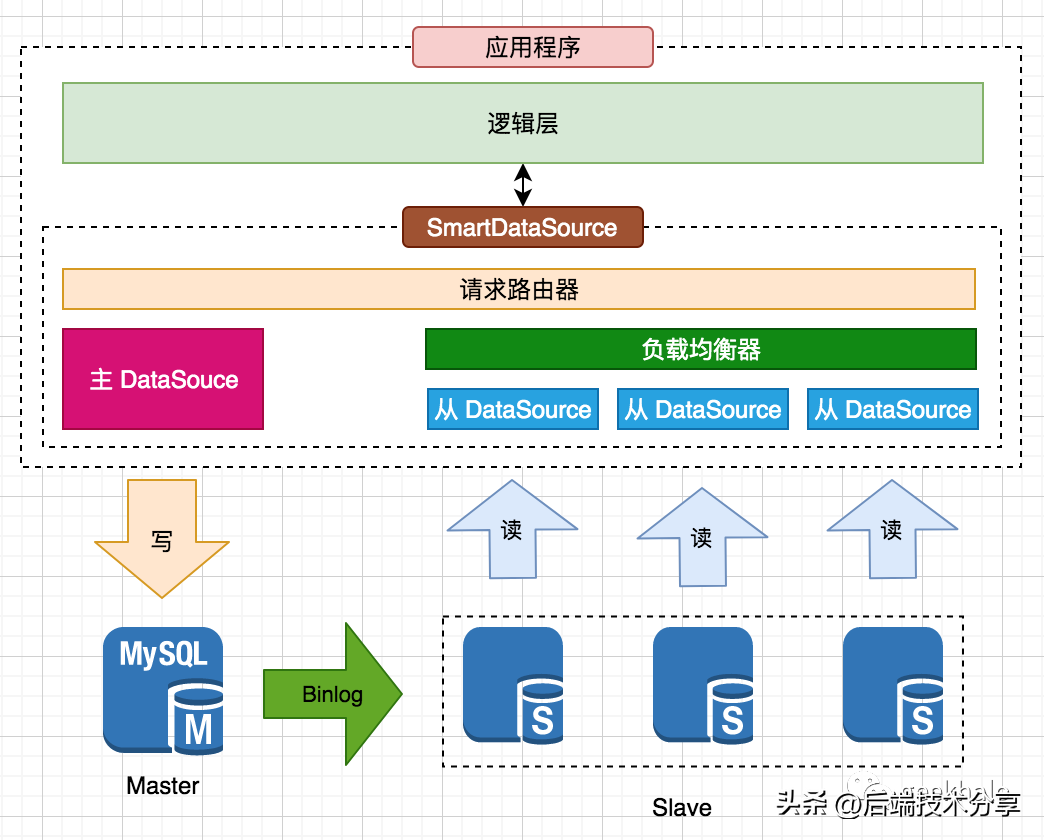
核心设计如下:
- 每一个数据节点对应一个 DataSource
- 将多个 DataSource 封装为一个 SmartDataSource
- SmartDataSource 自动解析 SQL,根据 SQL 类型自动完成请求路由
- 应用程序仅于 SmartDataSource 进行通信
特点:
- 优点:对程序没有侵入性,无需调整代码,只需替换底层 DataSource 即可
- 缺点:集群情况下,需要配置中心进行统一协调
场景:
- 特别使用于高性能场景
(3)Proxy 路由
将 SmartDataSource 核心功能抽取到单独的服务,整体架构如下:
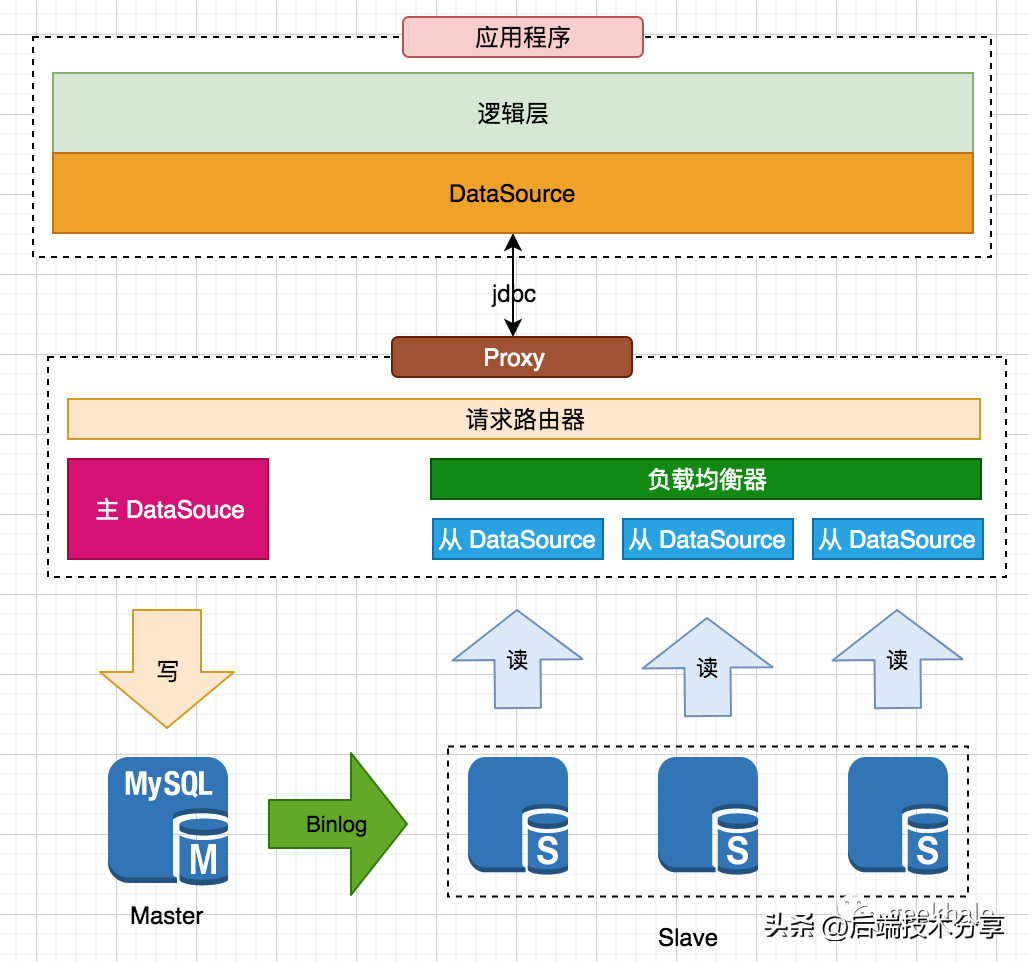
核心设计:
- 将 SmartDataSource 的职能抽取到单独的服务
- 向下管理多个数据库节点
- 向上暴露标准的 jdbc 接口,供应用程序使用
特点:
- 优点。便于管理,所有的管理动作全部收口到 Proxy 层;
- 缺点。增加一层网络开销,对性能有一定的影响;
场景:
- 使用于管理场景
通常情况下,会在配置中心的基础上,综合使用智能路由和Proxy路由两种模式:
智能路由。用于应用程序,追求极致的性能;
Proxy路由。用于数据库管理,追求管理的便利性;
配置中心。为智能路由和Proxy路由提供统一的配置信息。
三、延时挑战
应用程序集成读写分离后,最主要的挑战便是:复制延时。所以,在系统设计时,需要对特定场景进行特殊处理。
1、更新场景,强制切主
对于更新场景,为了避免 主从延时导致的 写覆盖问题,通常使用强制切主策略。
写覆盖的根源,见下图:
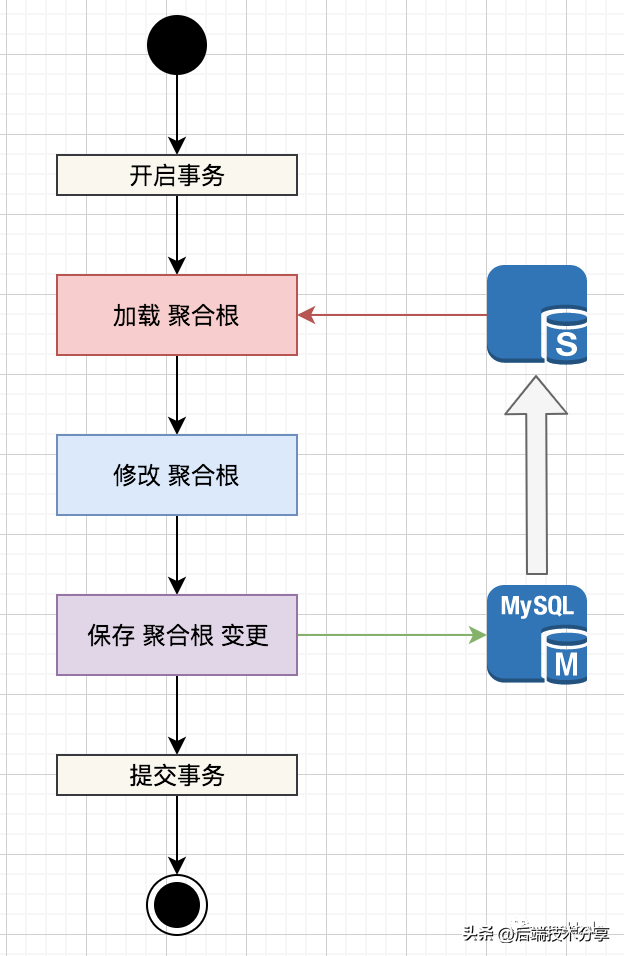
由于存在主从延时,所加载的 聚合根 不一定是最新的数据,因此,后续的修改 和 保存,都是在过期数据上执行,导致写丢失。
备注:乐观锁保护下,不会出现写丢失情况;
面对这种场景,最简单的策略便是:强制切主。具体流程如下:
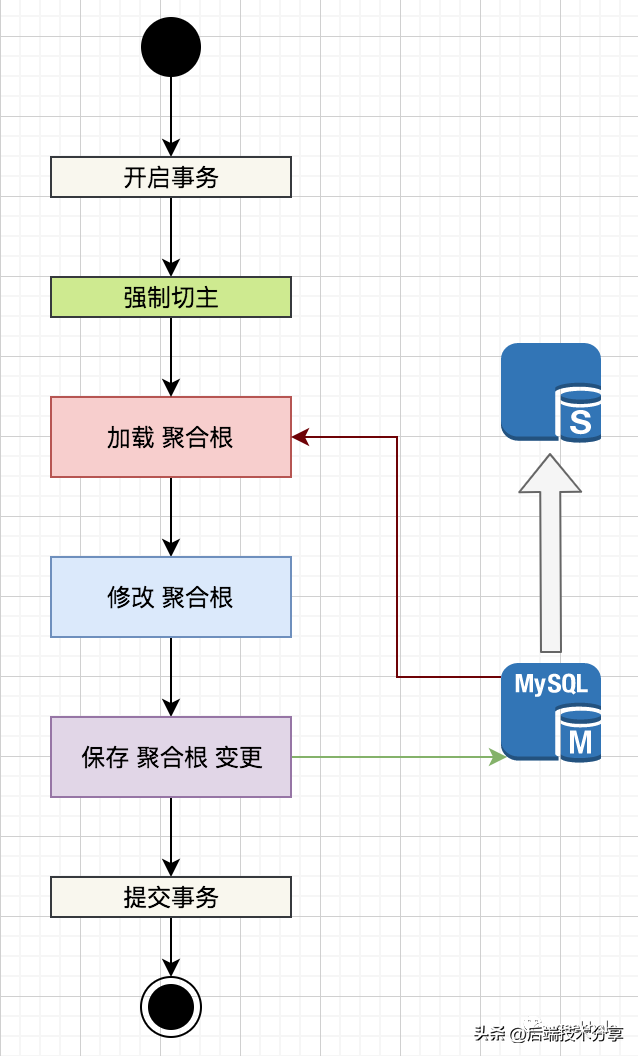
直接从 Mater 进行加载,避免 Slave 查询到过期数据。
SmartDataSource 和 Proxy 都提供了强制切主的设置方式,在此不做过多介绍。
2、根据 version 进行智能路由
如果下游能拿到最新版本的 version,便可以根据 version 智能的获取数据。
以领域事件场景为例,问题描述如下:
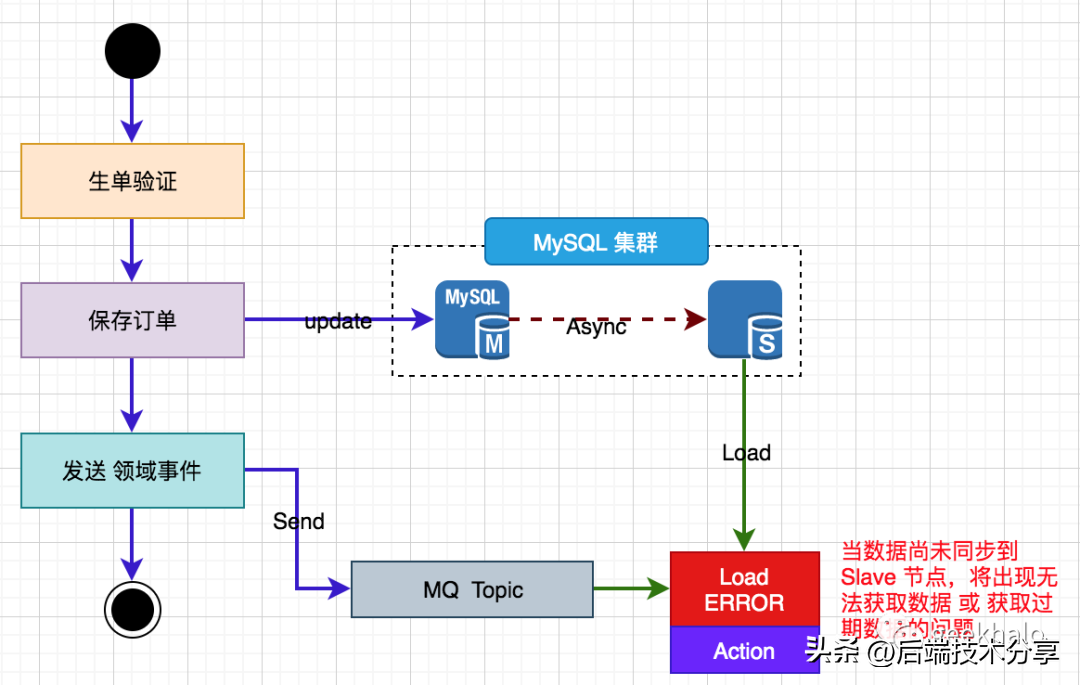
核心流程如下:
- 业务完成后,将变更更新至 DB,Master 更新完成后,直接返回处理结果;
- Slave 启动异步同步,但完成时间不可控;
- 业务发送 领域事件 至 Topic;
- 下游业务监听消息后,从 Slave 查询数据,如果Slave 尚未同步完成,则出现获取不到或获取过期数据的问题
针对这个场景,可以引入 version 进行数据验证,基于 Version 的流程如下:

核心流程如下:
- 业务完成后,将业务变更和version变更更新至 DB,Master 更新完成后,直接返回处理结果;
- Slave 启动异步同步,但完成时间不可控;
- 领域事件包含当前的最新 version,将其发送至 Topic;
- 下游业务监听消息后,先从 Slave 获取数据,并比对两者的 version
- 如果大于等于 msg 中的 version,则直接使用;
- 否则 从 Master 中进行加载,然后执行业务逻辑
备注:步骤4 中 version 管理应该封装在服务接口,对外提供统一的带 version 参数的接口;
时间戳是一种特殊的version,可以使用数据表的 update_time 作为 version。
3、读己之写
读己之写,简单说就是:保存完数据后,理解读取数据。
由于复制延时的存在,通常无法立即读取刚写入的数据,问题流程如下:
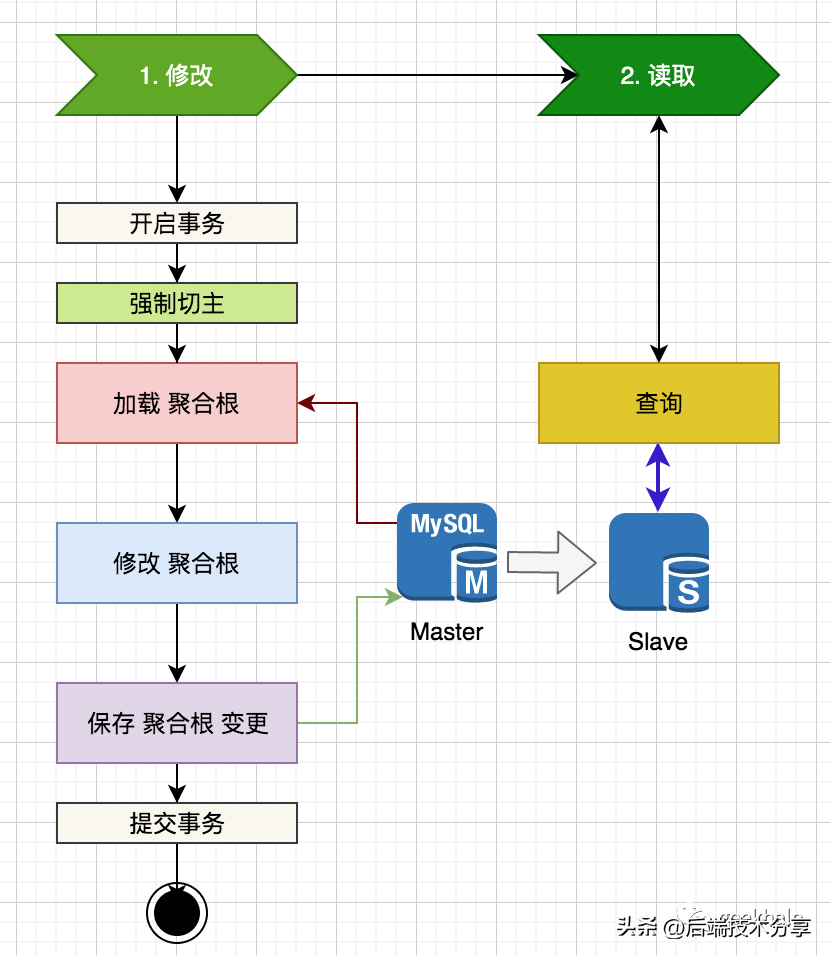
核心流程:
- 业务基于 Master 完成操作直接返回,异步并将变更复制到从节点
- UI跳转至下一个页面,该页面会读取最新数据(详情页、列表页)
- 由于存在主从复制延时,可能无法获取最新数据
(1)主动延时
最简单的解法便是,在完成数据更新操作后,UI 主动sleep几秒,然后在进行下一步操作。

整体流程如下:
- 在跳转新页面前,增加 loading 页,主动等待主从完成同步
- 在系统压力大时,仍旧无法从根源上解决该问题
- 由于其简单性,在项目中也大量使用
(2)UI 动态添加
主动等待对用户存在一定的伤害,可以使用动态添加方案提升用户体验。
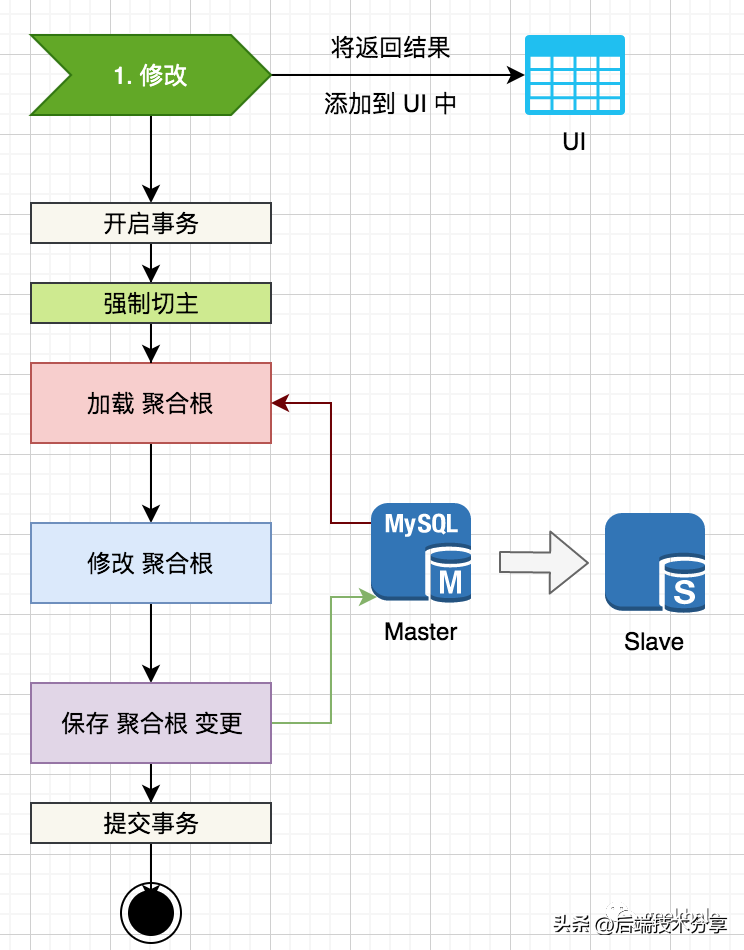
核心点包括:
- 更新请求处理完成后,直接返回最新的数据,包括新增数据或修改后的数据;
- 前端获取数据后,直接在 UI 上进行操作,如将其 append 到 Table 中 或 直接渲染 详情页;
(3)智能切主
UI主动添加只是一种障眼法,用户刷新页面,仍旧可能看不到最新数据,可以试试强制切主
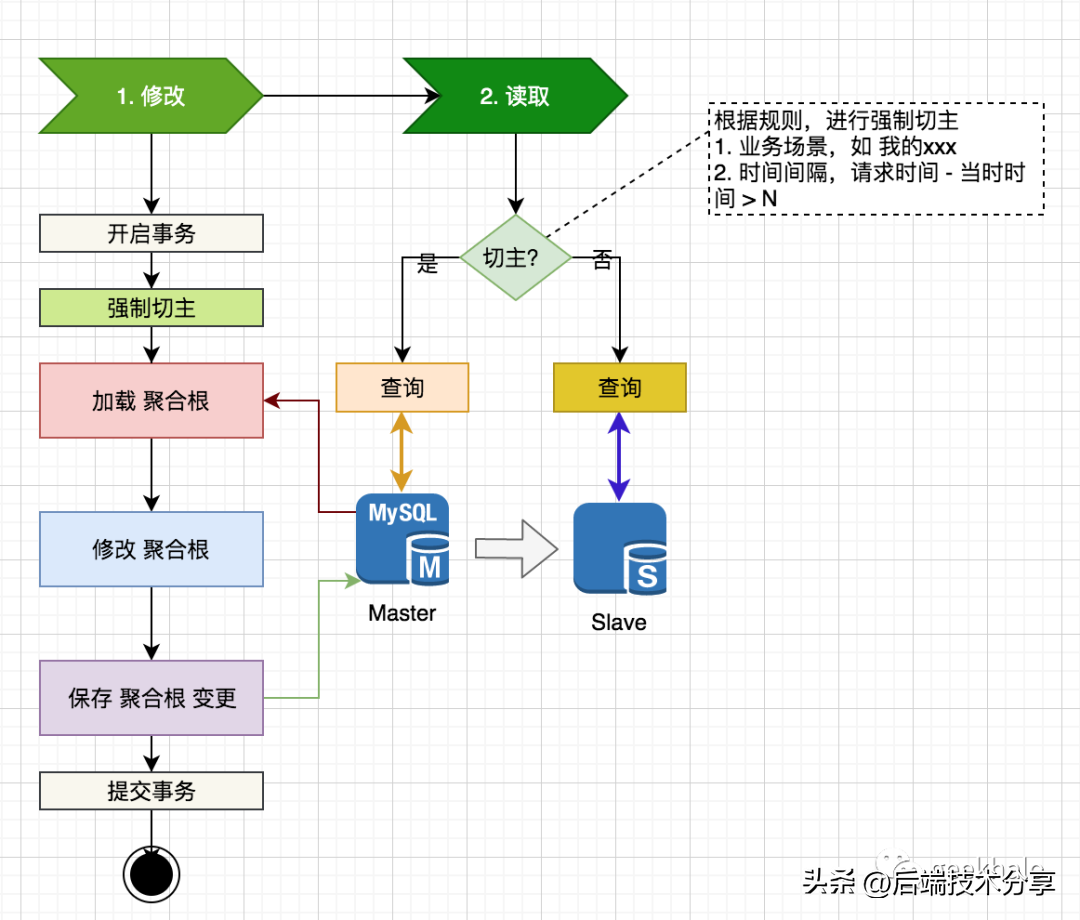
根据规则,决定是否强制切主,如下:
- 根据业务场景,“我的 xxx” 强制切主,其他请求 默认走 Slave
- 时间间隔,请求时携带时间戳或版本,对请求进行切主判断
四、小结
简单回顾,本文概要介绍了“读写分离”的方方面面,主要设计
- 读写分离是提升系统读性能的重要手段
- 落地读写分离,需要解决复制 和 路由 技术问题
- 由于复制延时的存在,对特殊的业务场景进行治理

