这篇文章是我近期准备在公司做大数据分享的内容。因为习惯了全英文的 keynote,所以本来标题叫《Introduction to bigdata》,但微信的英文标题字体总觉得有些别扭,所以还是取了这么个中文名。
这篇文章的目的是带那些对大数据不了解又有兴趣的人入门。如果你是老手可以忽略,或者想看看有没有不一样的东西也行。
我们学习一个新知识,第一步应该是给它个明确的定义。这样才能知道你学的是什么,哪些该学,哪些又可以先不用管。
然而,大数据虽然很火,但其实是个概念没那么清晰的东西,不同的人可能有不同的理解。
这次我们不去纠结具体的定义,也忽略那些 4 个 V、6 个 C 之类传统说教的东西,甚至不想聊架构演进以及各种调优的方法,这些东西讲了大家也不一定懂,懂了也记不住,记住了也用不起来。
我们也不去关注 AI、Machine Learning 那些炫酷的应用层面的东西,而是去看看大数据这栋房子的地基是什么模样。限于篇幅,很多技术细节点到即止,有兴趣的同学可以再按需了解,这也正是入门的含义所在。
一
首先第一个问题,大数据,大数据,多大叫大?或者换一个角度,什么时候需要用到大数据相关的技术?
这依然是个没有标准答案的问题,有些人可能觉得几十 G 就够大了,也有人觉得几十 T 也还好。当你不知道多大叫大,或者当你不知道该不该用大数据技术的时候,通常你就还不需要它。
而当你的数据多到单机或者几台机器存不下,即使存得下也不好管理和使用的时候;当你发现用传统的编程方式,哪怕多进程多线程协程全用上,数据处理速度依然很不理想的时候;当你碰到其他由于数据量太大导致的实际问题的时候,可能你需要考虑下是不是该尝试下大数据相关的技术。
二
从刚才的例子很容易能抽象出大数据的两类典型应用场景:
- 大量数据的存储,解决装不下的问题。
- 大量数据的计算,解决算得慢的问题。
因此,大数据的地基也就由存储和计算两部分组成。
三
我们在单机,或者说数据量没那么大的时候,对于存储有两种需求:
- 文件形式的存储
- 数据库形式的存储
文件形式的存储是最基本的需求,比如各个服务产生的日志、爬虫爬来的数据、图片音频等多媒体文件等等。对应的是最原始的数据。
数据库形式的存储则通常是处理之后可以直接供业务程序化使用的数据,比如从访问日志文件里处理得到访问者 ip、ua 等信息保存到关系数据库,这样就能直接由一个 web 程序展示在页面上。对应的是处理后方便使用的数据。
大数据也只是数据量大而已,这两种需求也一样。虽然不一定严谨,但前者我们可以叫做离线(offline)存储,后者可以叫做在线(online)存储。
四
离线存储这块 HDFS(Hadoop Distributed File System) 基本上是事实上的标准。从名字可以看出,这是个分布式的文件系统。实际上,「分布式」也是解决大数据问题的通用方法,只有支持无限横向扩展的分布式系统才能在理论上有解决无限增长的数据量带来的问题的可能性。当然这里的无限要打个引号。
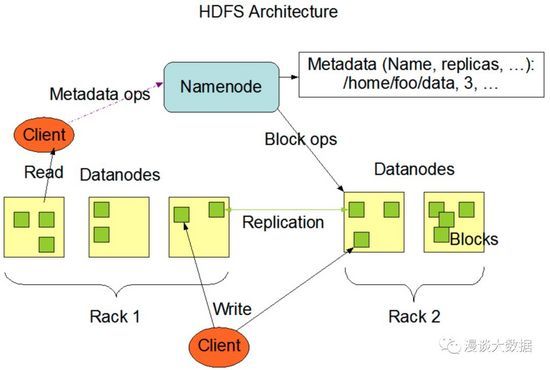
这是 HDFS 的简易架构图,看起来仍然不太直观,其实要点只有几句话:
- 文件被以 block 为单位拆分后存放在不同的服务器上,每个 block 都在不同机器上做了多份冗余。
- 有 NameNode 和 DataNode 两种角色,前者存放元数据也就是每个 block 保存在哪里,后者负责存放实际数据。
- 读和写数据都要先向 NameNode 拿到对应文件的元数据,然后再找对应的 DataNode 拿实际的数据。
可以看到,HDFS 通过集中记录元数据的方式实现了分布式的效果,数据量增长只需要添加一些新的 DataNode 就可以了,单机容量不再是限制。
而为了保证数据的高可用,比如某台服务器突然坏了再也起不来了,HDFS 通过冗余的方式(通常是 3 副本)来解决这个问题。这也是分布式系统里最常用的高可用方式,虽然成本可能很高。
系统级别的高可用才有意义,所以除了数据的高可用,元数据的高可用也至关重要。思路一样 -- 备份。HDFS 提供了 Secondary NameNode 来提供元数据的冗余。当然更好的方式是使用 NameNode HA 的方式,通过 active/standby 一组 NameNode 来保证不间断的元数据读写服务。
同样,扩展性刚才也只考虑到数据的横向扩展,元数据呢?当数据量大到一定程度,元数据也会非常大,类似我们在传统关系数据库里碰到的索引膨胀的问题。解决的思路是 NameNode Federation。简单讲就是把原来的一组 active/standy NameNode 拆分成多组,每组只管理一部分元数据。拆分后以类似我们在 Linux 系统里挂载(mount)硬盘的方法对外作为整体提供服务。这些 NameNode 组之间相互独立,2.x 版本的 HDFS 通过 ViewFS 这个抽象在客户端通过配置的方式实现对多组 NameNode 的透明访问,3.x 版本的 HDFS 则实现了全新的 Router Federation 来在服务端保证对多组 NameNode 的透明访问。
可以看到,元数据的横向扩展和实际数据的横向扩展思路完全一样,都是拆分然后做成分布式。
五
和离线存储对应的是在线存储,可以参照传统的 MySQL、Oracle 等数据库来理解。在大数据领域最常用的是 HBase。
数据分类的标准很多,HBase 可能被归类为 NoSQL 数据库、列式数据库、分布式数据库等等。
说它是 NoSQL 数据库,是因为 HBase 没有提供传统关系型数据库的很多特性。比如不支持通过 SQL 的形式读写数据,虽然可以集成 Apache Phoenix 等第三方方案,但毕竟原生不支持;不支持二级索引(Secondary Index),只有顺序排列的 rowkey 作为主键,虽然通过内置的 Coprocessor 能实现,第三方的 Apache Phoenix 也提供了 SQL 语句创建二级索引的功能,但毕竟原生不支持;Schema 不那么结构化和确定,只提供了列族来对列分类管理,每个列族内的列的数量、类型都没有限制,完全在数据写入时确定,甚至只能通过全表扫描确定一共有哪些列。从这些角度看,HBase 甚至都不像是个 DataBase,而更像是个 DataStore。
说它是列式数据库,是因为底层存储以列族为单位组织。不同行的相同列族放在一起,同一行的不同列族反而不在一起。这也就使得基于列(族)的过滤等变得更加容易。
说它是分布式数据库,是因为它提供了强大的横向扩展的能力。这也是 HBase 能成为大数据在线存储领域主流方案的主要原因。
HBase 能提供超大数据量存储和访问的根本在于,它是基于 HDFS 的,所有的数据都以文件的形式保存在 HDFS 上。这样就天然拥有了横向扩展的能力,以及高可用等特性。
解决了数据存储的问题,剩下就需要在这个基础上提供一套类似数据库的 API 服务,并保证这套 API 服务也是可以很容易横向扩展的。
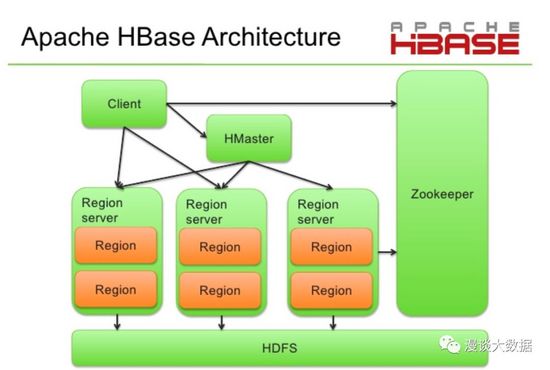
上线这个架构图已经足够简单,我们罗列几个关键点:
- 每个节点上都有一个叫 RegionServer 的程序来提供对数据的读写服务
- 每个表被拆分成很多个 Region,然后均衡地分散在各个 RegionServer 上
另外有个 HMaster 的服务,负责对表的创建、修改、删除已经 Region 相关的各种管理操作。
很容易看出,HBase 的分布式和 HDFS 非常像,RegionServer 类似于 DataNode,HMaster 类似于 NameNode,Region 类似于 Block。
只要在 HDFS 层扩容 DataNode,在 HBase 层扩容 RegionServer,就很容易实现 HBase 的横向扩展,来满足更多数据的读写需求。
细心的人应该发现了,图里没有体现元数据。在 HDFS 里元数据是由 NameNode 掌控的,类似的,HBase 里的元数据由 HMaster 来掌控。HBase 里的元数据保存的是一张表有哪些 Region,又各由哪个 RegionServer 提供服务。
这些元数据,HBase 采用了很巧妙的方法保存 -- 像应用数据那些以 HBase table 的形式保存,这样就能像操作一张普通表一样操作元数据了,实现上无疑简单了很多。
而由于 HBase 的元数据以 Region 为粒度,远远比 HDFS 里的 block 粒度大多了,因此元数据的数据量一般也就不会成为性能瓶颈,也就不太需要再考虑元数据的横向扩展了。
至于高可用,存储层面已经有 HDFS 保障,服务层面只要提供多个 HMaster 做主备就行了。
六
存储的话题聊到这里。下面来看看计算这块。
和存储类似,无论数据大小,我们可以把计算分为两种类型:
- 离线(offline)计算,或者叫批量(batch)计算/处理
- 在线(online)计算,或者叫实时(realtime)计算、流(stream)计算/处理
区分批处理和流处理的另一个角度是处理数据的边界。批处理对应 bounded 数据,数据量的大小有限且确定,而流处理的数据是 unbounded 的,数据量没有边界,程序永远执行下去不会停止。
在大数据领域,批量计算一般用于用于对响应时间和延迟不敏感的场景。有些是业务逻辑本身就不敏感,比如天级别的报表,有些则是由于数据量特别大等原因而被迫牺牲了响应时间和延迟。而相反,流计算则用于对响应时间和延迟敏感的场景,如实时的 PV 计算等。
批量计算的延迟一般较大,在分钟、小时甚至天级。流处理则一般要求在毫秒或秒级完成数据处理。值得一提的是,介于两者之间,还有准实时计算的说法,延迟通常在数秒到数十秒。准实时计算很自然能想到是为了在延迟和处理数据量之间达到一个可以接受的平衡。
七
批量计算在大数据领域最老资历的就是 MapReduce。MapReduce 和前面提到的 HDFS 合在一起就组成了 Hadoop。而 Hadoop 多年来一直是大数据领域事实上的标准基础设施。从这一点也可以看出,我们按存储和计算来对大数据技术做分类也是最基本的一种办法。
MapReduce 作为一个分布式的计算框架(回想下前面说的分布式是解决大数据问题的默认思路),编程模型起源于函数式编程语言里的 map 和 reduce 函数。
得益于 HDFS 已经将数据以 block 为单位切割,MapReduce 框架也就可以很轻松地将数据的初步处理以多个 map 函数的形式分发到不同的服务器上并行执行。map 阶段处理的结果又以同样的思路分布到不同的服务器上并行做第二阶段的 reduce 操作,以得到想要的结果。
以大数据领域的「Hello World」-- 「Word Count」为例,要计算 100 个文件共 10 T 数据里每个单词出现的次数,在 map 阶段可能就会有 100 个 mapper 并行去对自己分配到的数据做分词,然后把同样的单词「shuffle」到同样的 reducer 做聚合求和的操作,这些 reducer 同样也是并行执行,最后独立输出各自的执行结果,合在一起就是最终完整的结果。
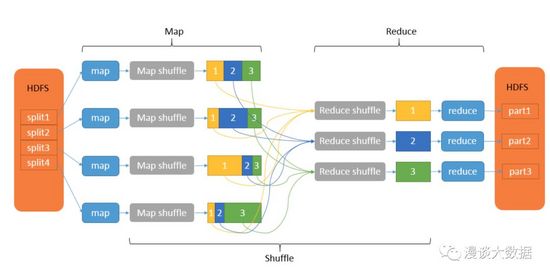
从上图可以看到,shuffle 操作处理 map 阶段的输出以作为 reduce 阶段的输入,是个承上启下的关键过程。这个过程虽然是 MapReduce 框架自动完成的,但由于涉及非常多的 IO 操作,而 IO 往往是数据处理流程中最消耗性能的部分,因此 shuffle 也就成了性能调优的重点。
可以看到,正是采用了分布式计算的思想,利用了多台服务器多核并行处理的方法,才使得我们能以足够快的速度完成对海量数据的处理。
八
MapReduce 框架作为一个分布式计算框架,提供了基础的大数据计算能力。但随着使用场景越来越丰富,也慢慢暴露出一些问题。
资源协调
前面我们讲分布式存储的时候提到了 NameNode 这么一个统一管理的角色,类似的,分布式计算也需要有这么一个统一管理和协调的角色。更具体的说,这个角色需要承担计算资源的协调、计算任务的分配、任务进度和状态的监控、失败任务的重跑等职责。
早期 MapReduce -- 即 MR1 -- 完整地实现了这些功能,居中统一协调的角色叫做 JobTracker,另外每个节点上会有一个 TaskTracker 负责收集本机资源使用情况并汇报给 JobTracker 作为分配资源的依据。
这个架构的主要问题是 JobTracker 的职责太多了,在集群达到一定规模,任务多到一定地步后,很容易成为整个系统的瓶颈。
于是有了重构之后的第二代 MapReduce -- MR2,并给它取了个新名字 YARN(Yet-Another-Resource-Negotiator)。
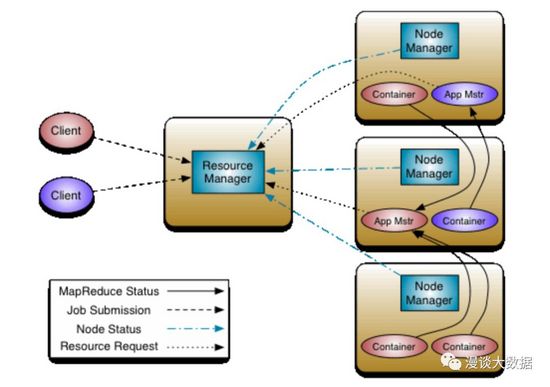
JobTracker 的两个核心功能 -- 资源管理和任务的调度/监控被拆分开,分别由 ResourceManager 和 ApplicationMaster 来承担。ResouerceManager 主要负责分配计算资源(其实还包括初始化和监控 ApplicationMaster),工作变的很简单,不再容易成为瓶颈,部署多个实例后也很容易实现高可用。而 ApplicationMaster 则是每个 App 各分配一个,所有 Job 的资源申请、调度执行、状态监控、重跑等都由它来组织。这样,负担最重的工作分散到了各个 AM 中去了,瓶颈也就不存在了。
开发成本
为了使用 MapReduce 框架,你需要写一个 Mapper 类,这个类要继承一些父类,然后再写一个 map 方法来做具体的数据处理。reduce 也类似。可以看到这个开发和调试成本还是不低的,尤其对于数据分析师等编程能力不那么突出的职位来说。
很自然的思路就是 SQL 化,要实现基本的数据处理,恐怕没有比 SQL 更通用的语言了。
早期对 MapReduce 的 SQL 化主要有两个框架实现。一个是 Apache Pig,一个是 Apache Hive。前者相对小众,后者是绝大部分公司的选择。
Hive 实现的基本功能就是把你的 SQL 语句解释成一个个 MapReduce 任务去执行。
比如我们现在创建这么一张测试表:
- create table test2018(id int, name string, province string);
然后通过 explain 命令来查看下面这条 select 语句的执行计划:
- explain select province, count(*) from test2018 group by province;
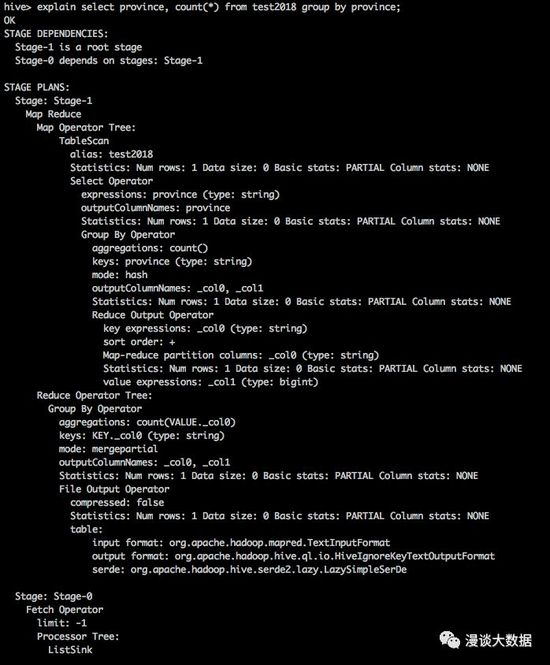
可以看到,Hive 把刚才的 SQL 语句解析成了 MapReduce 任务。这条 SQL 很简单,如果是复杂的 SQL,可能会被解析成很多个连续依赖执行的 MapReduce 任务。
另外,既然是 SQL,很自然的,Hive 还提供了库、表这类抽象,让你来更好的组织你的数据。甚至传统的数据仓库技术也能很好地以 Hive 为基础开展。这又是另一个很大的话题,这里不再展开。
计算速度
MapReduce 每个阶段的结果都需要落磁盘,然后再读出来给下一阶段处理。由于是分布式系统,所以也有很多需要网络传输数据的情况。而磁盘 IO 和网络 IO 都是非常消耗时间的操作。后者可以通过数据本地性(locality)解决 -- 把任务分配到数据所在的机器上执行,前者就很大程度地拖慢了程序执行的速度。
在这个问题上解决的比较好的是 Apache Spark。 Spark 号称基于内存的分布式计算框架,所有计算都在内存中进行,只要当内存不够时才会 spill 到磁盘。因此能尽可能地减少磁盘操作。
同时,Spark 基于 DAG(Directed Acyclic Graph)来组织执行过程,知道了整个执行步骤的先后依赖关系,也就有了优化物理执行计划的可能,很多无谓和重复的 IO 操作也就被省略了。
另外一个不得不提的点是,MapReduce 编程模型太过简单,导致很多情况下一些并不复杂的运算却需要好几个 MapReduce 任务才能完成,这也严重拖累了性能。而 Spark 提供了类型非常丰富的操作,也很大程度上提升了性能。
编程模型
上一段提到 Spark 类型丰富的操作提升了性能,另一个好处就是开发复杂度也变低了很多。相比较之下,MapReduce 编程模型的表达能力就显得非常羸弱了,毕竟很多操作硬要去套用先 map 再 reduce 会非常麻烦。
以分组求平均值为例,在 MapReduce 框架下,需要像前面说的那样写两个类,甚至有人会写成两个 MapReduce 任务。
而在 Spark 里面,只要一句 ds.groupby(key).avg() 就搞定了。 真的是没有对比就没有伤害。
九
毫无疑问,每个人都希望数据越早算出来越好,所以实时计算或者叫流计算一直是研究和使用的热点。
前面提到,Hadoop 是大数据领域的标准基础设施,提供了 HDFS 作为存储系统,以及 MapReduce 作为计算引擎,但却并没有提供对流处理的支持。因此,流处理这个领域也就出现了很多竞争者,没有形成早些年 MapReduce 那样一统江湖的局面。
这里我们简单看下目前流行度最高的三个流处理框架:Spark Streaming、Storm 和 Flink。
既然能各自鼎立天下,这些框架肯定也都各有优缺点。篇幅有限,这里我们挑选几个典型的维度来做对比。
编程范式
常规来说,可以把编程范式或者通俗点说程序的写法分为两类:命令式(Imperative)和声明式(Declarative)。前者需要一步步写清楚「怎么做」,更接近机器,后者只用写需要「做什么」,更接近人。前文提到 WordCount 的例子,MapReduce 的版本就属于命令式,Spark 的版本就属于声明式。
不难看出,命令式更繁琐但也赋予了程序员更强的控制力,声明式更简洁但也可能会失去一定的控制力。
延迟(latency)
延迟的概念很简单,就是一条数据从产生到被处理完经历的时间。注意这里的时间是实际经历的时间,而不一定是真正处理的时间。
吞吐量(throughput)
吞吐量就是单位时间内处理数据的数量。和上面的延迟一起通常被认为是流处理系统在性能上最为重要的两个指标。
下面我们就从这几个维度来看看这三个流处理框架。
Spark Streaming
Spark Streaming 和我们前面提到的用于离线批处理的 Spark 基于同样的计算引擎,本质上是所谓的 mirco-batch,只是这个 batch 可以设置的很小,也就有了近似实时的效果。
编程范式
和离线批处理的 Spark 一样,属于声明式,提供了非常丰富的操作,代码非常简洁。
延迟
由于是 micro-batch,延迟相对来一条处理一条的实时处理引擎会差一些,通常在秒级。当然可以把 batch 设的更小以减小延迟,但代价是吞吐量会降低。
由于是基于批处理做的流处理,所以就决定了 Spark Streaming 延迟再怎么调优也达不到有些场景的要求。为了解决这个问题,目前尚未正式发布的 Spark 2.3 将会支持 continuous processing,提供不逊于 native streaming 的延迟。continuous processing 顾名思义摒弃了 mirco-batch 的伪流处理,使用和 native streaming 一样的 long-running task 来处理数据。到时候将以配置的方式让用户自己选择 micro-batch 还是 continuous processing 来做流式处理。
吞吐量
由于是 micro-batch,吞吐量比严格意义上的实时处理引擎高不少。从这里也可以看到,micro-batch 是个有利有弊的选择。
Storm
Storm 的编程模型某种程度上说和 MapReduce 很像,定义了 Spout 用来处理输入,Bolt 用来做处理逻辑。多个 Spout 和 Bolt 互相连接、依赖组成 Topology。Spout 和 Bolt 都需要像 MR 那样定义一些类再实现一些具体的方法。
编程范式
很显然属于命令式。
延迟
Storm 是严格意义上的实时处理系统(native streaming),来一条数据处理一条,所以延迟很低,一般在毫秒级别。
吞吐量
同样,由于来一条数据处理一条,为了保证容错(falt tolerance) 采用了逐条消息 ACK 的方式,吞吐量相对 Spark Streaming 这样的 mirco-batch 引擎就差了不少。
需要补充说明的是,Storm 的升级版 Trident 做了非常大的改动,采用了类似 Spark Streaming 的 mirco-batch 模式,因此延迟比 Storm 高(变差了),吞吐量比 Storm 高(变好了),而编程范式也变成了开发成本更低的声明式。
Flink
Flink 其实和 Spark 一样都想做通用的计算引擎,这点上比 Storm 的野心要大。但 Flink 采用了和 Spark 完全相反的方式来支持自己本来不擅长的领域。Flink 作为 native streaming 框架,把批处理看做流处理的特殊情况来达到逻辑抽象上的统一。
- 编程范式
典型的声明式。
- 延迟
和 Storm 一样,Flink 也是来一条处理一条,保证了很低的延迟。
- 吞吐量
实时处理系统中,往往低延迟带来的就是低吞吐量(Storm),高吞吐量又会导致高延迟(Spark Streaming)。这两个性能指标也是常见的 trade-off 了,通常都需要做取舍。
但 Flink 却做到了低延迟和高吞吐兼得。关键就在于相比 Storm 每条消息都 ACK 的方式,Flink 采取了 checkpoint 的方式来容错,这样也就尽可能地减小了对吞吐量的影响。
十
到此为止,批处理和流处理我们都有了大致的了解。不同的应用场景总能二选一找到适合的方案。
然而,却也有些情况使得我们不得不在同一个业务中同时实现批处理和流处理两套方案:
- 流处理程序故障,恢复时间超过了流数据的保存时间,导致数据丢失。
- 类似多维度月活计算,精确计算需要保存所有用户 id 来做去重,由此带来的存储开销太大,因此只能使用 hyperloglog 等近似算法。
- ...
这些场景下,往往会采用流处理保证实时性,再加批处理校正来保证数据正确性。由此还专门产生了一个叫 Lambda Architecture 的架构。
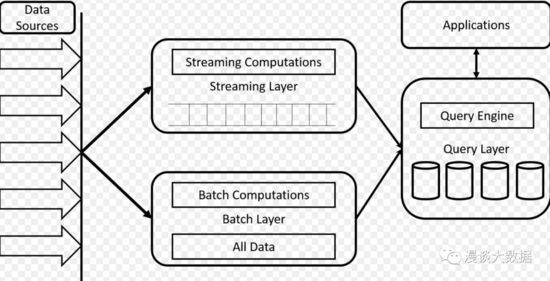
流处理层和批处理层各自独立运行输出结果,查询层根据时间选择用哪份结果展示给用户。比如最近一天用流处理的实时但不一定精确的结果,超过一天就用批处理不实时但精确的结果。
Lambda Architecture 确实能解决问题,但流处理和批处理两套程序,再加上顶在前面的查询服务,带来的开发和维护成本也不小。
因此,近年来也有人提出了 Kappa Architecture,带来了另一种统一的思路,但也有明显的缺点。限于篇幅这里不再赘述。
十一
计算框架是大数据领域竞争最激烈的方向之一,除了前面提到的方案,还有 Impla、Tez、 Presto、Samza 等等。很多公司都喜欢造轮子,并且都声称自己的轮子比别人的好。而从各个框架的发展历程来看,又有很明显的互相借鉴的意思。
在众多选择中,Spark 作为通用型分布式计算框架的野心和能力已经得到充分的展示和证实,并且仍然在快速地进化: Spark SQL 支持了类 Hive 的纯 SQL 数据处理,Spark Streaming 支持了实时计算,Spark MLlib 支持了机器学习,Spark GraphX 支持了图计算。而流处理和批处理底层执行引擎的统一,也让 Spark 在 Lambda Architecture 下的开发和维护成本低到可以接受。
所以,出于技术风险、使用和维护成本的考虑,Spark 是我们做大数据计算的首选。当然,如果有些实际应用场景 Spark 不能很好的满足,也可以选择其他计算框架作为补充。比如如果对延迟(latency) 非常敏感,那 Storm 和 Flink 就值得考虑了。
十二
如开篇所说,大数据是个非常广的领域,初学者很容易迷失。希望通过这篇文章,能让大家对大数据的基础有个大概的了解。限于篇幅,很多概念和技术都点到即止,有兴趣的同学可以再扩展去学习。相信,打好了这个基础,再去学大数据领域的其他技术也会轻松一些。

