几乎所有用于最终用户的Web服务都需要存储数据。它们几乎所有所有人都将它们存储在数据库中。很多很多使用PostgreSQL,MySQL / MariaDB或MSSQL等关系数据库。数据库系统非常令人敬畏,因为您可以忘记它们。他们只是为了处理你的数据持久性……直到他们变慢。
在本文中,您将学习垂直和水平分区,分片,复制等的区别,以及加快数据库的其他方式。我们走吧!

我们关心什么?
对于数据库系统,我们关心一致的一致性和可用性。我们还需要一个用于交换破损设备和连续备份的工作解决方案。
一旦满足最低要求,我们可能有几个性能指标:
- 读取简单查询的性能
- 读取复杂查询的性能
- 插入/更新性能
不同应用程序的工作量以重要方式不同。许多Web应用程序仅使用CRUD,偶尔一次,非常简单的连接。他们需要快速读取和相对快速的写入。他们有大量的小交易。他们有一个OLTP风格的工作量。
分析团队相比之下需要更复杂的疑问。如果这些查询需要更多时间,它也是可以接受的。它们具有少量复杂的选择查询。他们有一个OLAP风格的工作量。
找到单个慢查询的一个工具正在记录慢查询(MySQL,PostgreSQL,MSSQL)。
算法改进
在许多情况下,在生产中运行的代码只是恰好工作的第一件事。对于非开发人员来说,想想你写的最后几块电子邮件。很可能,至少有一个在哪里你没有花太多时间来改善你的沟通方式。这是一个代码的故事。在好公司中,至少第二个人在代码中快速浏览。但是,当它看起来合理时,我们的开发人员不会详细介绍每一条线。这意味着总会有改进的空间。
对于数据库,有两种常见的方法可以改进:添加合理的索引和查询优化。
1. 索引
索引允许数据库通过维护有效的搜索数据结构(例如,B树)更快地查找相关行。这是按表完成的。添加索引可以计算地昂贵,必须在生产系统上执行,因此通常不经常完成。
通过SQL创建索引(MySQL,PostgreSQL)很容易:
- CREATE INDEX arbitrary_index_name
- ON your_table_name(column1, column2);
添加索引可以加速数据库中的搜索,但慢下来更新/插入/删除语句,除非“在”部分“部分成本耗时。
2. 查询优化
查询优化由每个查询的数据库用户完成。查询可以用几种不同的方式编写,其中一些可以比其他方式更有效。您可能希望在数据上尝试不同的查询版本并使用Explate语句。
一个提及的工具是sqlcheck。它检查常见的SQL查询反模式,例如在一列中具有多个值而不是使用交叉表或通配符选择。
查询优化主题的略微不同的子类别是n + 1问题/写入循环以发送多个查询,而不是对数据进行一个查询。
3. 业务变更和分区
当您正在营业时,您想取悦您的客户。如果他们要求一个小型功能,您会尝试包含它。这可能导致功能蠕变。UNIX哲学表明这是一个很多问题的问题:
| 做一件事并做得好。” - Doug McIlroy. |
同样,可以通过用户组拆分Web服务数据。也许将它们分成区域是有意义的?我在AWS和安全的代码战士上看到过。也许你可以将其分成“私人客户”,“小型企业客户”或“大型商业客户”?也许应用程序的一部分实际上可以与自己的数据库有自己的服务?
4. 复制
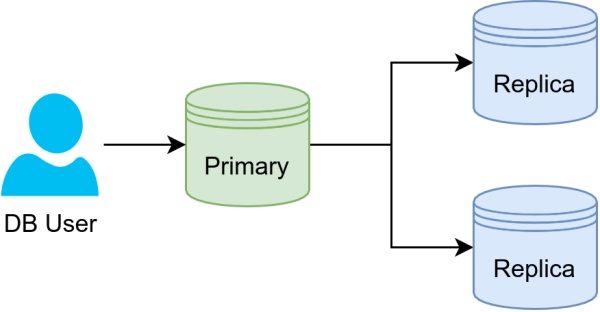
> Image by Martin Thoma
如果读是问题,复制是一个简单的解决方案,如果更新的一点时间延迟并不大。复制将数据库连续复制到另一台计算机。它加速了读取并充当故障转移机制。
该想法是拥有一个主服务器和多个复制服务器,该服务器以前在其他名称下已知。主服务器处理数据的任何更改,而Replication Server只会复制主服务器。还有其他拓扑,例如环或星形设置。
另请参阅:MySQL文档,PostgreSQL文档,MSSQL文档
5. 水平分区
鉴于一个巨大的表,我们可以在另一台机器上存储一些行和其他机器。按行拆分数据的想法称为水平分区。
图像解释了多个单词:
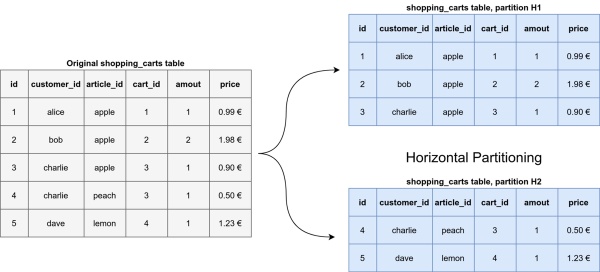
> Conceptual example for horizontal partitioning. Image by Martin Thoma.
仅在MySQL / MariaDB中的ID简单地分区:
- ALTER TABLE shopping_carts
- PARTITION BY RANGE(id)
- ( Partition p0 VALUES LESS THAN (1234),
- Partition p1 VALUES LESS THAN (4567),
- Partition p2 VALUES LESS THAN MAXVALUE);
您希望数据库系统的用户仍然能够使用典型查询查询数据库,或许使用以下内容:
- SELECT * FROM shopping_carts WHERE cart_id = 3
这里有一个重要的事情:水平分区完全无关与水平缩放!
6. 垂直分区
我们可以根据行划分大数据库,而是可以按列划分。这可能会给你一种不安的感觉,因为你在大学学习了一个正常化数据库是一个好主意。这里要注意的重要事项是我们正在谈论数据库设计中的不同阶段。各种数据库正常形式与逻辑设计有关。在这个阶段,我们照顾了物理设计。
应用程序的不同部分可能不需要行的大多数列。出于这个原因,可以将它们分开。因此,垂直分区也称为行分离。
一个常用的实践是从内容中拆分元数据。这是一个图片:
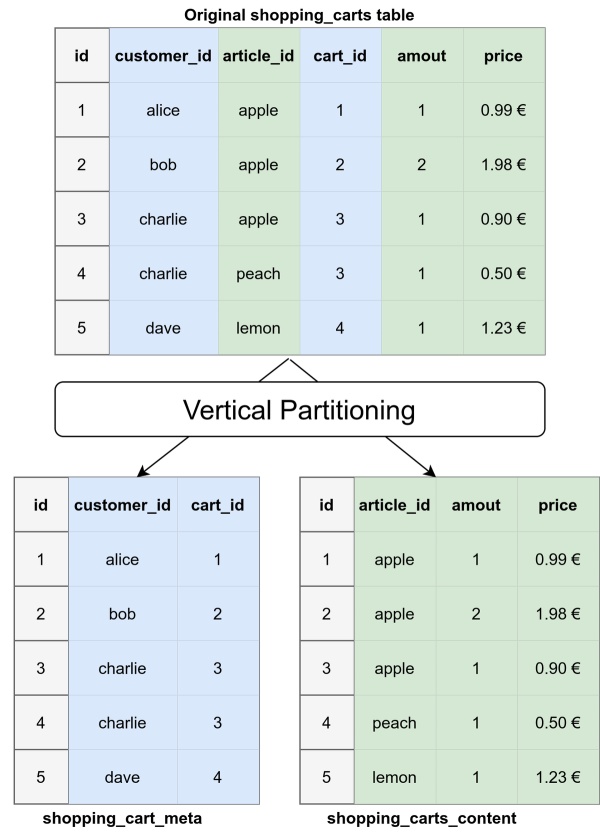
> Image by Martin Thoma
这里有一个重要的事情:垂直分区与垂直缩放完全无关!
当您避免隐私或监管问题时,垂直分区可能很有用。想想信用卡信息。这可以符合其他信息符合良好,但大多数应用程序都不需要它。您甚至可能将其放在完全不同的数据库中,并将其隐藏在私人微服务后面。
分片 - 以下一级分配
您已经看到数据可以以两种不同的方式分组。它可能已经有意义地分区同一台计算机以帮助数据库更快地执行常见查询。但如果数据库最大限度地熄灭CPU或RAM,则使用不同的机器可能有意义。
分片正在划分单个逻辑数据集并将其分发在不同的机器上。
正如您可能猜到的那样,这有很多问题 - 因此应该只应该是你最后的出路。例如,由于2010年10月(来源)的分配问题,FourSquare已下降了11小时。到目前为止,我一直很幸运,我不必处理分片。
第一个明显的问题是您的应用程序需要知道哪些碎片包含您正在寻找的数据。因此,您的应用程序逻辑受到影响,可能在所有地方受到影响。
第二个大问题是横跨碎片加入。
第三个问题是如何定义分片。要真正可扩展,您想要进行动态定义分片。拥有分层结构可以帮助实现这一目标。
8. 数据库群集
在看Vitess时,我只会遇到这个术语。这个想法似乎隐藏了碎片的问题,也是在引擎盖下使用复制:
WintgreSQL还有文档,MySQL群集是另一种产品。
奖金:查询缓存
如果您有一些沉重的查询,该查询是对很少发生更改的数据,您可以尝试缓存查询。我不确定默认情况下的数据库提供了什么,但您可以简单地将键值存储置于该查询的位置。您可以直接向数据库发送查询,而不是将查询发送到在键值存储中查找它的微服务。如果它不存在或无效,则会查询真实数据库。
缺点是您不知道您获得的数据是否是最近的数据。
让我们总结一下!

下一步是什么?
一些主题对于发展至关重要,但不是日常工作或计算机科学课程的一部分。在我们专业的软件开发系列中,您可以了解更多主题。
原文链接:https://betterprogramming.pub/8-techniques-to-speed-up-your-database-292754ff7739

