当我们已经进入2022年,我们可以清楚地看到软件工程的最佳实践已经开始注入数据:数据质量监控和可观察性、不同ETL层的专业化、数据探索和数据安全都在2021年蓬勃发展,并将继续下去,因为从早期创业公司到价值数十亿美元的财富500强企业的数据驱动型公司继续将数据存储和处理到数据库、云数据仓库、数据湖和数据湖仓。
下面你会发现我们预测的5个数据趋势将在2022年确立或加速。
1.分析工程师的崛起将加速
如果说2020年和2021年是关于数据工程师的崛起(根据Dice的科技工作报告,这是最重要的)。 fastest-growing job in tech in 2020),那么在2022年,分析工程师将明确进入人们的视线。
云数据平台的崛起已经改变了一切。传统的技术结构,如立方体和单体数据仓库,正在让位于更灵活和可扩展的数据模型。此外,转换可以在云平台内对所有数据进行。ETL在很大程度上已经被ELT所取代。控制这种转换逻辑的是谁?分析工程师。
这个角色的兴起可以直接归功于云数据平台和数据构建工具(dbt)的兴起。Dbt labs是dbt背后的公司,实际上创造了这个角色。dbt社区在2018年开始有五个用户。截至2021年11月,有7300名用户。
分析工程师是自然演化的一个例子,因为数据工程很可能最终成为多个T型工程角色,由开发自助式数据平台而不是开发管道或报告的工程师驱动。
分析工程师首先出现在云端原生者和初创公司,如Spotify和Deliveroo,但最近开始在企业公司如捷蓝航空中获得地位。你可以阅读 here an articleDeliveroo工程团队关于分析工程在其组织中的出现和演变的文章。
我们看到越来越多的现代数据团队将分析工程师加入他们的团队,因为他们正变得越来越以数据为导向,并建立自我服务的数据管道。根据LinkedIn招聘信息的数据,典型的 must-have skills for an analytics engineer包括SQL、dbt、Python和与现代数据栈相关的工具(如Snowflake、Fivetran、Prefect、Astronomer等)。
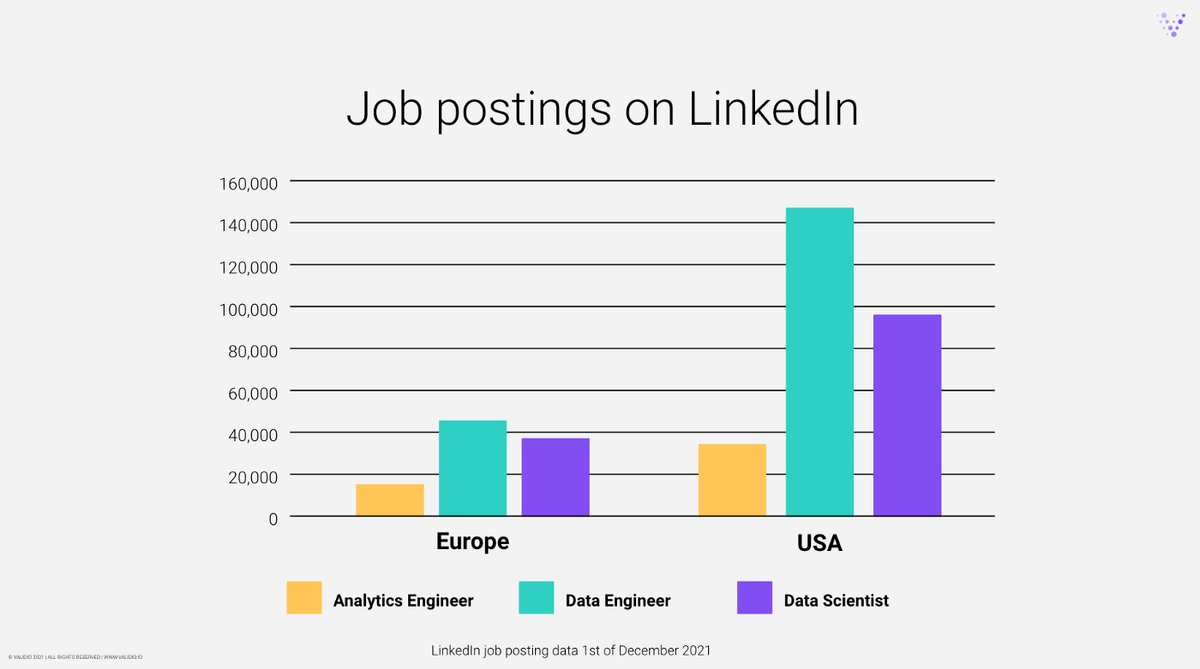
截至2021年12月1日的LinkedIn职位发布数据
根据LinkedIn的数据,对数据科学家的需求大约是分析工程师的2.6到2.7,而且这个差距还在继续缩小。
在2022年,我们预计这一差距将进一步缩小,因为对分析工程师的需求继续增长,接近于对数据科学家(曾被称为 the sexiest job in tech).
2.数据仓库与数据湖库的战争愈演愈烈(界限越来越模糊)。
数据界很少有人错过了2021年底Databricks和Snowflake之间非常公开的对决。这一切开始于Databricks声称其数据湖库技术的TPC-DS基准记录,并说一项研究表明它比Snowflake快2.5倍。Snowflake表示,Databricks缺乏诚信,并表示该研究有缺陷,并有一个 "不确定 "的说法。
我们不必回到那么多年前,当时Snowflake和Databricks是新兴的云计算软件创业公司,他们是如此友好,他们的销售团队经常互相传递客户线索。现在这一切都改变了,因为Snowflake指控Databricks采用不正当的营销手段来赢得关注。这关系到未来几百亿美元的潜在收入。Databricks的首席执行官兼联合创始人Ali Ghodsi在一份声明中指出 ,Snowflake和Databricks如何在许多客户的数据堆中共存。
"我们所看到的是,越来越多的人现在觉得他们可以真正使用他们在数据湖中的数据,与我们一起进行数据仓库工作负载。而这些可能是工作负载,否则会去Snowflake的。"
数据仓库供应商正在逐步从现有的模式转向数据仓库和数据湖模式的融合。同样地,那些在数据湖边开始他们的旅程的供应商现在也在向数据仓库领域扩展。我们可以看到两方面的融合都在发生。
因此,正如Databricks使其数据湖看起来更像数据仓库一样,Snowflake一直在使其数据仓库看起来更像数据湖。简而言之,数据湖仓是一个平台,旨在结合数据仓库和数据湖的优点。根据营销术语,数据湖室结合了数据仓库和数据湖的优点,为数据科学和分析用例提供融合的工作负载。Databricks在其营销资料中利用了这个术语,而Snowflake则更喜欢数据云这个术语。
但是,数据湖仓是否意味着数据仓库的终结?数据湖仓是一个新的、开放的数据管理架构,它将数据湖的灵活性、成本效益和规模与数据仓库的数据管理和ACID交易结合起来,使所有数据的商业智能和ML成为可能。
那是在2012年,专家们在 Strata-Hadoop World声称数据湖将杀死数据仓库(创业公司当时拒绝了SQL并使用了Hadoop--SQL在当时有点逊色,其原因在今天看来是荒谬的)。这种死亡从未发生过。
在2022年,较新的概念与云计算和融合工作负载的技术创新相搭配,是否会废止数据仓库?
时间会证明一切,但这个领域正在升温,我们预计2022年将有更多的公开对决。该领域的其他初创企业,如Firebolt、Dremio和Clickhouse最近都进行了大量融资,将估值推至10亿美元以上。
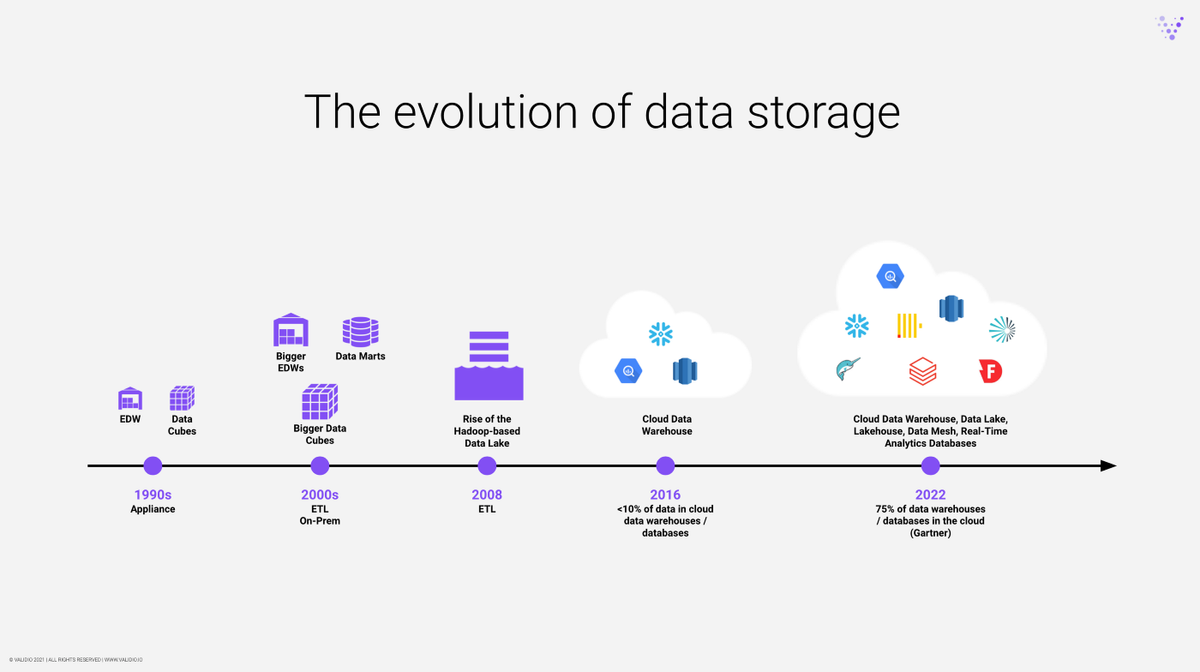
数据存储和仓库的演变
正如阿里-高德西所言,这不会是一个赢家通吃的市场。
"我认为Snowflake将非常成功,我认为Databricks将非常成功......你还会看到其他的顶级公司出现,我肯定,在未来三到四年内。这只是一个巨大的市场,很多人专注于追求它是有道理的。"
根据 Bill Inmon他一直被认为是数据仓库之父,数据湖库提供了一个类似于数据仓库市场早期的机会。数据湖库可以 "将数据湖的数据科学重点与数据仓库的分析能力相结合。"
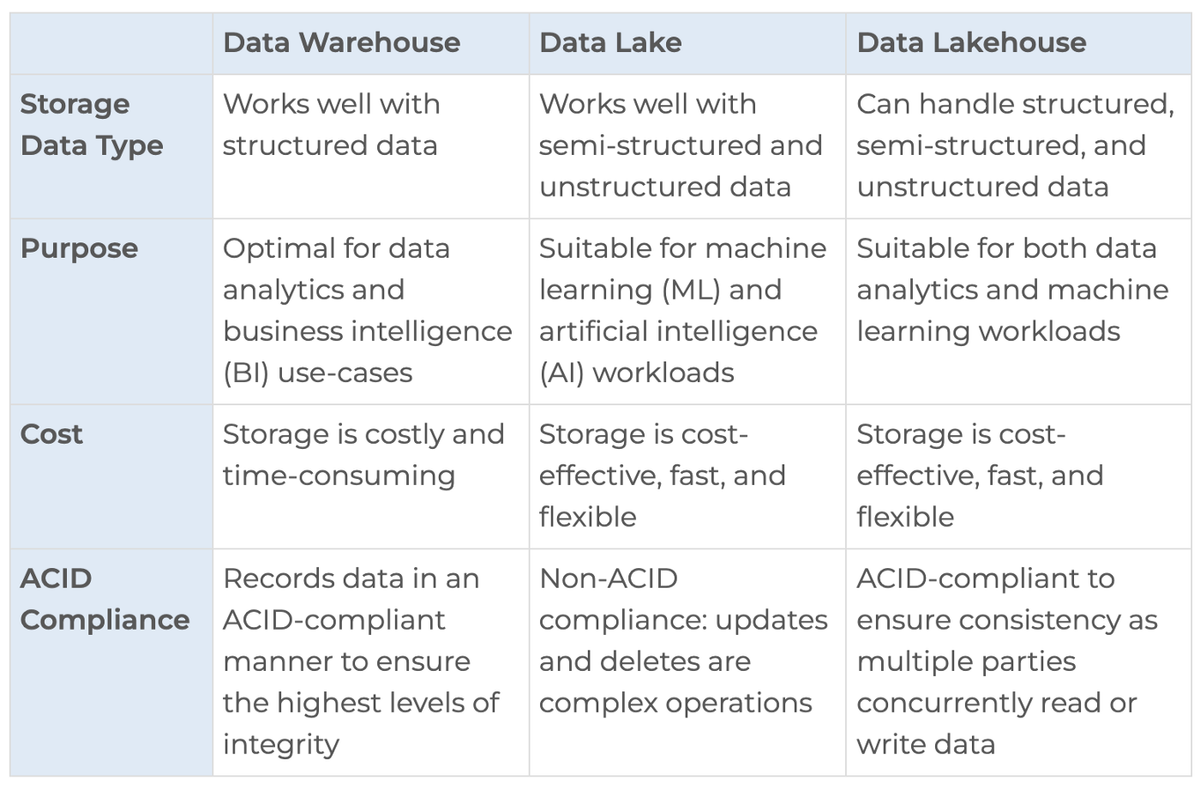
数据仓库VS数据湖VS数据湖馆 by Striim
数据湖仓与数据仓库(与数据湖)仍然是一个正在进行的辩论。数据架构的选择最终自然应取决于团队所处理的数据类型、数据来源以及利益相关者将如何使用这些数据。
随着2022年数据仓库与数据湖仓的争论加剧,重要的是要把炒作和营销术语与现实分开。
3.实时流管道和运营分析将继续推动
正如Matt Turck在他的 MAD Landscape 2021 analysis,感觉实时性一直是一个技术范式,一直是刚要爆发的。当我们进入2022年时,我们听到的权衡似乎还是在成本和复杂性方面。如果一个公司正在建立一个云数据仓库,并且需要立即产生4-6周的影响,那么总体概念似乎仍然是,这是一个实时流管线与批处理管线相比。或者说,如果公司处于数据旅程的开始阶段,那就是纯粹的矫枉过正。
在Validio,我们预计随着实时领域技术的不断成熟和云主机的不断发展,这种观念将在未来几年内发生改变。许多使用案例,如欺诈检测和动态定价,如果不进行实时处理,就很难获得价值。
随着云服务提供商不断改进其流媒体工具,以数据为主导的组织正朝着建立大规模流媒体平台的方向发展。这也是Ali Ghodsi所暗示的一个概念。
"如果你没有一个实时的流处理系统,你必须处理这样的事情,好吧,那么数据每天都会到达。我要把它放在这里。我要把它加到那边去。那么,我如何进行核对?如果有些数据晚了怎么办?我需要连接两个表,但那个表不在这里。所以,也许我会等一下,然后再重新运行一次。" - Ali Ghodsi on a16z
在过去的10年里,Apache Kafka一直是一个坚实的流引擎。进入2022年,我们看到公司越来越多地转向云托管的引擎,如亚马逊的Kinesis和谷歌的Pub/Sub。
僵尸仪表盘是一个非常具体的例子,说明为什么这种流/实时运动正在逐渐发生。在现代数据驱动的公司中,它们似乎成了一个非常真实的东西,Ananath Packkildurai(《数据工程周刊》的创始人)在以下文章中讨论了这个问题 this Twitter thread.
对于许多公司来说,运营分析是开始他们走向实时/近实时分析的一个良好起点。正如Kleiner Perkins的合伙人Bucky Moore在他最近的文章中讨论的那样 blog post:
"云数据仓库的设计是为了支持商业智能用例,这相当于扫描整个表并汇总结果的大型查询。这是对历史数据分析的理想选择,但对于 "现在发生了什么?"这类查询正变得越来越流行,以推动实时决策。这就是运营分析指的是什么。这方面的例子包括应用内的个性化、流失预测、库存预测和欺诈检测。相对于商业智能,运营分析查询将许多不同的数据源连接在一起,需要实时数据摄取和查询性能,并且必须能够同时处理许多查询。"
由于 noted by McKinsey back in 2020,实时数据信息传递和流媒体管道的成本已经大幅下降,为主流使用铺平了道路。麦肯锡在一篇文章中进一步预测 recent article到2025年,数据的生成、处理、分析和终端用户的可视化将被新的和更普遍的技术大大改变,例如用于实时分析的Kappa或lambda架构,导致更快和更强大的洞察力。他们认为,随着云计算成本的不断下降和更多强大的 "内存 "数据工具的上线(如Redis、Memcached),即使是最复杂的高级分析也能合理地提供给所有组织。
不能客观地说,在我们进入2022年后,流数据是否比批处理数据变得更加关键--因为这在不同的公司和用例之间存在巨大的差异。例如,Chris Riccomini设计了一个数据管道进展的层次结构。他认为,数据驱动的组织在他们的管道成熟度中会经历这样的演变序列。

数据管道成熟度的六个阶段 Chris Riccomini
我们不做任何预测,上述管道的成熟度进展是否会变得更加普遍--有人认为实时流管道几乎都是矫枉过正的。
然而,我们看到,越来越多的公司正在投资实时基础设施,因为他们正在从数据驱动(根据历史数据做出决策)变成数据主导(根据实时和历史数据做出决策)。这一趋势的良好指标是Confluent的爆炸性IPO和新产品,如Clickhouse、Materialize和Apache Hudi,它们在数据湖上提供实时功能。
数据的及时性,例如从这种基于批量的周期性架构到更实时的架构,将成为一个越来越重要的竞争要素,因为每一个现代公司都在成为一个数据公司。我们预计这将在2022年进一步加速。
4.现代数据栈采用的云市场的崛起
在数据基础设施领域,PLG(产品主导型增长)趋势已经持续了几年,因为基于使用的定价、开源和软件的可负担性已经将购买决策推向了终端用户。然而,与传统的销售主导的市场模式相比,从商业模式和产品的角度来看,产品主导的增长和基于使用的定价在软件方面的实施和执行可能很复杂。通过AWS、GCP和Azure的云市场平台正在成为企业向未来数字销售发展的最佳第一步。
随着开发者工具公司--包括现代数据栈中的初创公司--部署不同级别的PLG动议(产品的免费/免费/免费试用版)或多或少成为一种规范,我们也在经历云市场的崛起,成为现代数据团队采用新技术渠道的首选。这主要是由于它们所提供的类似于消费者的无摩擦购买体验(想想苹果应用商店或谷歌游戏商店),而且数据团队可以利用他们已经承诺的云供应商的支出,通过云市场采用新技术。
对于全球领先的云计算公司来说,云市场现在是进入市场的必要条件,而不是选择。这些数字--包括已实现的和预测的--说明了原因。
- 超过45%的 Forbes The Cloud 100公司积极使用云市场作为其软件的分销渠道。
- 流经三大云计算供应商的企业承诺支出 exceeds $250 billion per year- 而这个数字正在快速攀升。
- 仅在2021年,独立软件供应商通过云市场平台 产生了超过30亿美元的收入,根据 Bessemer predictions. 贝瑟默公司预计,在未来几年,这一数字将以10的倍数增长。
- Forrester had projected到2023年,全球13万亿美元的B2B支出中有17%将通过电子商务和市场平台流动 - 但这个数字可能在2021年就已经达到了。
- A 2020 Tackle survey发现,70%的软件供应商表示,由于COVID-19的出现,他们已经增加了对市场平台的关注和投资,将其作为进入市场的渠道。
云市场的爆炸性增长主要源于它们为现代数据团队和数据基础设施技术供应商提供的相互优势。

云市场的双赢
最近发表的一项研究 by Gartner预测,到2025年,近80%的销售互动将通过数字渠道进行。通过GCP、AWS或Azure云市场分发技术正成为现代数据团队的自然入口。现代数据栈公司,如 Astronomer and Fivetran已经通过成为云市场的早期采用者而获得了成功。其他早期采用云市场的公司,如CrowdStrike,已经看到销售周期时间减少了近50%。
购买行为已经彻底改变,现代数据团队在他们的商业生活中期待着消费者级别的体验。他们希望以一种非常低调、技术领先的方式来发现、试用、甚至购买新的数据基础设施技术。云市场正在成为这些团队探索新技术的接入点,就像苹果应用商店和谷歌游戏商店成为我们所有人探索新的日常服务和娱乐的接入点。
提供现代数据基础设施工具的初创企业可以从我们的消费者生活中学习到明显的模式和经验,以消除摩擦,更有效地扩大销售,并帮助数据团队更快地获得价值。
我们预计,在2022年,云市场将成为现代数据团队采用现代数据栈技术的首选方式。由于云和新基础设施的爆炸性增长,围绕现代数据栈的概念已经出现了很多,因此,云市场将成为自然的切入点,这让人感觉很合理。
5.围绕现代数据栈和数据质量的术语的统一和一致
看到现代数据栈背景下的数据质量空间从2020年的小众类别到过去18个月内完全爆发,2021年共有2亿美元的资金流入该空间,这是非常不可思议的。甚至G2在他们最近的"What Is Happening in the Data Ecosystem in 2022"的文章中指出,2022年将是数据质量的天下,他们在2021年看到数据质量类别的流量急剧增加,这是一个不寻常的趋势。
在现代云数据基础设施的背景下,数据质量类别的崛起是非常有意义的。数据质量不仅是任何现代数据驱动型公司的基础(无论它是普通的报告、商业智能、运营分析还是高级机器学习),根据 2022 State of Data Engineering Survey数据质量和验证是调查对象(主要是数据工程师)提到的第一大挑战。27%的调查对象不确定他们的组织使用什么(如果有的话)数据质量解决方案。对于DataOps成熟度低的组织,这一数字跃升至39%。
然而,数据质量技术的爆炸性增长也带来了一些负面的影响。随着现代数据质量工具的快速爆炸性增长,我们也可以看到该领域的术语有很多不一致和重叠的用法。正如作者所指出的 Bessemer在数据质量领域的参与者已经创造了一些借用应用性能监控的术语,如 "数据停机"(对 "应用停机 "的戏称)和 "数据可靠性工程"(对 "站点可靠性工程 "的戏称)。
现在有无数种方法来描述重要但有点庞杂的过程,可以被定义为数据质量验证和监测。我们看到诸如数据可观察性、数据可靠性、数据可靠性工程、数据质量监控、数据的Datadog、实时数据质量监控、数据停机、未知数据故障、无声数据故障等术语被交替使用且不一致。
在目前的状态下,现代数据栈中的大多数数据质量工具都集中在监控管道元数据或对仓库中的静态数据进行SQL查询--有些工具与不同层次的数据脉络或根本原因分析相联系。
一个现在被定义为数据可观察性工具的软件可能只关注数据线,或者只关注监测管道元数据。一个提供实时数据质量警报但不支持监测实时流管道的工具,现在可能被定义为一个实时数据质量监测工具。一个只对仓库中的数据进行SQL查询的工具可能被定义为端到端的数据可靠性工具,而一个监控管道元数据的工具可能被定义为数据质量监控工具(反之亦然)。这个名单还在继续。现在有很多不一致的地方,导致市场和终端用户的混乱。
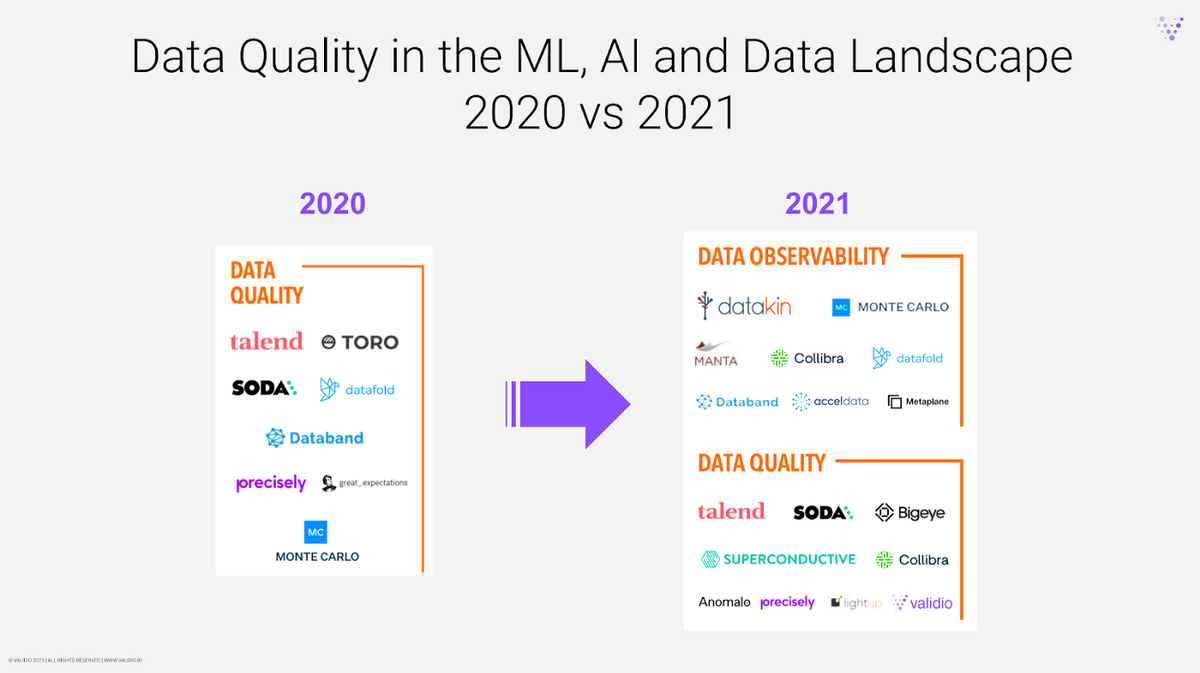
2020年MAD格局中的数据质量类别与2021年的格局相比,由 Matt Turck
术语的不一致性是超出数据质量范畴,扩展到整个现代数据栈的东西。
一个行业的早期最有力的指标之一是新术语的扩散,而这些术语的使用是不一致的。作为一个具体的例子,当有人说电子商务平台或CMS平台时,我们大多数人都会想到例如Shopify或WordPress,并对该工具在业务中的功能有一个清晰的认识。但是,当你听到 "运营分析"、"数据湖 "或 "数据可观察性 "这样的术语时,一个在数据世界工作的人可能会发现很难说清楚它们的确切含义和/或包含的内容。这往往与以下事实直接相关,即许多术语是由一些公司创造的,它们利用特定的技术开辟了新的领域,并进行了分类创造。有趣的是,即使是最热门的数据术语,例如 "现代数据栈",在数据世界中也缺乏一个一致的定义--此外,诸如 "数据网 "和 "数据结构 "等术语也经常被用来描述新的数据架构。
随着实际用户将该技术分层到他们的堆栈并建立用例,该行业将最终帮助形成特定工具和架构模式的定义。
在2022年,随着现代数据栈和数据质量类别的成熟,我们也希望看到术语使用方式的协调和一致。
综上所述
我们相信,我们仍然处于现代数据栈革命的早期阶段。正如云计算改变了我们今天的工作方式一样,通过现代云原生基础设施来驾驭数据,对各种规模和行业的公司来说都是至关重要的。此外,随着现代数据栈被更广泛地采用,我们预计将看到许多需要进一步加强的领域,包括流式数据,使公司能够采取实时行动。
如果说软件一直在吞噬世界,那么数据就是机器的燃料。近十年来,Airbnb、Netflix、Uber和其他大公司都在其数据栈上进行了大量投资,不仅为个性化的内容提供服务,而且还帮助进行动态和自动化决策。随着现代数据栈的兴起,任何公司无论大小都可以以灵活和非成本高昂的方式存储和利用大量的数据,而不需要一支技术人员的军队。
现代云数据基础设施正在进行大规模建设,未来将由数据的可访问性、使用和质量来定义。
我们对2022年所带来的一切感到无比兴奋。

